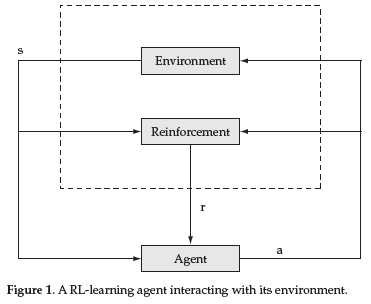
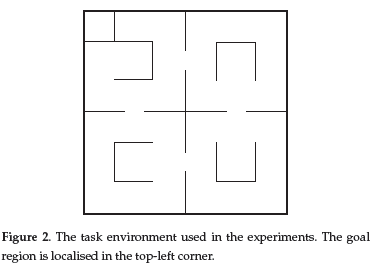
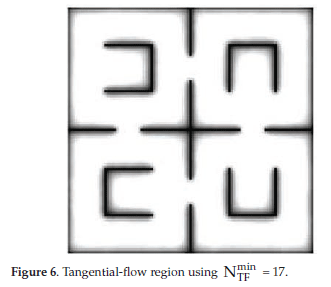
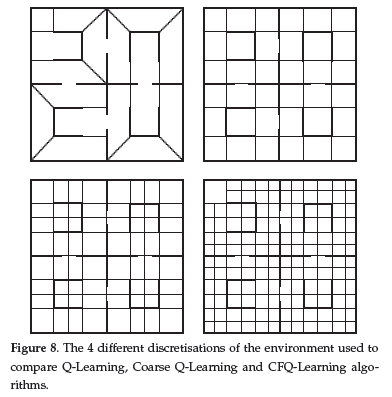
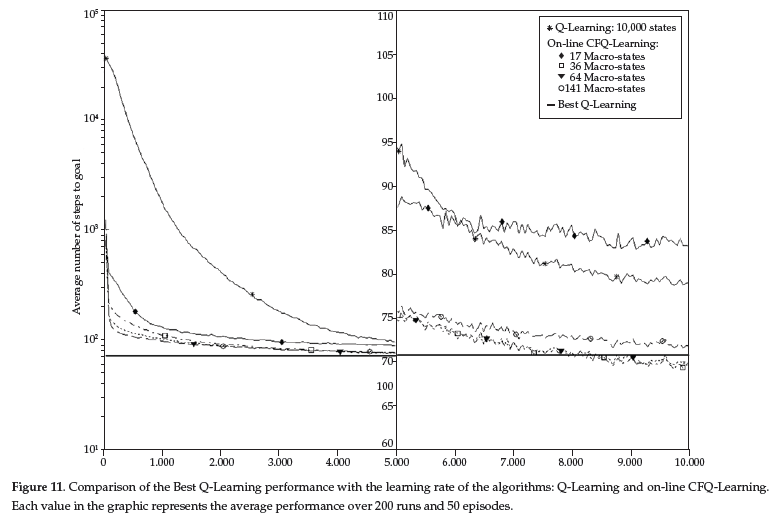
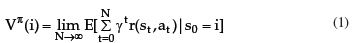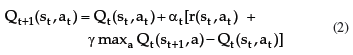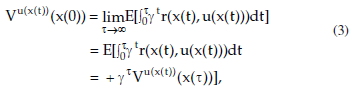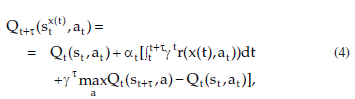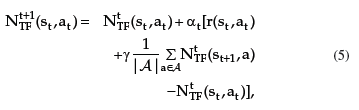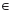Reinforcement Learning is carried out on-line, through trial-and-error interactions of the agent with the environment, which can be very time consuming when considering robots. In this paper we contribute a new learning algorithm, CFQ-Learning, which uses macro-states, a low-resolution discretisation of the state space, and a partial-policy to get around obstacles, both of them based on the complexity of the environment structure. The use of macro-states avoids convergence of algorithms, but can accelerate the learning process. In the other hand, partial-policies can guarantee that an agent fulfils its task, even through macro-state. Experiments show that the CFQ-Learning performs a good balance between policy quality and learning rate.
machine learning; reinforcement learning; abstraction; partial-policy; macro-states