Resumos
A análise da informação é uma excelente estratégia para monitoramento, pesquisa e desenvolvimento em todos os ramos do conhecimento. O objetivo primordial deste trabalho foi consolidar um método alternativo empregando ferramentas eletrônicas na realização do monitoramento automatizado da informação e em sua análise bibliométrica. O trabalho foi desenvolvido tendo como suporte a base Web of Science, do Institute for Scientific Information (ISI), e o uso de softwar como Word, Excel, Reference Manager e Origin. A título de exemplo, aplicamos o método à área de desenvolvimento de produtos, obtendo como resultados uma lista de descritores, a relação dos periódicos mais importantes da área, os autores mais produtivos e uma indicação das parcerias mais freqüentes entre eles.
Monitoramento da informação; Biblioteconomia; Ciência da informação
Analysis of information is an excellent strategy for Monitoring, Research and Development in all branches of knowledge. This work was developed using Web of Science's database, from ISI (Institute for Scientific Information). The main objective was to establish an alternative method employing electronic tools in computer-assisted monitoring of information and its bibliometric analysis. Also used were the software Word, Excel, Reference Manager and Origin. As an application example, the method was applied to the area of Product Development, and the output results of the research were a list of keywords, a relation of the most important journals in the area, the most productive authors, and an indication of the most frequent partnerships among them.
Information monitoring; Bibliometry; Information science
Ferramentas alternativas para monitoramento e mapeamento automatizado do conhecimento
Alternative tools for computer-assisted monitoring and mapping of knowledge
Lúcia Cunha OrtizI; Wilson Aires OrtizII; Sergio Luis da SilvaIII
ICientista da Informação responsável pela Secretaria de Monitoramento de Informação Científica e Tecnológica do CMDMC/Cepid/Fapesp, UFSCar, Departamento de física Grupo de Supercondutividade e Magnetismo
IIProfessor adjunto do Departamento de Física da UFSCar. Vice-diretor do Centro Multidisciplinar de Desenvolvimento de Materiais Cerâmicos, CMDMC/Cepid/Fapesp, UFSCar, Departamento de Física Grupo de Supercondutividade e Magnetismo
IIIProfessor assitente do Departamento de Ciência da Informação da UFSCar. Doutorando e pesquisador do EM UMA/EESC/USP, UFSCar, Departamento de Ciência da Informação da UFSCar
Endereço para correspondência Endereço para correspondência Lúcia Cunha Ortiz E-mail: lucia@df.ufscar.br.
RESUMO
A análise da informação é uma excelente estratégia para monitoramento, pesquisa e desenvolvimento em todos os ramos do conhecimento. O objetivo primordial deste trabalho foi consolidar um método alternativo empregando ferramentas eletrônicas na realização do monitoramento automatizado da informação e em sua análise bibliométrica. O trabalho foi desenvolvido tendo como suporte a base Web of Science, do Institute for Scientific Information (ISI), e o uso de softwar como Word, Excel, Reference Manager e Origin. A título de exemplo, aplicamos o método à área de desenvolvimento de produtos, obtendo como resultados uma lista de descritores, a relação dos periódicos mais importantes da área, os autores mais produtivos e uma indicação das parcerias mais freqüentes entre eles.
Palavras-chave: Monitoramento da informação; Biblioteconomia; Ciência da informação.
ABSTRACT
Analysis of information is an excellent strategy for Monitoring, Research and Development in all branches of knowledge. This work was developed using Web of Science's database, from ISI (Institute for Scientific Information). The main objective was to establish an alternative method employing electronic tools in computer-assisted monitoring of information and its bibliometric analysis. Also used were the software Word, Excel, Reference Manager and Origin. As an application example, the method was applied to the area of Product Development, and the output results of the research were a list of keywords, a relation of the most important journals in the area, the most productive authors, and an indication of the most frequent partnerships among them.
Keywords: Information monitoring; Bibliometry; Information science.
INTRODUÇÃO
O desenvolvimento científico e tecnológico mundial tem crescido enormemente nas últimas décadas. Uma das mais claras manifestações desse crescimento espetacular é o surgimento de um imenso número de veículos e meios de divulgação voltados à comunidade técnico-científica. Atualmente, além de um número muito grande de periódicos e publicações especializadas em papel, tem ocorrido um aumento significativo na utilização de meios eletrônicos de divulgação.
Além disso, registre-se a crescente especialização destes meios, que desdobram uma área de conhecimento em várias unidades, por um lado facilitando a busca por meio da divisão, mas, ao mesmo tempo, dificultando-a pela pulverização de cada assunto em domínios específicos.
A realização de atividades de pesquisa e desenvol-vimento, como aquelas executadas em laboratórios universitários, requer um trabalho sistemático de monitoramento e prospecção das áreas de conhecimento principais e correlatas às suas atividades. Este trabalho de busca, análise e síntese de informações emprega cada vez mais metodologias e ferramentas baseadas em bibliometria, estatística e sistemas de informação, sem o que se tornaria praticamente impossível acompanhar a informação disponível, crescente em quantidade e diversidade, bem como sua disseminação com o auxílio de diferentes suportes.
O uso destas metodologias e ferramentas, genericamente classificado como tratamento automatizado da informação, ou bibliometria automatizada, consiste basicamente da aplicação de filtros para classificar e separar a informação coletada, bem como agregar-lhe valor. Esta abordagem tem sido empregada para disponibilizar, por meio de indicadores de tendências, informações vitais, seja para o pesquisador ou para outros tomadores de decisão.
O tratamento da informação é a base do processo de monitoramento tecnológico, ou, de um modo mais geral, da inteligência competitiva. O monitoramento tecnológico consiste em pesquisar o assunto escolhido, que pode ser um produto, uma tecnologia, uma instituição, pesquisadores, fontes de informação científica e tecnológica, dentre outras ligadas ao assunto focalizado. A inteligência competitiva consiste na aquisição, análise, compreensão, síntese e difusão interna de informações de diversas fontes e tipos, sobre todos os assuntos de interesse da instituição em questão, visando a ajudar os tomadores de decisão (McGonagle, 1998).
Inteligência é a informação analisada, e inteligência competitiva é, portanto, a informação analisada para a competitividade. No Brasil, a busca pelo aumento na competitividade tem despertado grande interesse por esses estudos. A bibliometria aparece no contexto da inteligência competitiva como a ferramenta que elabora indicadores de tendências, gráficos, figuras e mapas que vão sintetizar as informações para a tomada de decisão.
A partir do universo de metodologias e ferramentas já existentes, desenvolvemos um procedimento que permitiu criarmos uma classificação e um Mapa de Conhecimentos, que pode ser um minidicionário ou até mesmo um minitesauro da área pesquisada, com a finalidade de facilitar as buscas de informação por parte dos pesquisadores, focando ao máximo o universo de busca e retendo apenas a parte útil das informações. Esta tarefa foi conduzida tendo-se como fonte de informação um conjunto mundial de periódicos indexados, disponíveis no banco de dados internacional do Institute for Scientific Information (ISI).
O procedimento desenvolvido para geração da classificação e do Mapa de Conhecimentos foi testado mediante aplicação na área de desenvolvimento de produtos. Segundo Toledo (1993), o desenvolvimento de produtos situa-se na interface entre a empresa e o mercado, daí sua importância estratégica, cabendo-lhe chegar a um bem que atenda às expectativas do mercado e que possa ser produzido de forma eficiente.
De posse de um Mapa de Conhecimentos, pode-se ter uma melhor orientação sobre os descritores ou conhecimentos que devem ser monitorados, bem como a intensidade, a freqüência, assim como as formas de fazê-lo.
Tratamento da informação
Muitas ainda são as dificuldades encontradas para realizar o procedimento operacional da análise bibliométrica. Uma das mais críticas é a falta de padronização entre os formatos disponíveis para recuperação da informação nas bases de dados, chegando muitas vezes a serem incompatíveis até com os formatos exigidos pelos softwares para tratamento de dados. Alguns dos softwares utilizados no tratamento automatizado da informação são Infotrans, Infobanks, Idealist, Dataview, Patent Trend Analysis, Matrisme, Access, Statística, e Excel, (Portter, 1981; Rostaing, 1996).
Segundo Sotolongo (1999), muitos pesquisadores têm buscado novas alternativas para seus estudos bibliométricos, não só pelo preço, que nem sempre é acessível a todos, mas também como uma forma de criar opções para estudos e análises nessa área. O presente artigo decorre desta mesma preocupação de identificar rotas "alternativas" usando softwares comerciais, tais como Word, Excel, Reference Manager e Origin, buscando, assim, chegar a algo que possamos chamar de inovador no tratamento automatizado da informação.
METODOLOGIA
Escolha da fonte de informação
O Institute for Scientific Information (ISI) é a principal instância de indexação de artigos na área científica. A escolha desta fonte deve-se a uma série de fatores, além da facilidade de acesso via Internet:
o banco de dados de periódicos e respectivos artigos indexados do ISI são uma amostragem representativa da produção das comunidades científica e técnica mundiais, tanto em termos de quantidade, em vista do grande número de periódicos que fazem parte deste banco, quanto qualitativamente, devido ao rigor de critérios de avaliação das revistas indexadas participantes deste grupo;
neste banco de dados há tanto periódicos destinados a trabalhos em ciência "pura", como também aqueles devotados a artigos sobre "ciência aplicável" e tecnologia;
o banco de dados ISI tem impacto e repercussão na comunidade científica mundial, sendo normalmente usado para finalidades múltiplas, desde a busca de artigos sobre um determinado assunto, até a coleta de dados para avaliação de pesquisadores e institutos.
Escolha da área de aplicação
Pessoas diferentes possuem visões distintas das organizações, a partir da base cultural e social em que estão inseridas. Considerando este pressuposto básico, pode-se inferir que o mesmo ocorre com o desenvol-vimento de produtos em uma empresa, havendo então diferentes formas de se ver esta atividade, de acordo com as diferenças pessoais e a formação básica dos envolvidos.
Até bem pouco tempo, desenvolver produtos vinha sendo tratado de maneira isolada pelas diferentes áreas de conhecimento. Ainda hoje, profissionais de engenha-ria tendem a pensar o desenvolvimento de produto como uma atividade específica composta de cálculos e teste. Alternativamente, para designers e programadores visuais o produto a ser desenvolvido é o resultado de estudos de conceitos; para administradores é algo mais abstrato, independente do conteúdo tecnológico e voltado para problemas organizacionais e estratégicos; enquanto que, para especialistas em qualidade, por seu turno, o produto é visto principalmente como aplicação de um instru-mental específico desta área (Rozenfeld et alii. 2000).
Tantas visões diferentes podem levar a problemas e até mesmo à ineficiência. Cada visão parcial carrega consigo uma linguagem e determinados valores próprios, que dificultam a integração entre os profissionais pertencentes a cada uma dessas escolas. No entanto, qualquer desenvolvimento de produto, por maior que seja a hegemonia de um determinado conteúdo tecnológico, deve ser um todo integrado que depende, para um adequado resultado final, dos conhecimentos de várias destas visões.
Enfrentar esta situação requer a construção de uma imagem única e integrada do processo de desenvol-vimento de produto. Uma forma de conseguir isso é visualizar a realização do desenvolvimento de produtos por meio de algum tipo de modelamento deste processo, agrupando-se então as fases envolvidas desde a proposição do conceito até o lançamento do novo produto e procurando realçar as conexões entre tarefas e conhecimentos envolvidos nesse processo.
Neste sentido, para auxiliar na modelagem do processo de desenvolvimento de produtos, um recurso útil é um Mapa de Conhecimentos, cuja rotina de construção é uma de nossas contribuições.
METODOLOGIA ESPECÍFICA
Com a disposição de testar softwares alternativos para a análise bibliométrica, usamos o Word e o Excel, que estão disponíveis em praticamente qualquer computador pessoal, o Reference Manager (RM) e o Origin1 1 Word e Excel são utilitários da Microsoft, Reference Manager é produzido pela ISI-Research Soft, e o Origin é um produto da Microcal. , que também são muito populares. Cada um deles tem funções específicas: o Word é usado para os textos; o Excel, para as planilhas; o Origin, para as figuras; o RM, para o gerenciamento de bases de dados e organização de referências.
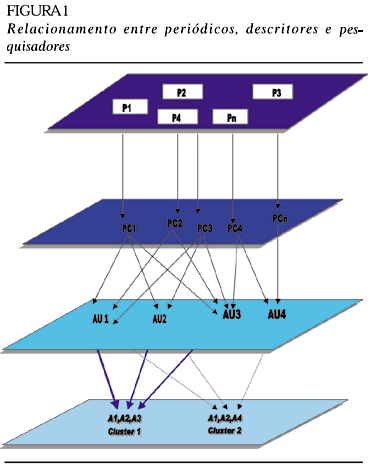
Usando o banco de dados do ISI, nas suas áreas de ciências e engenharias, que são os grandes grupos nos quais se encaixa o tema desenvolvimento de produtos, e fazendo uso de métodos e ferramentas de tratamento automatizado da informação, levantamos um Mapa de Conhecimentos, como o esquematizado na figura 1.
Usando o banco de dados do ISI, nas suas áreas de ciências e engenharias, que são os grandes grupos nos quais se encaixa o tema desenvolvimento de produtos, e fazendo uso de métodos e ferramentas de tratamento automatizado da informação, levantamos um Mapa de Conhecimentos, como o esquematizado na figura 1.
Com o Mapa, podemos detectar os relacionamentos eventualmente existentes entre as três entidades mencionadas (periódicos, descritores/conhecimentos/palavras-chave e autores), para a área de pesquisa em questão. A partir daí, será possível verificar se há clusters em torno de um determinado conhecimento, indicando quais são os pesquisadores e periódicos mais relacionados com este e que, portanto, merecem maior atenção e acompanhamento sistemático.
Tomemos, como exemplo, um caso em que os conhecimentos (palavras-chave PC) obtidos no Artigo 1 são PC1, PC2 e PC3 (temos, portanto, três relações: PC1«PC2; PC1«PC3 e PC2«PC3). Se as PCs obtidas no Artigo 2 forem PC1, PC2, PC3 (as mesmas do artigo anterior) e PC4, teremos, portanto, seis relações: PC1«PC2; PC1«PC3; PC1«PC4; PC2«PC3; PC2«PC4 e PC3«PC4. Procedendo-se de modo análogo para os demais artigos, obtém-se ao final uma listagem de palavras-chave2 2 Neste trabalho, os termos "palavra-chave", "descritor" e "conhecimento" são tratados como sinônimos. (ou descritores) com um indicador de seus relacionamentos. Assim, chamando de nij o número de vezes que um certo par de palavras-chave PCi«PCj aparece no cruzamento de quaisquer dois artigos, podemos representar os indicadores de relacionamento de uma forma matricial, que pode ter um preenchimento automatizado. Lembrando que nij = nji, teremos:
Além deste relacionamento em nível horizontal (incluindo-se as matrizes "periódicos versus periódicos" e "pesquisadores versus pesquisadores", conforme esquema na figura 1), é também possível a quantificação de relacionamentos em níveis (horizontal«vertical), construindo-se matrizes com "periódicos versus palavras-chave", ou "pesquisadores versus palavras-chave", ou ainda "pesquisadores versus periódicos".
Assim, a utilização de uma ferramenta automatizada para a construção destas inúmeras matrizes e de suas representações gráficas facilita a coleta de dados e sua análise crítica.
Escolha de descritores
Descritores foram escolhidos a partir de uma lista elaborada por pesquisadores do Núcleo de Manufatura Avançada da Universidade de São Paulo (Em uma), campus São Carlos, que, trabalhando na área, conhecem as suas características e peculiaridades. Essa experiência resultou em uma primeira lista com as 75 palavras mais usadas na área, das quais, depois de busca na Web of Science, ficamos com 44 para a análise final. Isto porque, das 75 palavras pesquisadas, 31 resultaram em resposta nula, sendo então excluídas de nossa busca.
Busca na base de dados Science Citation Index ISI
A busca, restrita aos anos de 1995 a 2000, foi realizada por meio dos descritores mencionados anteriormente. A escolha desse período em particular teve o objetivo de restringir o volume de informação sem perda de atualidade. Para nossa busca na Web, fixamos os parâmetros conforme a descrição que se segue:
Base pesquisada: Science Citation Index Expanded -1945-present
Year selection: 2000 1999 1998 1997 1996 1995
Procedimento de busca
Primeiramente realizamos uma busca individual, com cada um dos descritores, obedecendo às seguintes etapas:
Busca Título: busca apenas no título dos artigos. Nessa busca, obtivemos como respostas o número de artigos que correspondiam ao solicitado, sem a preocupação com a eventual existência de duplicatas.
Busca Total: uma segunda busca, incluindo o título e o abstract, anotando-se o número de ocorrências sem a preocupação com duplicidade.
Busca Refinada: fixando-seum descritor e utilizando o boleano AND no cruzamento desse descritor com cada um dos outros 43, pudemos verificar a existência de pares. Cada descritor X que, cruzado com o descritor Y, tenha resultado diferente de zero poderá então ser considerado um "conhecimento" relevante. Isto significa que, em uma busca feita com esse par de descritores, o pesquisador efetivamente obterá resposta não-trivial da base de dados.
Análise dos dados
Digitamos todos os números de ocorrências resultantes das buscas em uma planilha Excel, montando uma matriz cujos elementos foram depois importados para o Origin, onde produzimos a curva conhecida como "J invertido". Esse procedimento foi repetido para as duas buscas, isto é, tanto nos dados obtidos na BuscaTítulo como naqueles obtidos na BuscaTotal. O procedimento é repetido por completeza, para a verificação de cada uma das leis bibliométricas.
Depois de analisadas as palavras, passamos a estudar as relações existentes entre os autores, verificando a formação de clusters, isto é, quem trabalha com quem na área de desenvolvimento de produto. Finalizamos nossa pesquisa analisando quais são os periódicos de maior relevância na área.
Em seguida, apresentamos fluxogramas representativos dos procedimentos empregados em buscas e análise envolvendo ListadePeriódicos,ListasdeDescritorese ClustersdeAutores (figuras 2, 3 e 4).
Resultados procedimento detalhado
Descritores
A partir da listagem de descritores inicialmente proposta, foram escolhidos os "não-triviais", que formam a base do trabalho. Os descritoressão mostrados na tabela 2, a seguir.Para cada um deles, realizamos dois tipos de busca individual, uma procurando pelo descritor apenas no título e a outra incluindo título e abstract, conforme discutimos anteriormente.

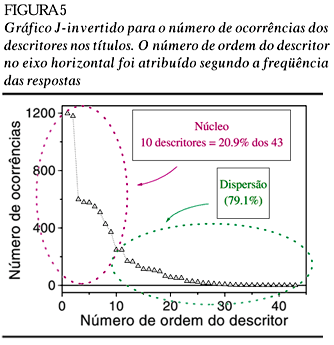
As respostas obtidas para cada um dos descritores são resumidas na tabela 2. Na figura 5, a seguir, temos o gráfico J-invertido para o número de ocorrências dos descritores nos títulos. O número de ordem do descritor no eixo horizontal foi atribuído segundo a freqüência das respostas. A figura 6 mostra o gráfico J-invertido para o número de ocorrências dos descritores no total, isto é, títulos e abstract. Como na figura anterior, o número de ordem do descritor foi atribuído de acordo com a freqüência das respostas.
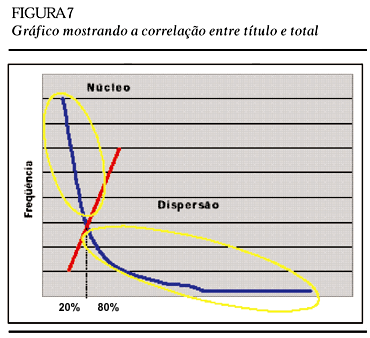
Segundo a representação da Lei de Zipf pelo modelo de "Núcleo e Dispersão" (Potter,1981; Rostaing, 1996), a porção mais significativa dos descritores estaria concentrada nos 20% mais freqüentes, como mostramos nas figuras 6 e 7, a seguir. A alternativa proposta por outros autores (Rostaing, 1993, Rostaing, 1996; Faria, 1995; Quonian, 1997) separa a curva em três zonas para casos como este, em que o elemento bibliométrico pertence a um vocabulário controlado.
Entretanto, não havendo consenso quanto às porcentagens de cada zona e tendo em conta que é pequeno o número de descritores , decidimos não nos deter neste aspecto.
Busca com booleano AND e construção da matriz D
Como o número de descritores com resposta não-nula é relativamente pequeno, vamos incluir todos os 36 em nossa amostragem. Se o número de descritores fosse uma ou duas ordens de grandeza maior, seria sensato desprezar os 20% correspondentes à região de ruído. Fixada nossa amostragem, o próximo passo foi o cruzamento entre eles. Para isso, realizamos uma nova busca no ISI, mantendo os mesmos parâmetros anteriores e usando o boleano AND. Fixamos um dos descritores e, realizando a busca com cada um dos outros, encontramos as correlações entre 35 pares de descritores. Em seguida, fixamos um segundo descritor e, realizando a busca com AND, determinamos outras 34 correlações entre pares, e assim sucessivamente até chegarmos ao par formado pelo penúltimo e o último dos descritores.
Uma maneira elegante e concisa de catalogar os resultados dessas buscas como boleano AND é através de uma matriz (D), cujos elementos diagonais, Dii, são os resultados das buscas individuais de cada descritor, enquanto os não-diagonais, Dij, representam as correlações entre dois descritores, conforme as respostas obtidas com o boleano AND. Assim, quanto maior o valor do elemento diagonal, mais freqüente é o descritorno universo pesquisado. Da mesma forma, quanto maior o valor do elemento não-diagonal, maior a correlação entre os dois descritores que ele representa. Obviamente a matriz D tem simetria especular em relação à diagonal (Dij = Dji), razão pela qual construímos apenas a sua metade superior (j ³ i).
O Apêndice 1 apresenta a matriz DTit, construída com os resultados de buscas nos títulos, no formato de uma planilha Excel. Também no Apêndice 1, temos a matriz DTot, com os resultados de buscas no total (títulos e abstract), igualmente no formato Excel.
Clusters de autores
Um dos objetivos deste trabalho foi o estabelecimento de um procedimento sistemático para detectar a formação de clusters (grupos) de pesquisadores que trabalham no mesmo assunto e publicam como co-autores. Além de determinar a composição desses agrupamentos, deseja-se detectar as eventuais interações entre diferentes clusters.
A estratégia empregada para o estudo que levou ao estabelecimento da rotina de monitoramento baseia-se primordialmente na determinação dos autores mais importantes da área, por meio da contagem do número de publicações que incluam pelo menos um dos principais descritores dessa mesma área, seguindo o procedimento de verificação no títuloe no abstract. Em seguida, verificam-se quais são os co-autores de cada autor em particular, delineando assim os clusters e sua eventual correlação.
Para tanto, começamos pela criação de uma base de dados, consolidando por meio do RM (Reference Manager) os resultados das buscas no ISI. Utilizando-nos das ferramentas do utilitário, depuramos a base, eliminando todas as ocorrências duplicadas, ou seja, artigos idênticos que resultaram das buscas com diferentes descritores. Essa base de dados depurada tornou-se o universo para os tratamentos de informação que se seguiram.
Primeiramente, usando a base depurada, construímos uma base-espelho em que, utilizando-nos do filtro adequado, importamos apenas o campo AUTOR (AU) de cada referência. O filtro pode ser escolhido dentre os existentes no RM, ou editado, ou mesmo criado. Uma seqüência esquemática de edição e uso do filtro no RM pode ser vista na figura 7. A base-espelho foi então exportada para o Word (NotePad seria igualmente adequado), para a edição de caracteres espúrios com enters, caracteres invisíveis, eventuais símbolos de campos não importados etc. Tão importante quanto essa depuração de caracteres foi garantir que todos os autores formassem uma coluna única, para ser posteriormente ordenada, de modo que ocorrências repetidas de um mesmo autor aparecessem em seqüência, facilitando a contagem das ocorrências de cada autor. Resolve-se assim, automaticamente, a questão fundamental de que todos os autores de um artigo devem ter tratamento idêntico nesta abordagem, independentemente da ordem em que apareçam na lista de autores de cada artigo.
Abre-se então o Excel para a importação do arquivo derivado da base-espelho, que, devidamente depurado, foi montado de modo que todos os autores com sobrenomes iniciados por determinada letra ocupassem uma única coluna, o que facilita o ordenamento alfabético. De um total de 6.924 autores da base-espelho, selecionamos os mais freqüentes (MFs - todos com duas ou mais citações) para uma nova busca no ISI, objetivando assim detectar os clusters que desejamos identificar.
Observando os Mapas da figura 8, concluímos que não existe, pelo menos em nossa amostragem retirada do ISI, interação entre os diversos clusters. O que temos são clusters isolados, isto é, um autor principalcom alguns colaboradores mais freqüentes, trabalhando de forma estanque. Pesquisadores da área tendem a reconhecer esse "isolamento", que parece ser devido à multidiscipli-naridade da área. A formação de "nichos" parece ser um procedimento comum na área monitorada, o que confirma como confiável o diagnóstico decorrente do procedimento utilizado.
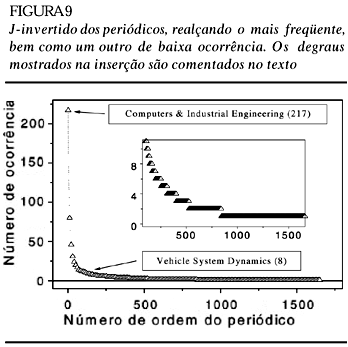
Construção do J-invertido para os periódicos
Um bom exemplo de como informações relevantes podem ser obtidas como decorrência de um processo específico de monitoramento de informação é mostrado aqui por meio do gráfico do tipo J-invertido para os periódicos. Trata-se de uma figura que realça os periódicos mais importantes da área, cuja construção foi feita a partir da mesma base de dados depurada que utilizamos para produzir os Mapas declustersdeautores.
Na figura 9, temos o gráfico J-invertido para os periódicos, indicando dois deles como exemplos: Computers and Industrial Engeneering, com 217 ocorrências, e Vehicle System Dynamics, com oito. A inserção da figura mostra um detalhe da região dos periódicos com menor incidência, em que se notam degraus de altura unitária que vão se alargando até o patamar de uma só citação, que é o mais largo, ou seja, o mais freqüente.
CONSIDERAÇÕES FINAIS
Neste artigo, descrevemos um estudo sistemático de monitoramento da informação, focalizado na área de desenvolvimento de produtos. O estudo baseou-se em resultados obtidos na base ISI - Web of Science e demonstra a utilidade potencial do método para a obtenção de diagnósticos confiáveis.
Executando a sistemática proposta, obtivemos a relação dos periódicos mais usados na área, incluindo a freqüência da citação. Obtivemos também a lista de descritoresque devem ser empregados em buscas de monitoração da área, de modo a minimizar o trabalho de busca sem perda de eficácia. Mostramos também como se pode construir os mapas de autoresda área, determinando os clustersde correlação. Sua correta interpretação possibilita uma leitura dinâmica do movimento da área.
A utilização de softwares como Excel, Word, Reference Manager e Origin, alternativamente aos tradicional-mente empregados para esse fim, deu-nos maior liberdade de trabalho, no que diz respeito ao acesso a ferramentas alternativas e de custos muito inferiores às raras ferramentas comerciais de monitoramento existentes. Assim, esperamos que outros pesquisadores dispostos a monitorar suas áreas de atuação possam interessar-se por testar este nosso procedimento.
Wilson Aires Ortiz
E-mail: wortiz@df.ufscar.br.
Sergio Luis da Silva
E-mail: sergiol@power.ufscar.br.
Artigo aceito para publicação em 24-04-2002
ANEXO 01 ANEXO 01
ANEXO 02 ANEXO 02
- FARIA, L. I. L. Informação tecnológica e seleção de materiais:estudo de caso sobre pastilha de freios automotivo. 1995. 192 f. Dissertação (Mestrado) - Departamento de Engenharia de Materiais, Universidade Federal de São Carlos, São Carlos, 1995.
- POTTER, W. G. Lotka's Law revised. Library Trends, v. 30, n. 1, Summer 1981.
- QUONIAN, Luc et al Bibliometri a law used for information retrieval. In: CONFERENCE OF THE INTERNATIONAL SOCIETY FOR SCIENTOMETRICS AND INFORMETRICS, 6th, 1998. Proceedings.. [s. l.] : Hebrow University of Jerusalem., 1998.
- ROSTAING, H. La bibliométrie et ses techniques Toulouse : Sciences de la societé, 1996.
- ________ Veille technologique et bibliométrie: concepts, outils, appplication. 1990. 353 f. Tese (Douorado) - Faculté des Sciences et Techniques de Saint Jérôme, Université de Detroit et des Sciences dÁix-Marseille, Marseille, 1993.
- ROZENFELD, H. at al Development of a concurrente engineering education environment. International Journal of Computer Integrated Manufacturing, v. 13, n. 6, p. 475-482, Nov./Dec. 2000.
- SOTOLONGO-AGUILAR, G.; SUARÉZ-BALSEIRO, C. ; GUZMÁN- SÁNCHEZ, M. Modular bibliométrics information system with proprietary software. [s. l. : s. n.], 1999.
- TOLEDO, J. C. Gestão da mudança da qualidade de produto 1993. Tese (Doutorado) - Escola Politécnica da USP, São Paulo, 1993.
ANEXO 01

ANEXO 02

Datas de Publicação
-
Publicação nesta coleção
03 Abr 2003 -
Data do Fascículo
Set 2002
Histórico
-
Aceito
24 Abr 2002