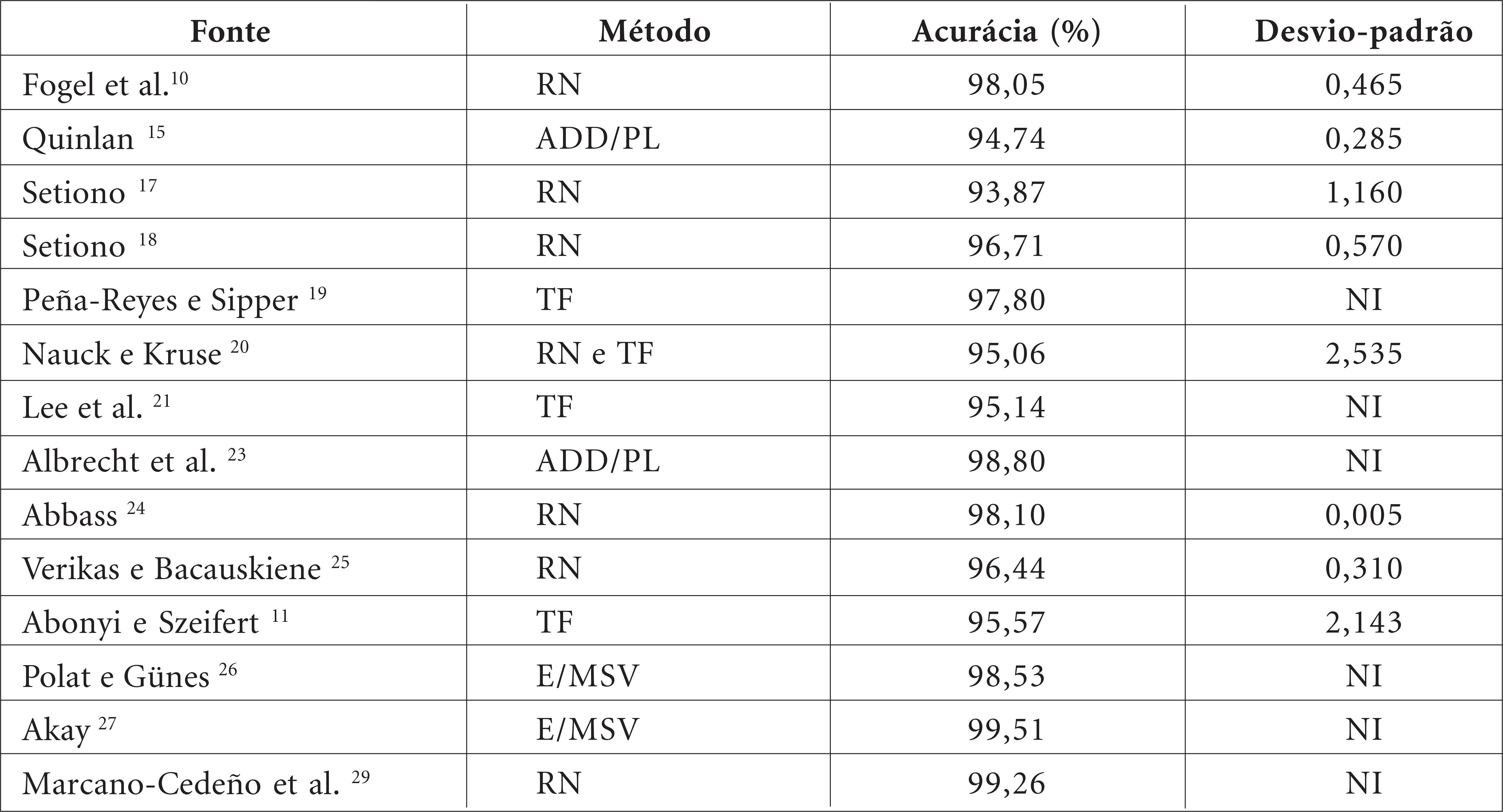
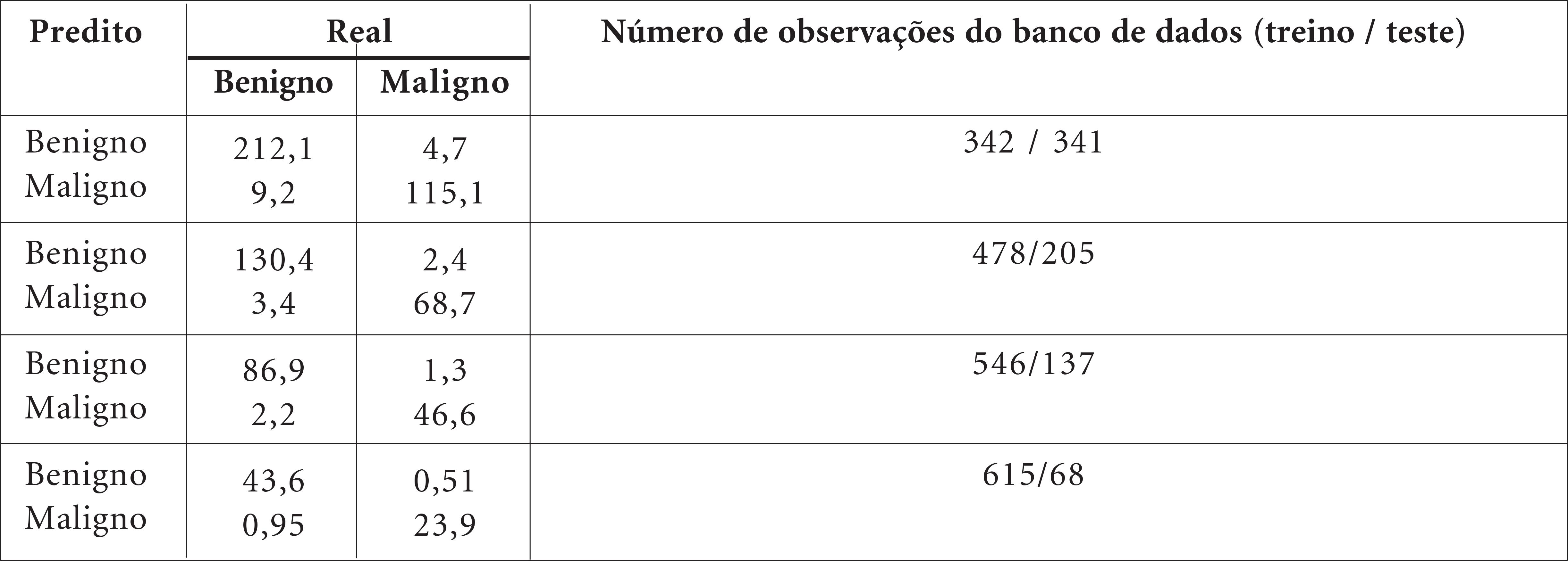
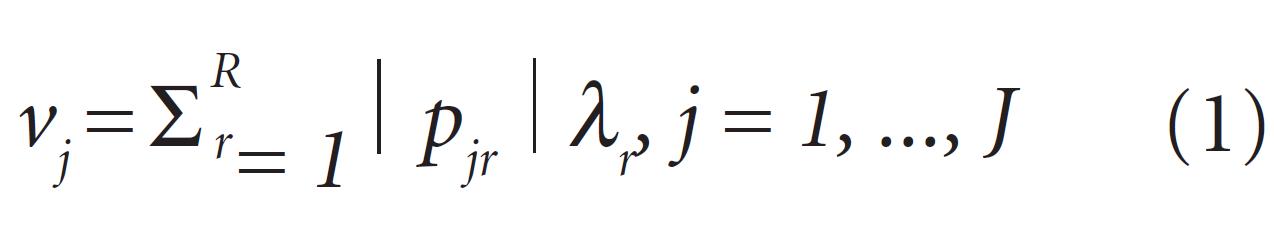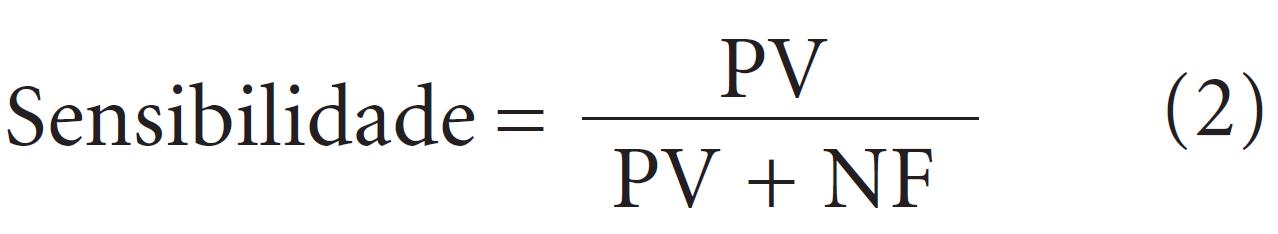Na maioria dos países, o câncer de mama entre as mulheres é predominante. Se diagnosticado precocemente, apresenta alta probabilidade de cura. Diversas abordagens baseadas em Estatística foram desenvolvidas para auxiliar na sua detecção precoce. Este artigo apresenta um método para a seleção de variáveis para classificação dos casos em duas classes de resultado, benigno ou maligno, baseado na análise citopatológica de amostras de célula da mama de pacientes. As variáveis são ordenadas de acordo com um novo índice de importância de variáveis que combina os pesos de importância da Análise de Componentes Principais e a variância explicada a partir de cada componente retido. Observações da amostra de treino são categorizadas em duas classes através das ferramentas k-vizinhos mais próximos e Análise Discriminante, seguida pela eliminação da variável com o menor índice de importância. Usa-se o subconjunto com a máxima acurácia para classificar as observações na amostra de teste. Aplicando ao Wisconsin Breast Cancer Database, o método proposto apresentou uma média de 97,77% de acurácia de classificação, retendo uma média de 5,8 variáveis.
Seleção de variáveis; Identificação de câncer de mama; k-vizinhos mais próximos; Análise Discriminante