
Abstract
The recently discovered variational PDEs (partial differential equations) for finding missing boundary conditions in Hamilton equations of optimal control are applied to the extended-space transformation of time-variant linear-quadratic regulator (LQR) problems. These problems become autonomous but with nonlinear dynamics and costs. The numerical solutions to the PDEs are checked against the analytical solutions to the original LQR problem. This is the first validation of the PDEs in the literature for a nonlinear context. It is also found that the initial value of the Riccati matrix can be obtained from the spatial derivative of the Hamiltonian flow, which satisfies the variational equation. This last result has practical implications when implementing two-degrees-of freedom control strategies for nonlinear systems with generalized costs.
optimal control; nonlinear systems; Riccati equations; Hamiltonian equations; first-order PDEs
Initial values for Riccati ODEs from variational PDEs
Vicente Costanza* * Corresponding author ; Pablo S. Rivadeneira
Grupo de Sistemas No Lineales, INTEC, CONICET-UNL, Santa Fe, Argentina E-mails: tsinoli@santafe-conicet.gov.ar / psrivade@santafe-conicet.gov.ar
ABSTRACT
The recently discovered variational PDEs (partial differential equations) for finding missing boundary conditions in Hamilton equations of optimal control are applied to the extended-space transformation of time-variant linear-quadratic regulator (LQR) problems. These problems become autonomous but with nonlinear dynamics and costs. The numerical solutions to the PDEs are checked against the analytical solutions to the original LQR problem. This is the first validation of the PDEs in the literature for a nonlinear context. It is also found that the initial value of the Riccati matrix can be obtained from the spatial derivative of the Hamiltonian flow, which satisfies the variational equation. This last result has practical implications when implementing two-degrees-of freedom control strategies for nonlinear systems with generalized costs.
Mathematical subject classification: Primary: 93C10; Secondary: 49N10.
Key words: optimal control, nonlinear systems, Riccati equations, Hamiltonian equations, first-order PDEs.
1 Introduction
Hamilton's canonical equations (HCEs) appear naturally in optimal control when sufficient convexity is present. If the problem concerning an n-dimensional control system and an additive cost objective is regular, i.e. when the Hamiltonian H(t, x,λ, u) of the problem is smooth enough and can be uniquely optimized with respect to u at a control value u0 (t, x, λ) (depending on the remaining variables), then HCEs appear as a set of 2n ordinary differential equations (ODEs) whose solutions are the optimal state-costate time-trajectories.
In the general nonlinear finite-horizon optimization set-up, allowing for a free final state, the cost penalty K (x) imposed on the final deviation generates a two-point boundary-value situation. This is often a rather difficult numerical problem to solve. However, in the linear-quadratic regulator (LQR) case, there exist well-known methods (see for instance [2], [12]) to transform the boundary-value into a final-value problem, related to the ordinary differential Riccati equation (DRE).
The same question in the one-dimensional case and for a quadratic K (x) has been imbedded into a whole (T, s)-family of problems (see [4], [5], [9]), generating two first-order, quasilinear, uncoupled PDEs with classical initial conditions, where the dependent variables are the missing boundary conditions ρ  x(T) and σ λ(0) of the HCEs. This 'imbedding' approach is completely disjoint from Riccati equations, but more in the line of the early ideas introduced by Bellman [1]. An analogous approach was reformulated for the multidimensional case, in the light of the symplectic properties inherent to Hamiltonian dynamics [5]. The variational and related PDEs were solved numerically for linear, bilinear, and other nonlinear systems, but their complexity has impeded analytical confirmation till now. In this article, such an analytical check is developed for a well-known case-study, namely the time-variant LQR problem, looked at as a nonlinear system with a nonlinear Lagrangian.
x(T) and σ λ(0) of the HCEs. This 'imbedding' approach is completely disjoint from Riccati equations, but more in the line of the early ideas introduced by Bellman [1]. An analogous approach was reformulated for the multidimensional case, in the light of the symplectic properties inherent to Hamiltonian dynamics [5]. The variational and related PDEs were solved numerically for linear, bilinear, and other nonlinear systems, but their complexity has impeded analytical confirmation till now. In this article, such an analytical check is developed for a well-known case-study, namely the time-variant LQR problem, looked at as a nonlinear system with a nonlinear Lagrangian.
It is also known [6] that, in the general nonlinear case, the initial value 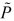 (0) of the solution to the DRE associated with the linearization of the HCEs can be recovered from the variational PDEs. This is of particular importance in implementing two-degrees-of-freedom (2DOF) control in the Hamiltonian context, because the (t) enters the compensation gain, and it can be obtained on-line from knowledge of (0). For a time-variant LQR problem, regarded as the combination of a nonlinear system (by considering the time t as an extra state-variable) and a nonlinear cost, it is analytically checked that this (t) is essentially the same than the solution P(t) of the DRE of the original (maintaining t as the independent variable) version. Since the (t) is calculated from (0), and this from the variational PDEs, the analytical coincidence alluded above serves as the first validation of the PDEs in a nonlinear context known in the literature so far.
(0) of the solution to the DRE associated with the linearization of the HCEs can be recovered from the variational PDEs. This is of particular importance in implementing two-degrees-of-freedom (2DOF) control in the Hamiltonian context, because the (t) enters the compensation gain, and it can be obtained on-line from knowledge of (0). For a time-variant LQR problem, regarded as the combination of a nonlinear system (by considering the time t as an extra state-variable) and a nonlinear cost, it is analytically checked that this (t) is essentially the same than the solution P(t) of the DRE of the original (maintaining t as the independent variable) version. Since the (t) is calculated from (0), and this from the variational PDEs, the analytical coincidence alluded above serves as the first validation of the PDEs in a nonlinear context known in the literature so far.
The paper is organized as follows: after the Introduction, in Section 2 the elements related to the time-variant LQR problem are introduced, and in Section 3 two treatments of the autonomous and nonlinear version of the problem are developed: (i) through the Hamiltonian Canonical Equations (HCEs), and (ii) by solving the variational and related PDEs. Afterwards, the comparison among numerical and analytical results is discussed. The Section 4 shows that the Riccati matrices appearing in the time-variant and the autonomous versions of the LQR problem are essentially the same. Section 5 is devoted to show the importance of having the initial value of the Riccati matrix in constructing 2DOF control strategies for nonlinear systems subject to arbitrary Lagrangians. As usual, a final Section summarizes the conclusions and perspectives.
2 Classical treatment of time-variant LQR problems
The optimal control problems treated here will concern time-variant controllable linear systems

coupled to a cost functional of the form

with a quadratic Lagrangian L and symmetric coefficient matrices of appropriate order

The optimal control solution to this problem in the set of admissible control trajectories  [0, T] can be expressed (see [12]) in feedback form as
[0, T] can be expressed (see [12]) in feedback form as

where x*(t) denotes the optimal state trajectory, and P(t) is the solution to the Riccati Differential Equation (DRE)

with a final boundary condition

and W(t) B(t)R-1(t)B'(t). The value (or Bellman) function

satisfies the Hamilton-Jacobi-Bellman (HJB) equation and boundary condition

where H0 is the minimized Hamiltonian defined as

H is the usual Hamiltonian of the problem, namely

and u0 is the unique H-minimal control satisfying (since the problem is assumed to be regular)

It is also known that the solution to the HJB equation is in this case (see [2])

and then the optimal costate variable λ* results in

Therefore, from [5]-[6] the optimal state and costate trajectories are solutions to the following Hamiltonian Canonical Equations (HCEs)

which in concise form read as one 2n-dimensional linear time-variant equation

where

with mixed boundary conditions

For further details concerning the solution to this problem see for instance [2] and [12].
3 Transformation of the time-variant LQR problem into an autonomous problem
3.1 Analytical solution of Hamilton's equations for a case-study
The procedure for transforming the time-variant LQR problem into an autonomous one is standard. An analytically solvable simple illustrative example will be treated, with A(t) = -1, B(t) = e-t, Q(t) = 0, R(t) = 1, s > 0. The relevant components of the problem will then be

Notice that here the Lagrangian is autonomous, although this is not essential at this point. For this example the unknown variable of the corresponding DRE in Eq. (7) can be found analytically, namely

and so the LQR problem is completely solved. However, for the purposes of this article the problem will be transformed into an autonomous one through the usual change of variables

and for simplicity the old symbol x will be maintained for the new state, i.e., in what follows,

and therefore, in the new set-up the (autonomous) dynamics reads

and the transformed cost functional, Lagrangian, and final penalty are

It is clear that the optimal control for both problems (the time-variant and the autonomous one) will be the same, since

However, the new dynamics becomes nonlinear (actually, Eq. (28) having an exponential, implies that all powers of x1 are present, and they are multiplied by the control). New expressions for the Hamiltonian Ha, the Ha-minimal control  , and the minimized (or control) Hamiltonian
, and the minimized (or control) Hamiltonian  will apply, namely
will apply, namely


and the HCEs for this case will be, in component-by-component form,

These ODEs can be solved analytically, and their solutions result in

It can be easily checked that the optimal control for the original problem, calculated from Eqs. (6, 24), is the same that the one obtained from Eqs. (35, 42-44).
3.2 Variational PDEs for missing boundary conditions
The autonomous nonlinear problem posed by Eqs. (27-32) will be now treated from the 'invariant-imbedding' approach and its solution compared against the one analytically obtained in the previous subsection. The following notation for the missing boundary conditions will be used in this subsection

The introduction of the variational PDEs is done through the following objects. First of all  will denote the flow of the Hamiltonian equations (37-40), i.e.
will denote the flow of the Hamiltonian equations (37-40), i.e.

and Φt is the t-advance map defined for each t as:  . The flow must verify the ODEs of Hamiltonian dynamics, i.e.:
. The flow must verify the ODEs of Hamiltonian dynamics, i.e.:

where X is the Hamiltonian vector field corresponding to the optimal control problem with dynamics defined by fa and Lagrangian La, i.e.

Let us denote then, for the variables t, s, x, λ in their corresponding domains of definition,

It can be shown, by deriving spatially (with respect to (x, λ)) the ODE condition in Eq. (47), that the following 'variational equation' (see [11]) applies:

where  and V(t, s) stands for
and V(t, s) stands for  (t, s). For the example under study, some of the previously defined objects read then
(t, s). For the example under study, some of the previously defined objects read then


Then, for this case, the linear time-variant variational equation (50) can be integrated analytically, and its solution results in

Now it should be noted from (50) that V is the fundamental matrix Φ (t,0) of the linear system (s is fixed)

in particular y(t) = Φ(t, τ)y(τ), Φ(τ, τ) = I, and it can be shown (see [12]) that (by abuse of notation) V(T, s) = Φ(T, 0) verifies

This is the Variational Riccati Equation (VRE), its name coming from dynamical systems and control theory (see [11]-[12]). It should be noted that

and therefore in general it must be solved in parallel to an appropriate equation for ρ(T, s). It turns out that several equivalent equations may play this role (see [5] for more details), for instance the pair (which also involves σ(T, s))

where the Vi, i = 1, ... 4 are the partitions into n x n submatrices of

and

Just for illustration these PDEs (55, 57, 58) are solved numerically, and their solutions compared against the following analytical expressions obtained from definition (45) and Eqs. (42-44):

The first component of ρ, σ, obtained by solving simultaneously equations (55, 57 and 58) with Mathematica® are plotted in Figures 1 and 2, respectively. The numerical solution error with respect to the analytical solutions (61, 63) is negligible, as can be observed for instance in Figure 3.
4 Riccati matrices for the time-variant and the autonomous versions of LQR problems
For the transformed system in Eqs. (37, 40), the matrix

and its partitions result in the following expressions:

The linear system in Eq. (19), given the Hamiltonian structure of the matrix in Eq. (65), has a solution v(t) = (x(t), λ(t)' verifying

provided
(t) is a 2 x 2 matrix solution to the Riccati matrix ODE

Assuming the matrix V = V(T, s) = Φ(T, 0) is known, and introducing the two auxiliary matrices α,β

then it follows that, for any initial condition x0, the following identities apply:

and therefore the initial value (0) can be recovered from the solutions to the PDEs, namely

The Riccati matrix
(t) alluded to in Eq. (68) should be closely related to the scalar function P (t) given in Eq. (24), since both(t) and P (t) come from essentially the same problem. The analytical confirmation of this assertion follows: (i) at the initial time t = 0, since

then, from Eq. (73),

and (ii) for time t ∈ (0, T], by partitioning Eq. (69),

so
11 verifies the same ODE and final condition as P does.By uniqueness of solutions:  .
.
5 Relevance for two-degrees-of-freedom control
Two-degrees-of-freedom (2DOF) is a generic denomination for control schemes attempting: (i) to generate a reference/desired state trajectory for the system, and (ii) to track/compensate this trajectory in the presence of disturbances. Within this context, 'optimal' will be used to mean that there exists an underlying optimal control problem for a smooth nonlinear autonomous control system whose dynamics and output are modelled by

subject to a general (as in Eq. (2) but with a not necessarily quadratic Lagran-gian L) objective functional. When this problem is regular, the Hamiltonian formalism applies as in the LQR problem above, and the Hamiltonian dynamics are expressed as in Eqs. (37, 40, 51). It also can be shown [3] that the deviations  from the optimal trajectories follow approximately the dynamics
from the optimal trajectories follow approximately the dynamics

where the matrix coefficients take the form (see for instance [3])

all partial derivatives evaluated at the optimal values x*(t), λ*(t), u*(t). Notice that the dynamics inEq. (78) has the same (Hamiltonian) structure (see [2], [12]) than that of equations (19-20) for an LQR problem. The solution of equation (78) (denoted also  for simplicity) will then verify
for simplicity) will then verify  , with Pc(t) being a solution to the final-value problem:
, with Pc(t) being a solution to the final-value problem:

It is also known ([3], [6]) that the appropriate control for compensation is

where x is the Kalman estimate of deviations  obtained by filtering the output deviation y - Cx*. Therefore it is essential to have Pc(t) on-line when applying 2DOF control, and this is possible when Pc(0) is known and the DRE is integrated in parallel with the model of the process. Now, it can be easily checked ([3], [6]) that
obtained by filtering the output deviation y - Cx*. Therefore it is essential to have Pc(t) on-line when applying 2DOF control, and this is possible when Pc(0) is known and the DRE is integrated in parallel with the model of the process. Now, it can be easily checked ([3], [6]) that

where Xc is the Hamiltonian vector field corresponding to f, L. Then, by denoting A(t, s) = Hc(t), and recalling the definition for V in equation (49) for the flow Φ corresponding to the vector field Xc, equations (50, 72) remain valid for the appropriate objects, i.e.:

where α, β are as in equation (70). It follows that, whenever the variational PDEs (55, 57 and 58) are solved, the value of

becomes available, and then the matrix Pc (t) (needed in the compensation and the filtering stages of 2DOF control) can be calculated on-line by integrating the Riccati equation (80) as an initial-value problem.
6 Conclusions
The variational PDEs associated with the Hamiltonian formulation of the optimal control problem for nonlinear systems have been validated when applied to the usual time-variant LQR problem posed in extended state space (including time as a new variable). The result has been checked analytically and numerically for a scalar final penalization matrix, although the possibility of treating general nonnegative-definite quadratic forms can be pursued along the lines of the linear time-constant case (see [7], [8], [10]).
The new approach to recover missing boundary conditions of Hamilton's equations by solving quasilinear first-order PDEs has proven to be useful in calculating the initial value of the solution to Riccati equations underlying the linearization of the HCEs. This has a considerable practical value when instrumenting 2DOF control strategies, since the solution of such Riccati equations appear into the gain of the compensation stage, and they can be computed online if treated as initial-value instead of classical final-value ODEs.
Received: 04/II/10.
Accepted: 21/VI/10.
#CAM-185/10.
- [1] R. Bellman and R. Kalaba, A note on Hamilton's equations and invariant imbedding. Quarterly of Applied Mathematics, XXI (1963), 166-168.
- [2] P. Bernhard, Introducción a la Teoria de Control Optimo. Instituto de Matemática "Beppo Levi", Cuaderno Nro. 4, Rosario, Argentina (1972).
- [3] A. Bryson and Y. Ho, Applied Optimal Control. John Wiley and Sons, New York, revised printing edition (1975).
- [4] V. Costanza, Finding initial costates in finite-horizon nonlinear-quadratic optimal control problems. Optimal Control Applications and Methods, 29 (2008a), 225242.
- [5] V. Costanza, Regular optimal control problems with quadratic final penalties. Revista de la Unión Matemática Argentina, 49(1) (2008b), 43-56.
- [6] V. Costanza, Optimal two-degrees-of-freedom control of nonlinear systems. Latin American Applied Research, in press (2011).
- [7] V. Costanza and C.E. Neuman, Partial differential equations for missing boundary conditions in the linear-quadratic optimal control problem. Latin American Applied Research, 39(3) (2009), 207-212.
- [8] V. Costanza and P.S. Rivadeneira, Feedbackóptimo delproblema linealcuadrático invariante con condiciones flexibles. Proceedings of the XXI Congreso Argentino de Control Automático, Buenos Aires-Argentina, paper A001, Sept (2008).
- [9] V. Costanza and P.S. Rivadeneira, Finite-horizon dynamic optimization of nonlinear systems in real time. Automatica, 44(9) (2008), 2427-2434.
- [10] V. Costanza, P.S. Rivadeneira and R.D. Spies, Equations for the missing boundary values in the hamiltonian formulation of optimal control problems. Journal of Optimization Theory and Applications, 149 (2011), 26-46.
- [11] M.W. Hirsch and S. Smale, Differential Equations, Dynamical Systems, and Linear Algebra. Academic Press, New York (1974).
- [12] E.D. Sontag, Mathematical Control Theory. Springer, New York, second edition (1998).
Publication Dates
-
Publication in this collection
27 July 2011 -
Date of issue
2011
History
-
Received
04 Feb 2010 -
Accepted
21 June 2010



