Abstract
Abstract: In this paper, we revisit the Wilson-Hilferty distribution and presented its mathematical properties such as the r-th moments and reliability properties. The parameters estimators are discussed using objective reference Bayesian analysis for both complete and censored data where the resulting marginal posterior intervals have accurate frequentist coverage. A simulation study is presented to compare the performance of the proposed estimators with the frequentist approach where it is observed a clear advantage for the Bayesian method. Finally, the proposed methodology is illustrated on three real datasets.
Key words
Bayesian analysis; Bayesian prediction; censored data; objective prior; Wilson-Hilferty distribution.
1 - INTRODUCTION
In this paper, we revisit the Wilson-Hilferty (WH) distribution, showing that this distribution is appropriate for modeling data with increasing and bathtub hazard rates. This model takes the name of a fundamental statistical technique given by Wilson and Hilferty (1931)WILSON EB and HILFERTY MM. 1931. The distribution of chi-square. Proc Natl Acad Sci 17(12): 684-688., the so-called Wilson-Hilferty transformation. This procedure gives a normal approximation to the cube root of a chi-squared variable, and it is essential for a wide range of scientific processes. Ishikawa et al. (2014)ISHIKAWA T, TOTANI T, NISHIMICHI T, TAKAHASHI R, YOSHIDA N and TONEGAWA M. 2014. On the systematic errors of cosmological-scale gravity tests using redshift-space distortion: non-linear effects and the halo bias. Mon Notices Royal Astron Soc 443(4): 3359-3367. considered such transformation to improve the accuracy of likelihood analysis in the cases where only a small number of modes are available in power spectrum measurements. Zemzami and Benaabidate (2016)ZEMZAMI M and BENAABIDATE L. 2016. Improvement of artificial neural networks to predict daily streamflow in a semi-arid area. Hydrol Sci J 61(10): 1801-1812. considered the WH transformation to reduces the effect of local variations in artificial neural networks. Here, we are not introducing a new distribution but providing common mathematical functions and inferential procedures related to this vital model to be used in different frameworks.
For the WH distribution a critical reparametrization is presented. This approach returns a simple probability density function (PDF) where its parameters are orthogonal in the sense discussed by Cox and Reid (1987)COX DR and REID N. 1987. Parameter orthogonality and approximate conditional inference. J Royal Stat Society Series B 49(1): 1-18.. Besides, we considered the presence of randomly censored data, since it has received particular attention in medical experiments and industrial lifetime testing. To the best of our knowledge, there is no evidence of the use of the WH distribution to describe time-to-event data and reliability applications so far. Therefore, these results are useful contributions to be used by reliability engineers and practitioners of statistical analysis of lifetime data in general.
Due to the limited number of data that are usually observed in reliability application, we consider an objective Bayesian analysis to achieve inference that does not depend on asymptotic results such as the frequentist inference. In this case, a Bayesian approach using an overall reference prior is presented. It is proved that such prior is also a matching prior, i.e., the resulting marginal posterior intervals have accurate frequentist coverage (Tibshirani 1989TIBSHIRANI R. 1989. Noninformative priors for one parameter of many. Biometrika 76(3): 604-608.). Moreover, the resulting posterior is proper and has interesting properties, such as one-to-one invariance, consistent marginalization, and consistent sampling properties.
Moreover, we also propose efficient closed-form maximum a posteriori probability (MAP) estimators for both parameters in the case of complete data, which is essential for practical purposes, since they can be applied for real-time computing estimators in embedded technology. An intensive simulation study is presented to show the usefulness of the Bayesian approach. Finally, a Bayes prediction of the future failure time is presented based on observed order statistics. These results are applied in three lifetime data to demonstrate how the WH distribution can be applied in real situations.
The remainder of this study is organized as follows. Section 2 presents some mathematical properties of the WH distribution. In Section 3, we present the parameter estimates for the model based on Maximum Likelihood Estimator (MLE) for complete and censored data. Section 4 presents the Bayesian estimators for the distribution. Section 5 is devoted to present simulation studies to compare the performance of the estimators. The predictive modeling for the WH distribution is discussed in Section 6. In Section 7, we prove the relevance of the distribution by considering three real lifetime datasets. Finally, Section 8 summarizes the present study.
2 - WILSON-HILFERTY DISTRIBUTION
Let be a non-negative random variable with WH distribution, then its PDF is
where and are shape and scale parameters, respectively, and , hereafter, we will assume that represents these parameters. This model is a particular case of a three-parameter generalized gamma (GG) distribution proposed by Stacy (1962)STACY EW. 1962. A generalization of the gamma distribution. Ann Math Stat, p. 1187-1192. (replacing 3 by in equation (1)) that unifies the WH distribution with other important models such as, Weibull distribution, gamma, Nakagami, and the lognormal distribution, to list a few.
The cumulative function of is given by
where is known as the lower incomplete gamma function.
The raw moments of the model are given as
which can also be obtained using a reparametrization in the r-moment of the GG distribution given in Khodabin and Ahmadabadi (2010)KHODABIN M and AHMADABADI A. 2010. Some properties of generalized gamma distribution. Math Sci 4(1): 9-28.. Hence, the mean and variance of (1) are, respectively, given by
2.1 - QUANTITATIVE METHODS FOR THE RELIABILITY
Throughout this subsection, we present some crucial measures in many areas of science, mainly in reliability engineering. Such quantitative measures for the reliability are: Reliability Function, Failure Rate Function and Mean Residual Life.
2.1.1 - Reliability function and hazard rate function
The reliability function of an observational unity is given by
where is known as the upper incomplete gamma function. In general applications, means the probability that an observation does not fail in the time interval .
When exists, the hazard function of a component is obtained by considering . So, for the WH distribution, the hazard function is given by
A considerable attribute of the function (5) is that it presents three distinct phases, i.e., decreases first, then remains roughly constant and ultimately increases. This result is proved in Theorem 2.1.
Theorem 2.1. For the WH distribution the hazard function is bathtub (increasing) shaped for , for all .
Proof. Consider that
Note that for and , has a decreasing behavior, then from Lemma 2.1.2 presented in Ramos et al. (2018)RAMOS PL, LOUZADA F and RAMOS E. 2018. Posterior properties of the nakagami-m distribution using noninformative priors and applications in reliability. IEEE Trans Rel 67(1): 105-117., is increasing. On the other hand, for and , we have that has bathtub shape property with a global minimum at . Hence, is also bathtub shaped.
The behavior of the hazard function (5) when and is given, respectively, by
2.1.2 - Mean residual life function
The mean residual life (MRL) is an essential measure in reliability and survival analysis applications and represents the expected additional lifetime given that a component has survived until time \(t\) , i.e., it summarizes the entire remaining life from components or systems. This measure gives substantial information for maintenance strategies involving repair and replacement.
Proposition 2.2. The mean residual life function of the WH distribution is given by
The behaviors of the MRL function in (7) when and are, respectively
Theorem 2.3. The MRL function of the WH distribution has either a unimodal or decreasing shape when , or , respectively, for all .
Proof. If and , we have that is increasing. In this case, using the Lemma II.4 presented by Ramos et al. (2018), is decreasing. Now, if and , then has a bathtub shape and since , from the same Lemma II.4 used above, we have that has a unimodal shape property.
Figure 1 presents different shapes of the hazard and the mean residual life function. The hazard function is characterized by three distinct regions according to a bathtub curve of the hazard rate. The assessment of the impact of each region it is essential to improve the reliability of the components and systems by preventive maintenance or to eliminate early-life failures.

Hazard and mean residual life function shapes for WH distribution considering different values of and .
3 - CLASSICAL INFERENCE
3.1 - COMPLETE DATA
In this section, we use the maximum likelihood method to obtain the classical estimators of the unknown parameters of the WH distribution which may be obtained by direct maximization of the likelihood function. Let be a random sample such that , then, the likelihood function from (1) is given by
The estimates are obtained by maximizing the likelihood function. From the expressions and , the likelihood equations are given by
and
where is the digamma function. The MLE of is given by
Substituting in (9), the MLE of can be obtained by solving
Theorem 3.1. Suppose that is the MLE of . Hence, the root of , , is unique.
Proof. Since is strictly monotone and continuous with range in , we have that for there is a unique solution in
and the proof is completed.
The MLEs are asymptotically normally distributed with a bivariate normal distribution given by
where is the Fisher information matrix
and is the trigamma function. These results are useful to construct asymptotic confidence intervals for the parameters of the WH distribution.
3.2 - CENSORED DATA
A fundamental problem that one meets with lifetime data is that available data are a mixture of complete and incomplete observations due to many reasons. The case most easily encountered of incompleteness is random censoring (for more details see Lawless 2011LAWLESS JF. 2011. Statistical models and methods for lifetime data. Volume 362, J Wiley \& Sons.). In this type of censoring there are the follow random variables, the lifetime related to th individual and the censoring time , such that data observed are , where and the censoring indicator , resulting 1 if the lifetime is observed and 0 otherwise. This type of censoring has as special cases the type I and II censoring mechanisms. We assume that the random censoring times s are independent of s. In this case, the likelihood function for is given by .
Letting the failure times be a random sample of WH distribution, the likelihood function considering data with random censoring is given by
where . The logarithm of the likelihood function (14) is given by
From and , the likelihood equations are given as follows
where can be computed numerically. Numerical methods are required to find the solution of these non-linear equations.
4 - BAYESIAN INFERENCE
In this section, we considered a Bayesian approach to obtain the parameter estimators of the WH distribution. Our interest is to find accurate estimates and prediction (condition/performance in the future). These problems are often challenging to deal with when using classical inference methods. In particular, our setting presents many interest quantities, and we are simultaneously interested in all the parameters of the model and several functions of them.
One may consider the Jeffreys prior, which is obtained by taking the square root from the determinant of the Fisher information matrix in (13), i.e.,
On the other hand, the Jeffreys prior may not be a good choice in the multiparametric case Bernardo (2005)BERNARDO JM. 2005. Reference analysis. Handbook of Statistics 25: 17-90.. Moreover, as it will be discussed further, this prior is not a matching prior for both parameters, i.e., the marginal posterior intervals have not accurate frequentist coverage in a sense discussed by Tibshirani (1989). Another well-known class of non-informative priors is then considered, the so-called reference priors Bernardo (1979)BERNARDO JM. 1979. Reference posterior distributions for bayesian inference. J Royal Stat Soc Series B, p. 113-147.. The main idea for obtaining such prior is to maximize the expected Kullback-Leibler divergence between the posterior distribution and the prior distribution. The obtained reference prior provides posterior distributions with interesting properties such as invariance, consistency under marginalization and consistent sampling properties.
In cases where the Fisher information matrix has orthogonal parameters, the following Lemma (see Berger et al. 2015) can be used to easily obtain a one-at-a-time reference prior for any chosen parameter of interest and any ordering of the nuisance parameters in the derivation (hereafter referred to as overall reference prior).
Lemma 4.1. Berger et al. (2015)BERGER JO et al. 2015. Overall objective priors. Bayesian Anal 10(1): 189-221.. Considering the unknown parameters and the posterior distribution p which is asymptotically normally distributed with dispersion matrix . If is of the form
where and are positive functions of for \(i=1,2\) , then the overall reference prior is given by
Consider the posterior distribution with dispersion matrix is given by
Since are constant terms supose that . Then, we have that
The posterior above has the same form of the posterior distribution of the gamma model reparametrized by its mean. Crain and Morgan (1975)CRAIN BR and MORGAN RL. 1975. Asymptotic normality of the posterior distribution for exponential models. Ann Stat, p. 223-227. proved that for the exponential family the posterior distribution tends asymptotically to the multivariate normal. Since our model is included in this case, Lemma 4.1 can be used to derive the overall referente prior.
The overall reference prior for the WH distribution is given by
An interesting aspect of this overall reference prior is that such prior satisfies the solutions of both partial differential equations
where , are the elements of the Fisher information matrix given in (13). This implies that the credible interval for has a coverage error \(O\) ( \(n^{-1}\) ) in the frequentist sense, i.e.,
where refers to the th quantile of the posterior distribution of . It is important to point out that the Jeffreys prior only satisfies the second partial differential, therefore, such prior is not a matching prior for both parameters, which is undesirable.
4.1 - COMPLETE DATA
The joint posterior distribution for and , produced by the overall reference prior is proportional to the product of the likelihood function (8) and the prior distribution (19), resulting in
The normalizing constant is given by
and is the parameter space for . The posterior distribution (20) will be proper if and only if .
Theorem 4.2. The posterior distribution (20) is proper if and only if .
Proof. Since , by Tonelli theorem (see Folland 1999) we haveFOLLAND GB. 1999. Real analysis: modern techniques and their applications. Wiley, New York, 2nd edition.
where
and
Ramos et al. (2018) already proved in the context of the Nakagami-m distribution that
for and for any \(c>0\) . Therefore, we have that
and
where and by the inequality of the arithmetic and geometric means. Finally, we obtain .
The marginal posterior distribution for is given by
The conditional posterior distribution for is given by
where IG denotes the inverse gamma distribution with PDF and shape parameter and scale parameter .
4.2 - MAXIMUM A POSTERIORI PROBABILITY (MAP) ESTIMATORS
Firstly, we considered the Bayesian approach to derive efficient closed-form estimators for parameters of the generalized gamma distribution when one of the parameters is known. Let follows a GG distribution with and parameters, then, the likelihood function is given by
Although different objective priors could be considered such as Jeffreys’ prior or reference priors (Ramos et al. 2017RAMOS PL, ACHCAR JA, MOALA FA, RAMOS E and LOUZADA F. 2017. Bayesian analysis of the generalized gamma distribution using non-informative priors. Statistics 51(4): 824-843.) to perform inference with this generalized model, they depend on polygamma functions which do not allow us to obtain closed-form estimators. On the other hand, they considered the following objective prior
where are known hyperparameters. From the likelihood function (23) and the prior distribution (24), the joint posterior distribution for is given by,
where is a normalized constant with parameter space , is a small constant and is a large constant. We select for the interval of as the interest is in the situation where . Hence, any interval that contains is adequate for our purposes.
To achieve the maximum a posteriori probability estimator of we consider . Hence, we have that the MAP estimate of is given by
As can be noted, (26) will be equal to the MLE (11) if and only if , i.e, is unbiased when . Hence we consider only that . Moreover, if , then (25) is a proper posterior distribution, i.e., (see Louzada et al. 2018LAWLESS JF. 2011. Statistical models and methods for lifetime data. Volume 362, J Wiley \& Sons.). The MAP estimate of is given by
and the MAP estimate for is obtained by solving the non-linear equation
For the WH distribution ( ), the MAP estimator for is and the estimate of is obtained from
It is possible to show that the asymptotic variance and of and are given by
and
4.3 - CENSORED DATA
In the case of censored data, the joint posterior distribution for and , produced by the overall reference prior is given by
To sample from the joint posterior distribution using the Markov Chain Monte Carlo (MCMC) methods it is necessary to consider the conditional distributions for the parameters. The conditional posterior distribution of is given by
The conditional posterior distribution of is given by
Since the marginal distributions do not belong to any known parametric family, the Metropolis-Hastings algorithm was considered in order to generate samples from the marginal posterior. The Gamma distribution was used as transition kernel , for sampling values of , where b is the parameter that control the rate of acceptance of the algorithm. In our case, we choose b to be equal to one. However, other higher values can also be considered. To increase the convergence of the MCMC method, we could use the closed-form estimators as a good initial value for and .
The Metropolis-Hastings algorithm operates as follows:
-
1. Start with an initial value and set the iteration counter
-
2. Generate a random value from the proposal with PDF given by and random values and from an independent uniform in ;
-
3. Evaluate the acceptance probability
-
4. If , then . Otherwise, ;
-
5. Generate a random value from the proposal and a random value from an independent uniform in ;
-
6. Evaluate the acceptance probability
-
7. If , then . Otherwise, ;
-
8. Change the counter from to and return to step 2 until convergence is reached.
5 - NUMERICAL ANALYSIS
In this section, the proposed estimation methods are investigated via Monte Carlo simulation in order to compare their efficiency. We used two of the most commonly used measures to assess the performance of the estimators, namely, the mean relative error (MRE) and the root-mean-square error (RMSE), given by and , for respectively, where is the number of estimates and is the estimates obtained through the MLE and MAP estimators. The MRE and the RMSE of the are the same for the different estimation procedures.
Taking into account this approach, the most efficient estimators are those ones yielding MREs closer to one with smaller RMSEs. It is also computed the coverage probability ( ) of the credibility intervals (CI) obtained from the Bayesian estimators and the confidence intervals from the classical approach for and . Under this approach, the estimators with best coverage probabilities will show the frequencies of intervals that cover the true values of closer to the nominal level. The samples of size were generated by assuming . The results were computed by using the software R. Overall, the main aim of this section is to compared the Bayes estimators with the classical approach in order to verify if our proposed estimators return more accurate results. This approach has been considered for other models such as Gamma (Louzada et al. 2019LOUZADA F, RAMOS PL and NASCIMENTO D. 2018. The inverse nakagami-m distribution: A novel approach in reliability. IEEE Trans Rel (99): 1-13.), Weibull (Teimouri et al. 2013TEIMOURI M, HOSEINI SM and NADARAJAH S. 2013. Comparison of estimation methods for the weibull distribution. Statistics 47(1): 93-109.), Kumaraswamy (Dey et al. 2018DEY S, MAZUCHELI J and NADARAJAH S. 2018. Kumaraswamy distribution: different methods of estimation. J Comput Appl Math 37(2): 2094-2111.) and the GG distribution (Ramos et al. 2017), to list a few.
5.1 - COMPLETE DATA
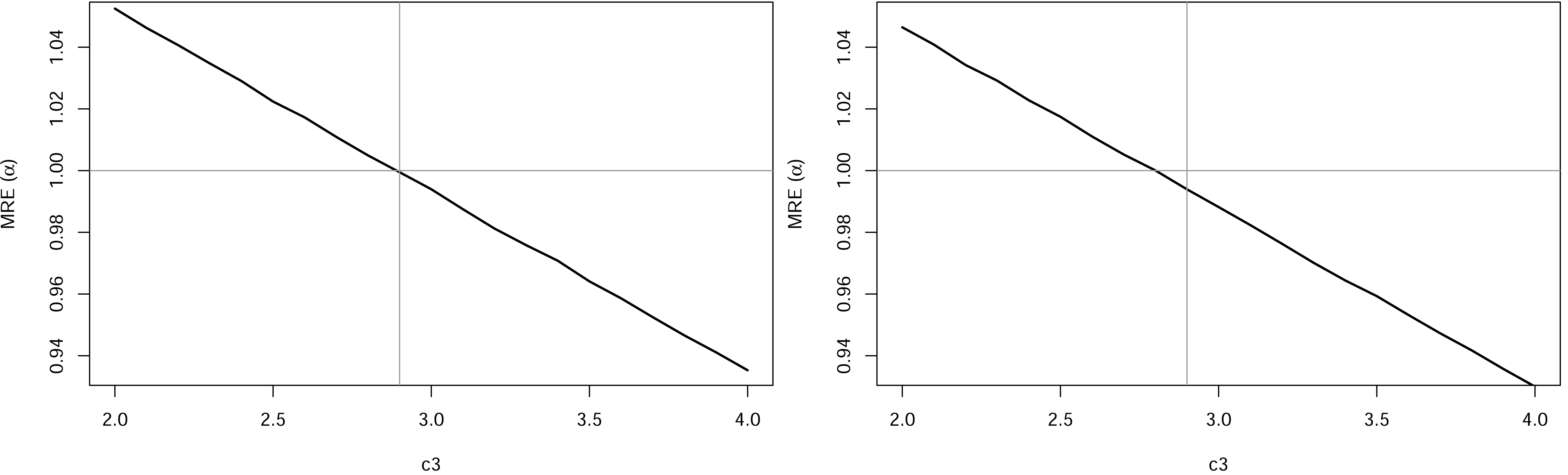
Recall that it was presented a class of MAP estimators for that depends on . Therefore, before going on with the simulation study, it is necessary to find a value for in which the MRE is closer to one. Figure 2 presents the MREs for considering different values of , for and and . We observed that a good choice is . Therefore, we considered such value in (28), where . Since both estimators obtained from the reference posterior and the closed-form Bayes estimators came from the Bayesian approach, they will be referred to as Bayes and CBayes estimators, respectively. To achieve the MLEs, numerical techniques must be used to solve the non-linear equation (12), the uniroot function available in R was considered to find the estimate, and as provided theoretically, we find a unique solution in all situations.

Figure 3 shows the MREs, RMSEs and CPs for the estimates of and obtained by using the Monte Carlo (MC) method where , and . The horizontal lines in the figures correspond to the minimum MREs and RMSEs, equal to one and zero, respectively. Notice that for we have the same estimator using the three different estimators for complete data. In this case, both MRE and RMSE are similar. On the other hand, the confidence and credibility intervals are computed differently for each method. We observe that the estimates of the parameters are asymptotically unbiased, i.e., the MREs tend to one when increases and the RMSEs decrease to zero. However, the Bayes estimators, obtained from the reference posterior, outperform the other estimation procedures and present extremely efficient estimates for both parameters even for small sample sizes. It worth mentioning that if one needs fast computation, the CBayes returned similar estimates when compared to the Bayes estimators, obtained by considering reference priors.

MREs, RMSEs and CPs for and \(\lambda\) considering \(\alpha=4, \lambda=2\) (upper panel) and \(\alpha=0.5, \lambda=2\) (lower panel) for simulated samples and \(n=(15,20,\ldots,100)\) .
5.2 - CENSORED DATA
In this section, we considered the Bayes estimators in the presence of randomly censored data. The censored data were generated as follows. We first generated two random samples of size , where and , with as fixed value. Then, from the obtained samples, we took , and defined if or if .
Note that has to be selected in order to obtain the desired proportion of censoring. In order to obtain approximately and proportions of censored data, i.e., and of censorship we considered and , respectively. The simulation study is performed by considering , and , . To achieve the MLEs considering censored data the maxLik package to maximize the log-likelihood function (15). Different initial values were considered which returned the same estimates. Figure 4 shows the MREs, RMSEs and the coverage probabilities from the estimates of and obtained by using the MC method where , .

MREs, RMSEs and CPs for and considering for simulated samples, (upper panel) and (lower panel) of censoring and .
The results indicate that the MLE of has a systematic bias, as shown in Figure 4. On the other hand, from the Bayes estimators, we have observed more accurate results. The coverage probabilities are also close to the nominal levels as the MLE. Therefore, the Bayes estimators are also recommended to perform inference for the parameters of the WH distribution in the presence of censoring.
6 - PREDICTION ANALYSIS
In many application, we may be interested in identifying the time to the next event (failure). In these contexts, predicting future observations plays an important role, especially, when costs are linked with the events. In order to provide a predictive analysis of future events, we consider the Bayesian prediction with WH distribution using observed order statistics.
Several authors have performed prediction analysis from the Bayesian point of view (see, for instance, Pradhan and Kundu (2011)PRADHAN B and KUNDU D. 2011. Bayes estimation and prediction of the two-parameter gamma distribution. J Stat Comp Simul 81(9): 1187-1198., Kundu and Raqab (2012)KUNDU D and RAQAB MZ. 2012. Bayesian inference and prediction of order statistics for a type-ii censored Weibull distribution. J Stat Plan Inference 142(1): 41-47., Asgharzadeh et al. (2015)ASGHARZADEH A, VALIOLLAHI R and KUNDU D. 2015. Prediction for future failures in weibull distribution under hybrid censoring. J Stat Comput Simul 85(4): 824-838.) for other distributions and the predictive distribution of future failure times and its respective credibility intervals.
We denote the order statistics of by . Let be the unobserved future sample and denote the -th order statistic. From the Markov property of the conditional order statistics, we have
for . After some algebra we have
The posterior predictive density of given is given by
where is given in (31). Consequently, the predictive density of according to is given by
We also should note here that one striking result of the Bayesian predictive approach is the advantage in constructing a credibility interval for using the MCMC techniques.
7 - REAL-DATA APPLICATIONS
We examined the adjust of the proposed model on three real datasets to emphasize its flexibility and compare its performance with other distributions. A closer inspection of the following figures shows that the WH distribution exhibits best fit for each dataset when compared to commonly used distributions. In order to discriminate the best fit, we considered some key performance measures, namely, the Akaike information criterion (AIC) given by the Corrected Akaike information criterion (AICc) given by and the Bayesian information criterion (BIC) given by where is the dimension of and is the estimate of the parameters and is the logarithm of the likelihood function given in (8) and (14).
7.1 - LIFE TEST IN ELECTRICAL APPLIANCES
Table I presents a well-known dataset available in Lawless (2011), the number of 1000s of cycles to failure for a group of 60 electrical appliances in a life test, whose data are uncensored.
The results summarized in Table II show that the WH distribution is the best model since resulted in the lowest values of the different discrimination methods.
Results of AIC, AICc and BIC criteria for all fitted distributions considering the dataset related to the failure time of 60 electrical appliances.
In order to discriminate the best fit, we considered the AIC, AICc, and BIC available in Table II. For the three criteria, we observed that the proposed model has smaller values, indicating a better fit for the WH distribution.
Table III provides the summary statistics: the MAP estimates, standard-deviations (SD) and 95% credibility intervals (CI) for , and (future failure time). We can obtain the MAP estimates of the parameters and from (26) and (28), respectively. In order to predict the future failures of an item, as described in Section 6, we considered the posterior predictive density of from (34).
As can be seen from Table I, the last failure was observed at 9.701 cycles. Then, the last line of Table III shows the prediction of the 61st failure will be at cycles with 95% predictive interval given by (9.7185; 12.1094).
7.2 - FAILURE TIME DATA OF ELECTRICAL COMPONENTS
The following datasets motive the application of WH distribution in the presence of censored data. The first dataset concerns electrical failures in the components from agricultural machines. The follow-up time was a harvesting season. In this period, the electrical components have failed 29 times collected in 2017. The data are shown in Table IV.
Dataset related to the agricultural machines with failure in electrical components (+ indicates censoring).
In order to discriminate the best fit, we used the AIC, AICc, and BIC (see Table V). In all of them, the proposed model has smaller values, indicating a better fit.
Results of AIC, AICc and BIC criteria for all fitted distributions considering the dataset related to the agricultural machine’s components electrical problems.
Table VIprovides the summary statistics: the MAP estimates, SDs and 95% CIs for , and (future failure time). As can be seen from the Table IV the last failure was observed on the day. Then from the last line of Table VI we can see the prediction of the failure that will be at \(50.13\) days, with a 95% predictive interval given by (47.27; 78.25).
Turning now to another type of failure, Table VII presents the time up to corrective maintenance of the agricultural machine. In this case, correctly predicting the next maintenance is of main interest in order to reduce costs.
Dataset related to the agricultural machine’s corrective maintenance (+ indicates censoring).
From the results presented in Table VIII we observe from the AIC, AICc and BIC that the WH distribution returned better fit for the dataset.
Results of AIC, AICc and BIC criteria for all fitted distributions considering the dataset related to the agricultural machine’s revision.
Table Table IXshows the MAPs, standard deviations, and 95% credible intervals for the parameters of the WH distribution. From Table VII the last failure was observed at 13 days. Applying the proposed methodology, the prediction of the 31st maintenance will be at 13.37 days with 95% predictive interval given by (13.03;16.83).
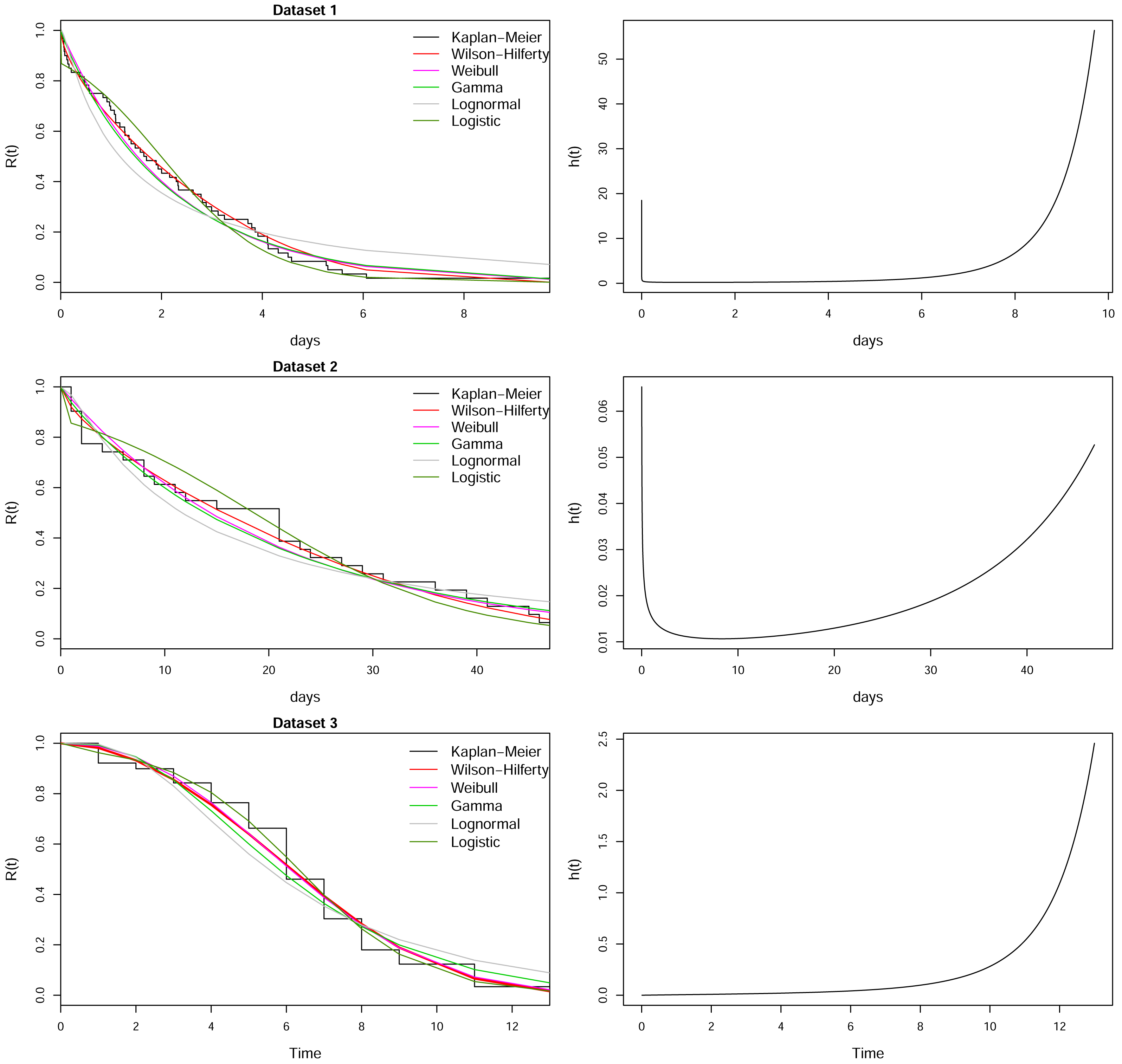
Figure 5presents the reliability function fitted by different distributions and the Kaplan-Meier curve for the three data sets. In all cases, the WH distribution provides an improved fit for the datasets.

Reliability function adjusted by different distributions superimposed to the empirical reliability function. Right-hand panel: Estimated hazard function.
Therefore, the practical importance of the WH distribution is observed for these datasets, since it provides a better fitting in comparison with other essential distributions, allowing to conduct prevision for the next failures.
8 - CONCLUSIONS
In this paper, we revisit the WH distribution and presented mathematical properties of this important distribution, which can be used in situations where the data present bathtub or increasing hazard rate. Initially, the parameter estimators and their asymptotic intervals were explored using the maximum likelihood theory under complete and censored data. Further, we considered an objective Bayesian analysis with an overall reference prior in order to obtain improved estimators, which outperform the ones obtained via maximum likelihood. It is proved that the reference posterior distribution is proper when and the resulting marginal posterior intervals have accurate frequentist coverage. Moreover, we have introduced MAP estimators for the parameters of WH distribution that have closed-form expressions. A simulation study revealed the superiority of the Bayes estimators.
A Bayes prediction of the future failure time was also presented based on observed order statistics. The proposed methodology was applied to three data sets associated with failure time. Many possible extensions of this current work can be considered. This distribution is a promising distribution to be used in studies involving recurrent event data. In this case, we can consider a rate model from a nonhomogeneous Poisson process, where the parametric baseline rate function is a WH rate function. Further, classical point prediction could be studied for this model, for example, maximum likelihood prediction, best-unbiased predictor, conditional median prediction along with prediction interval using Pivotal method and highest conditional density (HCD) method. Our approach should be investigated further in this context.
ACKNOWLEGMENTS
The authors are very grateful to the Editor and the three reviewers for their helpful and useful comments that improved the manuscript. This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) and Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq). Pedro L. Ramos is grateful to the Fundação de Amparo à Pesquisa do Estado de São Paulo (FAPESP, Proc. 2017-25971-0).
REFERENCES
- ASGHARZADEH A, VALIOLLAHI R and KUNDU D. 2015. Prediction for future failures in weibull distribution under hybrid censoring. J Stat Comput Simul 85(4): 824-838.
- BERGER JO et al. 2015. Overall objective priors. Bayesian Anal 10(1): 189-221.
- BERNARDO JM. 1979. Reference posterior distributions for bayesian inference. J Royal Stat Soc Series B, p. 113-147.
- BERNARDO JM. 2005. Reference analysis. Handbook of Statistics 25: 17-90.
- COX DR and REID N. 1987. Parameter orthogonality and approximate conditional inference. J Royal Stat Society Series B 49(1): 1-18.
- CRAIN BR and MORGAN RL. 1975. Asymptotic normality of the posterior distribution for exponential models. Ann Stat, p. 223-227.
- DEY S, MAZUCHELI J and NADARAJAH S. 2018. Kumaraswamy distribution: different methods of estimation. J Comput Appl Math 37(2): 2094-2111.
- FOLLAND GB. 1999. Real analysis: modern techniques and their applications. Wiley, New York, 2nd edition.
- ISHIKAWA T, TOTANI T, NISHIMICHI T, TAKAHASHI R, YOSHIDA N and TONEGAWA M. 2014. On the systematic errors of cosmological-scale gravity tests using redshift-space distortion: non-linear effects and the halo bias. Mon Notices Royal Astron Soc 443(4): 3359-3367.
- KHODABIN M and AHMADABADI A. 2010. Some properties of generalized gamma distribution. Math Sci 4(1): 9-28.
- KUNDU D and RAQAB MZ. 2012. Bayesian inference and prediction of order statistics for a type-ii censored Weibull distribution. J Stat Plan Inference 142(1): 41-47.
- LAWLESS JF. 2011. Statistical models and methods for lifetime data. Volume 362, J Wiley \& Sons.
- LOUZADA F, RAMOS PL and NASCIMENTO D. 2018. The inverse nakagami-m distribution: A novel approach in reliability. IEEE Trans Rel (99): 1-13.
- LOUZADA F, RAMOS PL and RAMOS E. 2019. A note on bias of closed-form estimators for the gamma distribution derived from likelihood equations. Am Stat, p. 1-8.
- PRADHAN B and KUNDU D. 2011. Bayes estimation and prediction of the two-parameter gamma distribution. J Stat Comp Simul 81(9): 1187-1198.
- RAMOS PL, ACHCAR JA, MOALA FA, RAMOS E and LOUZADA F. 2017. Bayesian analysis of the generalized gamma distribution using non-informative priors. Statistics 51(4): 824-843.
- RAMOS PL, LOUZADA F and RAMOS E. 2018. Posterior properties of the nakagami-m distribution using noninformative priors and applications in reliability. IEEE Trans Rel 67(1): 105-117.
- STACY EW. 1962. A generalization of the gamma distribution. Ann Math Stat, p. 1187-1192.
- TEIMOURI M, HOSEINI SM and NADARAJAH S. 2013. Comparison of estimation methods for the weibull distribution. Statistics 47(1): 93-109.
- TIBSHIRANI R. 1989. Noninformative priors for one parameter of many. Biometrika 76(3): 604-608.
- WILSON EB and HILFERTY MM. 1931. The distribution of chi-square. Proc Natl Acad Sci 17(12): 684-688.
- ZEMZAMI M and BENAABIDATE L. 2016. Improvement of artificial neural networks to predict daily streamflow in a semi-arid area. Hydrol Sci J 61(10): 1801-1812.
Publication Dates
-
Publication in this collection
19 Aug 2019 -
Date of issue
2019
History
-
Received
02 Jan 2019 -
Accepted
10 June 2019