Resumo
This work describes, through examples, a simple way to carry out experimental design calculations applying an spreadsheets. The aim of this tutorial is to introduce an alternative to sophisticated commercial programs that normally are too complex in data input and output. An overview of the principal methods is also briefly presented. The spreadsheets are suitable to handle different types of computations such as screening procedures applying factorial design and the optimization procedure based on response surface methodology. Furthermore, the spreadsheets are sufficiently versatile to be adapted to specific experimental designs.
spreadsheets; experimental design; chemometrics
spreadsheets; experimental design; chemometrics
DIVULGAÇÃO
Quimiometria II: planilhas eletrônicas para cálculos de planejamentos experimentais, um tutorial
Chemometrics II: spreadsheets for experimental design calculations, a tutorial
Reinaldo F. Teófilo; Márcia M. C. Ferreira* * e-mail: marcia@iqm.unicamp.br
Instituto de Química, Universidade Estadual de Campinas, CP 6154, 13084-971 Campinas - SP
ABSTRACT
This work describes, through examples, a simple way to carry out experimental design calculations applying an spreadsheets. The aim of this tutorial is to introduce an alternative to sophisticated commercial programs that normally are too complex in data input and output. An overview of the principal methods is also briefly presented. The spreadsheets are suitable to handle different types of computations such as screening procedures applying factorial design and the optimization procedure based on response surface methodology. Furthermore, the spreadsheets are sufficiently versatile to be adapted to specific experimental designs.
Keywords: spreadsheets; experimental design; chemometrics.
INTRODUÇÃO
Atualmente, com o advento acelerado dos meios computacionais, cálculos muitas vezes simples podem ficar mascarados quando realizados por pacotes computacionais complexos. Os planejamentos fatoriais1-3, por ex., exigem após sua execução, cálculos simples, mas muitas vezes tediosos devido à grande quantidade de dados a serem processados. A maioria dos estudantes e profissionais aprende a utilizar softwares que realizam tais cálculos, entretanto, em muitos casos, sem o interesse e estímulo necessários para entender como os mesmos são processados.
A importância do entendimento dos procedimentos realizados pelos softwares é fundamental para avaliação dos resultados obtidos, bem como para o questionamento da maneira pelo qual tais softwares os realizam.
Há no mercado diversos tipos de softwares que realizam cálculos de planejamentos experimentais, tais como Statistica4, Unscrambler5, Statgraphics6, Design Expert7, Modde8, Minitab9 dentre outros. Entre os programas gratuitos destaca-se o pacote de algoritmos executáveis disponível no web site Chemkeys10, sendo este até o momento, o único gratuito em português. Nota-se, portanto, que a maioria destes programas não são gratuitos e muitas vezes processam resultados complicados de serem entendidos por um pesquisador inexperiente. Ao contrário, as planilhas eletrônicas, já bastante difundidas e conhecidas, são práticas no sentido da entrada de dados e equações, além de proporcionarem excelente visualização dos resultados, fácil transferência de dados, gráficos e tabelas, sendo ferramentas poderosas para implementar e realizar diferentes tipos de cálculos, como os de planejamentos experimentais. É válido destacar que existem versões gratuitas disponíveis na web tanto para sistemas operacionais Windows quanto para Linux, como a encontrada no pacote Openoffice11.
O objetivo deste trabalho foi desenvolver, de maneira simples e didática, planilhas eletrônicas utilizando-se o software Excel® da Microsoft12 para realizar cálculos de planejamentos fatoriais e otimização empregando Metodologias de Superfície de Resposta (RSM). Desta maneira, o trabalho descreve, de modo amplo e objetivo, os métodos implementados empregando planilhas eletrônicas.
Para a etapa de triagem realizaram-se a estimativa e a avaliação dos efeitos para planejamentos fatoriais completos e fracionários. As estimativas dos erros para estes planejamentos foram obtidas de três maneiras independentes, isto é, empregando replicatas das observações; utilizando os efeitos de altas ordens; ou com a inclusão de experimentos no ponto central. Para a etapa de otimização utilizaram-se os planejamentos compostos centrais e Doehlert, que se baseiam na metodologia de superfície de resposta. Os coeficientes foram obtidos utilizando o método dos quadrados mínimos. O modelo foi avaliado empregando a análise de variância e a estimativa dos erros foi alcançada através de experimentos no ponto central.
Aplicações empregando as planilhas são apresentadas com diversos exemplos, em que todos os métodos são utilizados e a interpretação dos resultados é comentada.
Visto que até o momento, a literatura disponível em português, principalmente destinada a químicos, é bastante escassa, este tutorial enriquece as opções tanto para professores de nível superior e alunos de graduação e pós-graduação, quanto para profissionais da área industrial. Amplia ainda as opções de algoritmos para cálculos empregando tais planejamentos, estando os arquivos disponíveis no web site do Laboratório de Quimiometria Teórica e Aplicada do Instituto de Química da Universidade Estadual de Campinas (UNICAMP)13.
EXPERIMENTOS PARA TRIAGEM
Muitas vezes em um sistema, diversos fatores ou variáveis (os termos fatores e variáveis serão usados neste tutorial indistintamente) podem influenciar a resposta desejada. Um experimento para triagem é executado com o interesse em se determinar as variáveis experimentais e as interações entre variáveis que têm influência significativa sobre as diferentes respostas de interesse3.
Após selecionar as variáveis que são possíveis de serem estudadas e que provavelmente interferem no sistema, é preciso avaliar a metodologia experimental (tempo, custo, etc.). As variáveis que não foram selecionadas devem ser fixadas durante todo o experimento.
Em uma etapa seguinte, deve-se escolher qual planejamento usar para estimar a influência (o efeito) das diferentes variáveis no resultado. No estudo de triagem, as interações entre as variáveis (interações principais) e de segunda ordem, obtidas normalmente pelos planejamentos fatoriais completos ou fracionários, são de extrema importância para a compreensão do comportamento do sistema.
Planejamentos fatoriais completos
Em um planejamento fatorial são investigadas as influências de todas as variáveis experimentais de interesse e os efeitos de interação na resposta ou respostas. Se a combinação de k fatores é investigada em dois níveis, um planejamento fatorial consistirá de 2k experimentos. Normalmente, os níveis dos fatores quantitativos (i.e. concentrações de uma substância, valores de pH, etc.) são nomeados pelos sinais (menos) para o nível mais baixo e + (mais) para o nível mais alto, porém o que importa é a relação inicial entre o sinal dado e o efeito obtido, não sendo um critério definido a nomeação dos sinais. Para fatores qualitativos (i.e. tipos de ácidos, tipos de catalisadores, etc.), como não existem valores altos ou baixos, fica a critério do experimentalista nomear os seus níveis.
Os sinais para os efeitos de interação de 2ª ordem e de ordem superior entre todas as variáveis do planejamento, realizando todas as combinações possíveis, são obtidos pelo produto dos sinais originais das variáveis envolvidas. Desta maneira, é possível construir as colunas de sinais para todas as interações e, assim, elaborar a matriz de coeficientes de contraste (Tabela 1).
Uma coluna de sinais + (mais) é adicionada à esquerda da matriz de coeficientes de contraste para o cálculo da média de todas as respostas observadas.
Suponha um planejamento fatorial com n ensaios e yi observações individuais (quando houver replicatas, considere a resposta média  ). Os efeitos para cada coluna da matriz de coeficientes de contraste (conforme Tabela 1) são dados pelas seguintes Equações:
). Os efeitos para cada coluna da matriz de coeficientes de contraste (conforme Tabela 1) são dados pelas seguintes Equações:

A Equação 1 descreve o efeito para a média de todas as observações, enquanto a Equação 2 descreve o cálculo do efeito para as variáveis e interações usando a diferença entre as médias das observações no nível mais (yi(+)) e as médias das observações no nível menos (yi(-)).
Outro método para cálculo dos efeitos para um planejamento fatorial completo será descrito mais adiante no item Modelos empíricos em estudo de triagem.
Planejamentos fatoriais fracionários
O planejamento fatorial completo necessita de 2k ensaios para sua execução, portanto, sua principal desvantagem é o grande número de ensaios que devem ser realizados a cada fator adicionado ao estudo. Se considerarmos (e observarmos) que os efeitos de altas ordens, principalmente para planejamentos com k > 4, são quase sempre não significativos, a realização de ensaios para estimar tais efeitos de interação pode ser irrelevante. Desta maneira, com um número menor de experimentos, é possível obter informações daqueles efeitos mais importantes e retirar, na maioria das vezes, as mesmas conclusões caso fosse realizado um fatorial completo. Os planejamentos que apresentam estas características são conhecidos como planejamentos fatoriais fracionários1-3,14-16.
Há muitos e diferentes tipos de planejamentos fatoriais fracionários descritos na literatura1-3,14, como, por ex., as frações 1/2, 1/4, 1/8, 1/16...1/2b de um planejamento 2k-b, em que k é o número de variáveis e b é o tamanho da fração. O tamanho da fração influenciará no possível número de efeitos a serem estimados e, conseqüentemente, no número de experimentos necessários3.
Pode-se ainda dizer que há dois tipos de frações: aquelas cujo objetivo é obter somente os efeitos principais14 e aquelas em que se adicionam experimentos para separar e estimar efeitos de interações, caso se assuma que tais interações apresentam influência sobre os resultados.3 No primeiro caso é necessário executar, por ex., apenas 8 experimentos para investigar 7 variáveis, 12 experimentos para 11 variáveis, etc., sendo conhecidos como planejamentos saturados1-3 e planejamentos de Plackett-Burman14.
Construção do planejamento fatorial fracionário
Normalmente, para a construção do planejamento fatorial fracionário desejado, utiliza-se um planejamento fatorial completo. Para exemplificar, consideremos um planejamento 23-1 construído a partir de um planejamento fatorial completo com duas variáveis: V1 e V2. A Tabela 2 apresenta o planejamento fatorial completo com duas variáveis. Serão necessários quatro experimentos para a execução deste planejamento 22 e, a partir dos resultados, podem-se obter os efeitos principais das duas variáveis e o efeito de interação (V1.V2 ). A coluna da matriz de coeficientes de contraste responsável pela interação é obtida pela multiplicação dos elementos da coluna da variável V1 com os respectivos elementos da variável V2. As colunas de V1, V2 e V1V2 da matriz de coeficientes de contraste de um planejamento fatorial completo definem a configuração de um planejamento fatorial fracionário com três variáveis utilizando apenas os quatro ensaios destacados em negrito na Tabela 3, em que V1, V2 e V1V2 serão substituídas pelas variáveis independentes x1, x2 e x3.
Como o número de experimentos é a metade do completo, temos uma meia fração de um planejamento fatorial 23 ( 23 = 2-123= 23-1), conforme as Tabelas 2 e 3.
23 = 2-123= 23-1), conforme as Tabelas 2 e 3.
Uma outra propriedade importante dos planejamentos fatoriais fracionários diz respeito aos experimentos selecionados que cobrem o volume máximo do domínio considerado em um número limitado de experimentos3. Note nas Tabelas 2 e 3 que os experimentos destacados são comuns aos dois planejamentos.
A Figura 1 destaca como os experimentos de meia fração "selecionados" distribuem-se em um domínio experimental para três variáveis (Tabela 3).
Para montagem de um planejamento fatorial fracionário saturado considere o seguinte exemplo: sete variáveis podem ser estudadas, com um mínimo de experimentos, em um planejamento fatorial fracionário com fração 1/16, ou seja, 27-4 ( 27 = 2-427 = 27-4). Para este caso, o planejamento é definido pelo modelo de matriz para um planejamento fatorial 23 (Tabela 3).
27 = 2-427 = 27-4). Para este caso, o planejamento é definido pelo modelo de matriz para um planejamento fatorial 23 (Tabela 3).
Um planejamento fatorial completo com sete variáveis necessita de 128 experimentos. Sendo o planejamento fracionário 27-4, 1/16 do planejamento completo, ele necessitará de somente 8 experimentos.
Neste caso, para elaboração da matriz de planejamento a partir da matriz mostrada na Tabela 3, as variáveis x4, x5, x6e x7 serão os produtos das colunas das variáveis x1x2, x1x3, x2x3e x1x2x3 , respectivamente.
Efeitos confundidos e resolução
Certamente há perda de informações quando se realizam os planejamentos fatoriais fracionários. Os efeitos principais são misturados com os efeitos de interação e esta contaminação aumenta entre as interações, quando se aumenta a fração do planejamento.
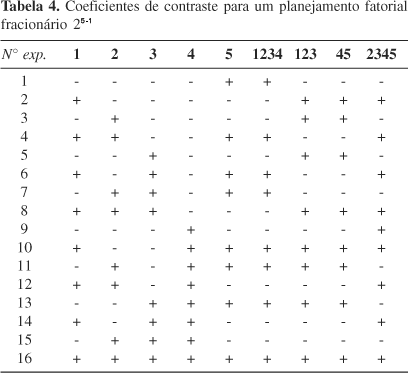
Para entender melhor a confusão causada por esta mistura, considere uma meia fração de um planejamento fatorial 25-1 (Tabela 4). O objetivo é obter todos os efeitos principais e todos os possíveis efeitos de interação realizando apenas 16 ensaios. Uma matriz de planejamento é elaborada a partir de um planejamento 24. A coluna da quinta variável (5) é obtida a partir da multiplicação de todas as outras, ou seja, 1234. Assim, 5 = 1234 é chamado de gerador de um planejamento fracionário1,15. Observa-se pela Tabela 4 que os coeficientes de contraste para o efeito de 123 têm os mesmos sinais de 45. Isto mostra que os efeitos estimados por estas duas interações serão os mesmos, ou seja, serão confundidos, sendo assim chamados de pseudônimo um do outro.
A meia fração do planejamento mostrada na Tabela 4 foi obtida a partir do gerador (5=1234), no entanto, para conhecer a identidade de um pseudônimo é realizada uma definição de contrastes a partir da relação apresentada pela Equação 3

O pseudônimo é obtido multiplicando o definido contraste I por cada um dos efeitos. Por ex., o pseudônimo de 1 é obtido multiplicando 1 por 12345. Considere também, como regra, que se um mesmo termo aparecer mais de uma vez na multiplicação, este termo desaparece. Portanto, 112345 = 2345. Para 12 o pseudônimo é 1212345 = 345.
Se um outro fator F é adicionado ao planejamento 25-1 (Tabela 4) ele passa a ser um planejamento 25-2 e, portanto, um quarto do fatorial completo. Para obter este novo fator, uma outra definição de contrastes é obtida de um gerador adicional. Assim 5 = 1234 e 6 = 123. Portanto, I = 12345 e I = 1236, respectivamente. Uma terceira definição de contrastes é então obtida multiplicando os dois anteriores conforme a Equação 4

O pseudônimo para cada efeito pode agora ser obtido pela maneira usual. Para 1 temos: 1 = 112345 = 11236 = 1456 ou 1 = 2345 = 236 = 1456.
Assim, com um quarto do planejamento 25, cada efeito apresenta três pseudônimos e a estimativa dos efeitos principais é individual, no entanto, eles se confundem com efeitos de interação de 2ª ordem.
Este tipo de confusão pode ocasionalmente causar dificuldades na interpretação, mas isto é facilmente contornado por adição de poucos experimentos complementares, a fim de separar efeitos confundidos.
Um conceito importante em planejamentos fatoriais fracionários é a resolução do planejamento, que define a ordem em que se negligenciam os efeitos e é definida por um número romano colocado depois do planejamento ou subescrito. Em geral, a resolução é o valor do número de fatores que compõem o termo de menor comprimento nas definições de contrastes I1. Para ilustrar:
1. Resolução III Não confunde efeitos principais entre si, mas os confunde com efeitos de interação entre dois fatores.
2. Resolução IV Não confunde efeitos principais entre si e nem com efeitos de interação entre dois fatores, mas confunde efeitos principais com efeitos de interação entre três variáveis e os efeitos entre duas variáveis se confundem com outros efeitos, inclusive entre eles.
3. Resolução V Os efeitos principais são confundidos com efeitos de interação entre quatro variáveis e os efeitos de interação entre duas variáveis são confundidos com efeitos de interação entre três variáveis.
Planejamentos fatoriais fracionários com resolução maior que V são raramente usados em triagem3.
Os cálculos para estimativa dos efeitos para um planejamento fatorial fracionário, serão descritos no item Modelos empíricos em estudo de triagem.
Planejamentos fatoriais com ponto central
Em muitos casos, a realização de repetições autênticas pode ser algo inconveniente por diversas razões. Para contornar este infortúnio e obter uma boa estimativa dos erros, um experimento é normalmente incluído no centro do planejamento (Figura 2), em que o valor médio dos níveis de todas as variáveis é empregado. São os conhecidos experimentos no ponto central (nível zero). Deste modo, é possível avaliar a significância dos efeitos ou coeficientes, tanto em planejamentos de triagem (completos ou fracionários) como em metodologias de superfície de resposta (discutidos mais adiante). Além desta vantagem, recomenda-se este tipo de experimento pelas seguintes razões3: o risco de perder a relação não linear entre os intervalos é minimizado e é possível estimar um modelo razoável e verificar se há falta de ajuste.
Logicamente não há como fugir das repetições, mas o número destas, na maioria dos casos, é significativamente reduzido.
No entanto, esta metodologia é possível de ser aplicada somente quando se utilizam variáveis quantitativas, visto que, para variáveis qualitativas, não há como adicionar níveis no ponto central.
Os cálculos para estimativa de efeitos e coeficientes relacionados aos planejamentos com ponto central serão discutidos no item Modelos empíricos em estudo de triagem.
Modelos empíricos em estudo de triagem
Pode-se assumir, desde o início do experimento, que o sistema estudado (domínio experimental) é regido por alguma função que é descrita pelas variáveis experimentais. Normalmente esta função pode ser aproximada por um polinômio, o qual pode fornecer uma boa descrição entre os fatores e a resposta obtida. A ordem deste polinômio é limitada pelo tipo de planejamento usado. Planejamentos fatoriais de dois níveis, completos ou fracionários, podem estimar apenas efeitos principais e interações. Planejamentos fatoriais de três níveis (ponto central) podem estimar, além disso, o grau de curvatura na resposta.
Para descrever tais modelos em um estudo de triagem, são utilizados os polinômios mais simples, ou seja, aqueles que contêm apenas termos lineares. Considerando um exemplo para três variáveis, x1, x2 e x3, dois polinômios seriam:

Segundo a Equação 5, o coeficiente b0 é o valor populacional da média de todas as respostas obtidas, b1, b2 e b3 são os coeficientes relacionados com as variáveis x1, x2, e x3, respectivamente, e é o erro aleatório associado ao modelo e, para o caso da Equação 6, b12, b13, b23 são os coeficientes para as interações x1x2, x1x3,x2x3 e b123 é o coeficiente para a interação x1x2x3.
A partir do planejamento montado, pode-se construir a matriz de coeficientes de contraste, de acordo com a Tabela 1. A matriz de coeficientes de contraste X, juntamente com o vetor de respostas y, obtido experimentalmente, será utilizada para cálculo dos coeficientes do modelo, conhecidos também como vetor de regressão.
O modelo procurado, descrito pelas Equações 5 e 6 pode ser representado matricialmente pela Equação 7

em que  é o vetor das respostas estimadas pelo modelo e b o vetor de regressão.
é o vetor das respostas estimadas pelo modelo e b o vetor de regressão.
Uma maneira de determinar o vetor de regressão b é através do método dos quadrados mínimos17,18, definido pela Equação 8, em que Xt indica a transposta de X

(XtX)-1 é a matriz inversa do produto da transposta da matriz X com ela mesma.
Para um planejamento fatorial completo, a matriz
X é quadrada e ortogonal, onde n corresponde ao número de ensaios. Isto ocorre pois as colunas de X não estão normalizadas, portanto X-1 =
 Xt. Neste caso, a Equação 8 se resume à Equação 9
Xt. Neste caso, a Equação 8 se resume à Equação 9

A Equação 8 é geral e pode ser empregada para se fazer a estimativa de efeitos e coeficientes para todos os planejamentos descritos neste artigo, no entanto a Equação 9 é específica para o planejamento fatorial completo, não sendo aplicável aos outros planejamentos descritos.
Como as variáveis são estudadas em dois níveis codificados, cada efeito satisfaz à variação de duas unidades da variável correspondente. Se considerarmos os fatores individualmente, pode-se provar que o valor de cada coeficiente do modelo é a metade do valor do efeito correspondente, exceto para b0, cujo valor é o mesmo do calculado para seu efeito (Equação 1). Desta maneira, o modelo empregado para descrever as respostas é elaborado em função dos efeitos por unidade de variação individual2.
Estimativa dos erros para os efeitos através de repetições
Normalmente, os resultados obtidos em experimentos de planejamento fatorial completo ou fracionário com repetições consistem de uma pequena amostra de um hipotético conjunto maior, representado por uma população. Destes dados podemos obter a média amostral, a variância amostral e o desvio padrão amostral, como se segue:

em que r é o número de replicatas, isto é, o número de ensaios realizados em um mesmo ponto experimental (nível), yi são os valores de cada observação individual, é o valor médio, s2 é a variância e s o desvio padrão.
A soma dos desvios da média amostral de r replicatas é necessariamente zero. Isto requer que å ( yi -  ) = 0 constitua uma restrição linear nos desvios usados no cálculo de s2. Está subentendido que com r 1 replicatas é possível determinar a que falta. Os r resíduos y - e, conseqüentemente, a soma dos seus quadrados juntamente com a variância amostral são ditas ter, por esta razão, r 1 graus de liberdade. A perda de um grau de liberdade está associada à necessidade de substituir a média populacional pela média amostral derivada dos dados. Desta maneira, quando repetições genuínas são realizadas em uma série de condições experimentais, a variação entre suas observações pode ser usada para estimar o desvio padrão de uma simples observação e, conseqüentemente, o desvio dos efeitos1. Todos os ensaios, inclusive repetições, devem ser realizados aleatoriamente, refazendo todas as etapas do experimento. As repetições realizadas desta maneira são consideradas genuínas.
) = 0 constitua uma restrição linear nos desvios usados no cálculo de s2. Está subentendido que com r 1 replicatas é possível determinar a que falta. Os r resíduos y - e, conseqüentemente, a soma dos seus quadrados juntamente com a variância amostral são ditas ter, por esta razão, r 1 graus de liberdade. A perda de um grau de liberdade está associada à necessidade de substituir a média populacional pela média amostral derivada dos dados. Desta maneira, quando repetições genuínas são realizadas em uma série de condições experimentais, a variação entre suas observações pode ser usada para estimar o desvio padrão de uma simples observação e, conseqüentemente, o desvio dos efeitos1. Todos os ensaios, inclusive repetições, devem ser realizados aleatoriamente, refazendo todas as etapas do experimento. As repetições realizadas desta maneira são consideradas genuínas.
Em um experimento em que cada ensaio foi realizado r vezes, se o valor de r for pequeno, por exemplo, 2 < r <10, haverá poucos graus de liberdade para o cálculo da variância. Uma maneira para se obter um maior número de graus de liberdade é realizando uma estimativa conjunta das variâncias, conforme a Equação 13

O resultado da Equação 13 reflete a variância conjunta ( ) de cada observação individual yi sendo o erro padrão igual à raiz quadrada do mesmo. A Equação 14, que é exatamente o denominador da Equação 13 é, portanto, o número de graus de liberdade da estimativa conjunta, designada como n.
) de cada observação individual yi sendo o erro padrão igual à raiz quadrada do mesmo. A Equação 14, que é exatamente o denominador da Equação 13 é, portanto, o número de graus de liberdade da estimativa conjunta, designada como n.
Observa-se através das Equações 1 e 2 e considerando a realização de repetições autênticas, que cada efeito é uma combinação linear dos valores de yi dos n ensaios, com coeficientes c iguais a + 2/n e -2/n. Levando em consideração a aleatoriedade dos ensaios, tais valores são estatisticamente independentes e apresentam a mesma variância populacional s2. Neste caso, por definição, as correlações entre todas as variáveis são nulas, e a variância da combinação linear das variáveis aleatórias pode ser dada por2

Transportando a Equação 15 para o nosso mundo amostral, pode-se provar que a variância de cada efeito é dada por1

em que é dada pela Equação 13 e ri é o número de replicatas em cada ensaio n.
E, finalmente, para calcular o valor do erro de cada efeito, basta extrair a raiz quadrada de V(ef).
Estimativa dos erros para os efeitos, sem repetições
Uma maneira de estimar erros de efeitos sem a realização de repetições é supor que interações de altas ordens para k> 3 não são significativos e, portanto, são erros experimentais nos valores dos efeitos2.
Aplicando a Equação 13 sobre estes efeitos de interação e fazendo algumas considerações, obtém-se a variância dos efeitos conforme a Equação 17

em que efii são os efeitos de interação considerados como erros experimentais e l é o número total de efeitos considerados.
É preciso estar atento ao utilizar este tipo de estimativa do erro. Nem sempre os efeitos de altas ordens são irrelevantes e, se tais efeitos forem incluídos no cálculo, os erros tornam-se altos e, desta maneira, não é possível distinguir com confiabilidade aqueles que são realmente importantes.
O número de graus de liberdade utilizado para avaliação dos efeitos agregados a estes erros é o mesmo número total de efeitos considerados como erros, isto é, o valor l da Equação 17.
Encorajamos o leitor interessado a ler as ref. 16 e 19 que apresentam outros métodos de identificação de efeitos significativos sem a realização de repetições.
Estimativa dos erros para os efeitos e coeficientes a partir das repetições no ponto central
Conforme mencionado anteriormente, uma das grandes vantagens da inclusão de experimentos no centro do planejamento é devida à estimativa do erro com poucas repetições, normalmente entre 3 e 5.
A partir das repetições realizadas é possível obter a média e a variância das replicatas de acordo com as Equações 10 e 11, respectivamente.
Por outro lado, sendo os coeficientes obtidos através da Equação 8, nota-se que a matriz (XtX)-1 apresenta grande influência na variância dos parâmetros de regressão. O produto desta matriz com o valor da variância obtida através das repetições no ponto central (Equação 11) fornece a matriz V(b) conhecida como matriz de variância-covariância (Equação 18). A matriz V(b) é simétrica e os elementos de sua diagonal são as variâncias dos parâmetros de regressão, na mesma ordem em que elas aparecem na equação de regressão. Os elementos fora da diagonal são as covariâncias entre os parâmetros de regressão. A raiz quadrada dos elementos da diagonal principal da matriz V(b) determina os valores correspondentes dos erros padrão (sbi) dos coeficientes calculados (Equação 19).

Identificação dos efeitos e coeficientes significativos
Na literatura1-3,15,16 há diferentes métodos para se avaliar efeitos e coeficientes significativos; entre os mais usados destaca-se a análise de variância (ANOVA), o gráfico de probabilidade normal (distribuição normal) e a comparação de efeitos com uma medida independente da variabilidade. Neste trabalho, as avaliações de significância para a decisão estatística, tanto para efeitos como para coeficientes de modelos, foram realizadas empregando o teste t (distribuição de Student), através do valor p20,21.
Para realizar a interpretação correta utilizando o valor p é necessário compreender os testes de hipótese e significância, conforme descrito abaixo.
Em muitos casos, formula-se uma hipótese estatística com o propósito de rejeitá-la ou invalidá-la. Por ex., se o desejo é decidir se um sistema é diferente de outro, formula-se a hipótese de que não há diferença entre os sistemas. Essa hipótese é denominada nula e representada por H0. Qualquer hipótese diferente da pré-fixada é denominada hipótese alternativa e é normalmente representada por H121.
Se uma hipótese for rejeitada quando deveria ser aceita, diz-se que foi cometido um erro tipo I. Se, por outro lado, uma hipótese for aceita quando deveria ter sido rejeitada, diz-se que foi cometido um erro do tipo II. Em ambos os casos foi tomada uma decisão errada ou foi cometido um erro de julgamento21,22.
Para que qualquer teste de hipótese ou regra de decisão seja adequada, eles devem ser planejados de modo que os erros de decisão sejam reduzidos ao mínimo.
Ao testar uma hipótese estabelecida, a probabilidade máxima, representada freqüentemente por a, com a qual se sujeitaria a correr o risco de um erro do tipo I é denominada nível de significância do teste.
Se, por ex., é escolhido um nível de significância 0,05 ou 5%, há então cerca de 5 chances em 100 da hipótese nula ser rejeitada, quando deveria ser aceita, isto é, há uma confiança de 95% de que se tomou uma decisão correta. Nesses casos, diz-se que a hipótese é rejeitada ao nível de significância 0,05, o que significa que a probabilidade de erro seria de 0,05 22.
Considerando a hipótese nula de que o valor do efeito se confunde com seu erro, pode-se formular a seguinte regra de decisão:
a) rejeição da hipótese nula com 5% de significância, quando o valor de tcalc situar-se fora do intervalo entre ± ta ( |tcalc|> ta ). Isso equivale a dizer que o valor estatístico amostral observado é significativo no nível definido e,
b) aceitação da hipótese, caso contrário.
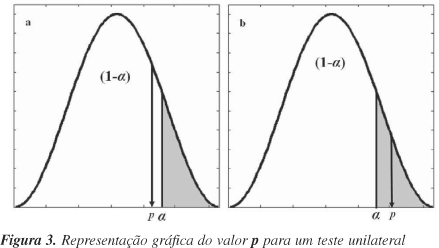
Uma maneira alternativa de concluir o teste de hipótese é comparar o valor p do teste estatístico amostral com o nível de significância a. O valor p do teste estatístico amostral é o menor nível de significância para que se rejeite H020. Neste sentido, compara-se o valor p com a e, se o valor p < a rejeita-se H0, caso contrário H0 é aceito. A vantagem de se conhecer o valor p está na possibilidade de se avaliar todos os níveis de significância para que o resultado observado possa ser estatisticamente rejeitado20-21. A representação gráfica do valor p é descrita na Figura 3.
Conforme as Figuras 3(a e b), o nível de significância a é a área hachurada no gráfico de distribuição. Na Figura 3a a área correspondente ao valor p é maior que o nível de significância, portanto, o valor calculado do teste estatístico está fora da região crítica, o que implica em aceitar H0. Para a Figura 3b a área do valor p é menor que o nível de significância e assim, o valor calculado do teste estatístico está dentro da região crítica, o que implica em rejeitar H0. É importante ressaltar que esta discussão é válida tanto para testes unilaterais quanto para bilaterais.
Especificamente, o valor p representa a probabilidade de validade do erro envolvido no resultado observado, isto é, como representativo da população4. Por ex., levando em consideração o valor de um efeito, se o valor do teste estatístico calculado (razão entre o efeito e seu erro) apresentar um grande desvio da distribuição de Student, ele provavelmente descreve algo mais que o resíduo experimental. Desta maneira, será significativo dentro de um intervalo de confiança e assim, |tcalc|> ta ou p < a, para o número de graus de liberdade em questão.
METODOLOGIA DE SUPERFÍCIE DE RESPOSTA: OTIMIZAÇÃO
Após a realização dos experimentos de triagem, os fatores significativos são selecionados e uma metodologia de análise de superfícies de respostas pode ser executada para otimização do experimento. Neste sentido, otimizar significa encontrar os valores das variáveis que irão produzir a melhor resposta desejada, isto é, encontrar a região ótima na superfície definida pelos fatores.
A metodologia de superfície de resposta baseia-se na construção de modelos matemáticos empíricos que geralmente empregam funções polinomiais lineares ou quadráticas para descrever o sistema estudado e, conseqüentemente, dão condições de explorar (modelar e deslocar) o sistema até sua otimização.
Um planejamento experimental construído para estimar coeficientes, segundo algum modelo aproximado, deve reunir certos critérios desejáveis, sendo os principais17,18: proporcionar boas estimativas para todos os coeficientes, exigindo poucos experimentos e, fornecer condições de avaliação dos coeficientes e do modelo, ou seja, da regressão e da falta de ajuste.
Neste trabalho serão descritos os Planejamentos, Composto Central "CCD - Central Composite Design"23 e Doehlert24, que possivelmente são as classes de planejamentos mais utilizadas para ajustar modelos quadráticos (Equação 20), visto que apresentam todos os critérios descritos acima, dentre outros.

em que k é o número de variáveis.
Planejamento composto central
Os planejamentos compostos centrais (CCD) foram apresentados por Box e Wilson23, em 1951, como uma evolução dos planejamentos 33, que necessitavam de muitos experimentos para um pequeno número de fatores, mesmo para planejamentos fracionários. Outras vantagens, como rotabilidade e blocagem ortogonal, além do pouco número de ensaios, foram obtidas devido à presença das seguintes partes no planejamento17,18:
 . Estes pontos são situados nos eixos do sistema de coordenadas com distância ± a da origem e formam a parte estrela do planejamento.
. Estes pontos são situados nos eixos do sistema de coordenadas com distância ± a da origem e formam a parte estrela do planejamento.A Figura 4 ilustra os pontos experimentais no sistema de coordenadas definidas pelos eixos xi.
Para construção de um planejamento CCD é necessário definir o número de variáveis a serem estudadas (k), qual planejamento fatorial será empregado (completo 2k ou fracionário 2k-b) e quantos experimentos serão realizados no ponto central (2k). O número de experimentos a ser realizado é dado por 2k+2k+1. A Tabela 5 descreve como o valor de a varia com o número de variáveis17,18 e a Tabela 6 apresenta as matrizes de planejamento para 2 e 3 variáveis.
Observe que neste tipo de planejamento, os níveis a (o mesmo vale para qualquer valor codificado xi) necessitam ser decodificados para os valores experimentais dos níveis das variáveis a serem estudadas e para isso utiliza-se a Equação 21

em que xi é o valor codificado do planejamento CCD, zi o valor experimental do nível,  o valor médio entre os níveis mais (+) e menos (-), que é exatamente o valor do nível zero (0) e Dz é a diferença entre os níveis mais (+) e menos (-).
o valor médio entre os níveis mais (+) e menos (-), que é exatamente o valor do nível zero (0) e Dz é a diferença entre os níveis mais (+) e menos (-).
Vale ressaltar também, que é aceitável o ajuste de a a um valor experimentalmente viável para o nível, desde que não ocorram grandes distorções no valor original.
Utilizando a Tabela 5 podem-se construir diferentes tipos de planejamentos CCD, conforme aqueles apresentados na Tabela 6. A partir do planejamento montado, pode-se obter a matriz de coeficientes de contraste, de acordo com a Tabela 1. O modelo apresentado na Equação 20 pode ser representado matricialmente segundo a Equação 7 e seus coeficientes são estimados através da Equação 8.
A estimativa dos erros para os coeficientes a partir das replicatas no ponto central é realizada conforme as Equações 18 e 19 e a avaliação dos coeficientes é realizada conforme o item Identificação dos efeitos e coeficientes significativos, descrito anteriormente.
Matriz Doehlert
O planejamento Doehlert ou Matriz Doehlert foi apresentado por David H. Doehlert em 197024, sendo uma alternativa bastante útil e atrativa aos planejamentos experimentais de segunda ordem. Os pontos da matriz Doehlert correspondem aos vértices de um hexágono gerado de um simplex regular e, em geral, o número total de pontos experimentais no planejamento é igual a k2+k+pc, em que k é o número de fatores e pc é o número de experimentos no ponto central. Uma importante propriedade do planejamento Doehlert diz respeito ao número de níveis que cada variável possui. Com quatro variáveis, por ex., o número de níveis é 5, 7, 7 e 3, o que permite avaliar as variáveis consideradas mais importantes, ou seja, que apresentam efeitos mais pronunciados em um número maior de pontos do espaço estudado25. Além disso, este tipo de planejamento necessita de um menor número de experimentos em relação ao planejamento composto central sendo, portanto, mais eficiente. Esse menor número de experimentos para se chegar à região ótima vem do fato de que o domínio da vizinhança é facilmente explorado pelo ajuste de poucos experimentos, já que o próximo hexágono utiliza pontos experimentais já explorados pelo hexágono anterior, conforme Figura 5 3.
O planejamento Doehlert descreve um domínio circular para duas variáveis, esférico para três e hiperesférico para mais de três variáveis, o que acentua a uniformidade no espaço envolvido. Embora suas matrizes não sejam ortogonais nem rotacionais, elas não apresentam divergências significativas que comprometam a qualidade necessária para seu uso efetivo26. Para duas variáveis, a matriz Doehlert consiste de um ponto central e mais seis pontos adicionais formando um hexágono regular e, por esse motivo, situada sob um círculo (Figura 5). As matrizes do planejamento Doehlert para duas, três e quatro variáveis podem ser visualizadas na Tabela 7. As matrizes Doehlert apresentadas na Tabela 7 são pré-estabelecidas e suas construções não são triviais como os outros planejamentos apresentados neste trabalho. Mais detalhes sobre a construção deste tipo de matriz podem ser obtidos nas refs. 24 e 27.
Cada planejamento é definido considerando o número de variáveis e os valores codificados (xi) da matriz experimental. A relação entre os valores experimentais e os valores codificados é dada pela Equação 22

O termo xi é o valor codificado para o nível do fator i; zi é o seu experimental; Dzi é a distância entre o valor experimental no ponto central e o experimental no nível superior ou inferior, bd é o maior valor limite codificado na matriz para cada fator (na coluna x2b da Tabela 7, por ex., bd = 0,866) e z 0i é o valor experimental no ponto central.
A maioria dos pacotes computacionais disponíveis atualmente, comerciais ou gratuitos, ainda não disponibilizou algoritmos para cálculos de planejamentos Doehlert sendo, portanto, um indicativo dentre outros, de que este planejamento está relativamente pouco difundido entre os pesquisadores.
Avaliação do modelo
O modelo obtido pode não ser exatamente aquele que descreve a região estudada do sistema e, neste caso, não pode ser usado para fazer estimativas para deslocamento e muito menos para extrair conclusões sobre a região ótima. A maneira mais confiável de se avaliar a qualidade do ajuste do modelo é empregando a análise de variância (ANOVA)21.
Na ANOVA a variação total da resposta é definida como a soma quadrática de dois componentes: a soma quadrática da regressão (SQregr) e a soma quadrática dos resíduos (SQres). A soma quadrática da variação total, corrigida para a média (SQtotal) pode, assim, ser escrita como a Equação 23

em que SQregr e SQres são apresentadas com mais detalhes nas Equações 24 e 25, respectivamente.

Da Equação 24, m é o número total de níveis do planejamento, isto é, pontos experimentais do planejamento;  é o valor estimado pelo modelo para o nível i e é o valor médio das replicatas (r). No entanto, como há somente replicatas no ponto central, a média das replicatas nos níveis (+) mais e (-) menos é o próprio valor observado do ensaio naquele nível. Note que o segundo somatório indica que se deve fazer o quadrado das diferenças inclusive com cada repetição.
é o valor estimado pelo modelo para o nível i e é o valor médio das replicatas (r). No entanto, como há somente replicatas no ponto central, a média das replicatas nos níveis (+) mais e (-) menos é o próprio valor observado do ensaio naquele nível. Note que o segundo somatório indica que se deve fazer o quadrado das diferenças inclusive com cada repetição.
As replicatas realizadas no ponto central deixarão um resíduo para cada observação yi. A soma quadrática destes resíduos fornece a soma quadrática residual somente no nível zero.
A Equação 25 indica que o quadrado da diferença entre o valor de cada observação (yi) e o valor estimado () e, inclusive das replicatas (yj) em cada nível (m), fornece a soma quadrática residual de todos os níveis.
Quando algum modelo é ajustado aos dados, a soma quadrática do erro puro é sempre uma parte da soma quadrática dos resíduos. Então, cada resíduo pode ser desmembrado em duas partes18, isto é

Pela Equação 26, o primeiro termo da direita diz respeito à diferença entre o valor de cada observação individual no nível e a média de todas as observações naquele nível. Já o segundo termo corresponde à diferença entre o valor estimado no nível e a média de todas as observações naquele nível. A subtração entre estes dois termos fornece como resposta o resíduo de cada observação individual.
Para evitar os termos negativos na Equação 26, tomam-se as suas diferenças quadráticas e obtém-se Equação 27

O primeiro termo da direita é chamado de soma quadrática do erro puro e está relacionado exclusivamente com os erros aleatórios das replicatas. Já o segundo termo da direita é chamado de soma quadrática da falta de ajuste, pois ele é uma medida da discrepância entre a resposta do modelo de previsão () e a média das replicatas (i) realizadas no conjunto de condições experimentais18.
A Equação 27 pode ser resumida da seguinte maneira

Para cada fonte de variação (regressão, resíduos, falta de ajuste, erro puro e total), é necessário obter o número de graus de liberdade. Não introduzindo detalhes, pode-se provar que o número de graus de liberdade para as Equações 24, 25 e 27 são p 1, n p e (n m) + (m p), respectivamente1-2,18,26, em que p é o número de parâmetros (coeficientes) do modelo, n é o número total de observações (ensaios) e m é o número de níveis do planejamento. O número de graus de liberdade para as outras fontes de variação pode ser obtido por cálculos algébricos simples.
A divisão da soma quadrática de cada fonte de variação pelo seu respectivo número de grau de liberdade fornece a média quadrática (MQ). A razão entre a média quadrática da regressão (MQreg) pela média quadrática dos resíduos (MQres), que nada mais é do que a razão entre duas variâncias, pode ser usada para comparar tais fontes de variação através do teste F (distribuição de Fisher), levando em consideração seus respectivos números de graus de liberdade. O mesmo pode ser feito para a razão entre a média quadrática da falta de ajuste (MQfaj) pela média quadrática do erro puro (MQep).
Assim, como foi realizada a avaliação dos efeitos e coeficientes empregando o teste t, através do valor p, o mesmo será feito para comparar as duas fontes de variação entre si, empregando-se neste caso o teste F (Equação 29)

em que MQ1 e MQ2 são as médias quadráticas das fontes de variação 1 e 2, respectivamente, e n1,n2 são seus respectivos números de graus de liberdade.
Exemplificando, a razão entre as médias quadráticas da falta de ajuste e do erro puro é o valor calculado do teste estatístico (Fcalc), que é usado para comparar qual é mais significativo. Pode-se formular uma hipótese nula (H0) considerando que não há diferença entre as fontes de variação comparadas. Esta hipótese se reflete na seguinte regra de decisão:
a) rejeição da hipótese nula com 5% de significância, quando o valor de Fcalc se situar fora do intervalo definido por Fa (|Fcalc| > Fa), ou seja, p<a. Isso equivale a dizer que o valor estatístico amostral observado é significativo no nível definido e as fontes de variação comparadas são diferentes.
b) Aceitação da hipótese nula, caso contrário.
Se H0 for rejeitada para MQfaj/MQep, isto é, p <a, então há uma falta de ajuste significativa ao nível de probabilidade e número de graus de liberdade definidos (normalmente, a = 0,05) e o modelo não é adequado.
Em termos práticos, um bom modelo necessita ter uma regressão significativa e uma falta de ajuste não significativa. Isto equivale a dizer que a maior parte da variação total das observações em torno da média deve ser descrita pela equação de regressão e o restante certamente, ficará com os resíduos. Da variação que fica com os resíduos é esperado que a maior parte fique com o erro puro, que é o erro experimental, e não com a falta de ajuste, que está diretamente relacionada com o modelo.
Outros parâmetros para observar se toda variação em torno da média foi explicada pela regressão são o valor do coeficiente de variação R2 (Equação 30) e o gráfico dos resíduos2.
O valor de R2 representa a fração da variação que é explicada pela falta de ajuste do modelo (Equação 30). Quanto mais próximo de 1 o valor do coeficiente estiver, melhor estará o ajuste do modelo às respostas observadas.

Note que o erro puro não explica nada do modelo, então o valor máximo possível de R2 é

A análise de variância (ANOVA), de acordo com as Equações descritas para avaliação do modelo, está resumida na Tabela 8.
Uma boa prática é examinar a distribuição dos resíduos, pois ajuda a verificar se não há nada de errado com o modelo. Neste caso, pode-se fazer um gráfico dos valores estimados pelo modelo () com os valores da diferença entre os valores observados experimentalmente (yi) e seus respectivos valores estimados, isto é, () versus (yi ). Se os resíduos não estiverem aleatoriamente distribuídos, pode-se desconfiar do modelo e investir em outros recursos para sua melhoria.
MATERIAIS E MÉTODOS
As planilhas foram elaboradas no software Excel da Microsoft Office 200312 e testadas nas versões 2000 e XP deste mesmo software. Testou-se a compatibilidade de software empregando a planilha eletrônica de domínio público disponível no pacote Openoffice 1.1.111 instalado nos sistemas operacionais Windows 98 SE12 e Linux Fedora Core 228. Todos os outros testes foram realizados em sistemas operacionais Windows 98 SE, XP e 200012. Para testes de processamento empregaram-se os computadores pessoais com processadores Pentium II e AMD Duron com 64 MB de memória RAM. Os cálculos foram validados através dos softwares Matlab 6.529 e Statistica 6.030.
EXEMPLOS
Recomenda-se para melhor entendimento, realizar o download dos arquivos referente às planilhas descritas neste tutorial na página http://lqta.iqm.unicamp.br e utilizá-las para executar os exemplos.
Serão apresentadas neste tutorial, três aplicações que exemplificarão estudos de triagem utilizando os planejamentos fatoriais completos, fatoriais fracionários e fatoriais com ponto central e, para a otimização, será descrito um planejamento composto central. De maneira geral, estes exemplos podem ser usados como referências para construção, cálculo e interpretação dos resultados para estudos que empreguem tais planejamentos.
Outras planilhas, além das apresentadas nos exemplos, podem ser encontradas no mesmo web site, inclusive para o planejamento Doehlert, não exemplificado aqui.
Em todos os arquivos, as matrizes de contrastes podem ser observadas deslocando a barra de rolagem para a direita na parte inferior da janela e todas as equações inseridas podem ser visualizadas clicando sobre a célula de interesse.
Exemplo 1: Planejamento fatorial completo
Os arquivos necessários para este exemplo são planejamentos fatoriais completos (fatorial 1.4) e planejamentos fatoriais completos com ponto central (fatpc 1.1).
Será descrito o planejamento fatorial completo com ponto central utilizado por Arambarri et al.31. Os autores tinham como objetivo aprimorar a determinação analítica de estanho (Sn) total em solução ácida de sedimentos após digestão. A determinação foi executada em extratos de água régia/HF usando a eficiência do paládio como modificador químico. As variáveis e níveis investigados na etapa de triagem com o objetivo de definir o domínio experimental são apresentados na Tabela 9. Foi executado um planejamento de dois níveis com quatro variáveis, ou seja, 24=16 experimentos. A resposta estudada foi a absorbância.
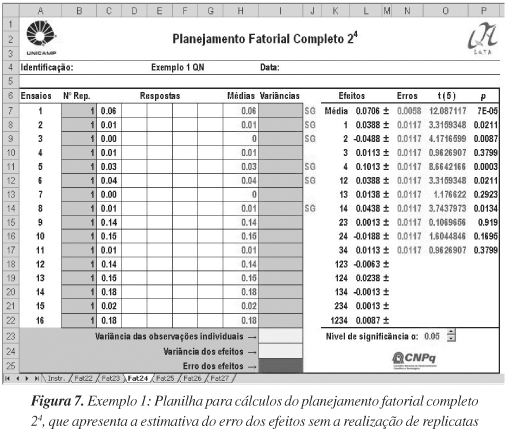
Como se optou pela não realização de repetições de todos os experimentos, os autores tinham várias alternativas de fazer a estimativa conjunta do erro. A escolhida foi a realização de três replicatas no ponto central (Figura 6), que realmente consistiu de uma escolha adequada; no entanto, uma outra maneira seria não realizar repetição alguma e estimar os erros a partir dos efeitos de altas ordens, conforme apresentado na Figura 7.
Os autores optaram também por divulgar os resultados dos efeitos calculados na forma de uma ANOVA, entretanto outras maneiras podem ser utilizadas, como aquelas apresentadas nas Figuras 6 e 7.
Observe que os resultados que apresentam os efeitos ou coeficientes significativos são idênticos para as duas planilhas, no entanto, diferenças de resultados podem ocorrer e, certamente, o planejamento em que se utilizaram replicatas no ponto central é relativamente mais confiável. Os graus de liberdade são apresentados nas planilhas entre parênteses junto ao t de Student.
O cálculo dos coeficientes realizado pela planilha apresentada na Figura 6 mostra apenas os coeficientes principais e suas interações até 2ª ordem. Na realidade, cálculos prévios foram realizados em outra planilha considerando todos os coeficientes principais e de interações. Observou-se, porém, que os coeficientes de interação de 3ª e 4ª ordem não eram significativos e, assim, o cálculo destes coeficientes não é necessário e não foi realizado na planilha apresentada. Neste caso o número de parâmetros (p) diminuiu de 14 para 11, o que tem uma grande influência sobre a ANOVA pois, ao mesmo tempo em que o valor da média quadrática da regressão aumenta, o valor da média quadrática dos resíduos diminui, o que contribui ainda mais para a significância do modelo, além de torná-lo mais simples.
Pode-se concluir finalmente, que as variáveis Tpir, Tatom e Cmod nos níveis estudados são significativas a 95% de confiança, enquanto que a variável Vmod não apresentou influência no sistema e pode ser fixada em qualquer valor entre os dois níveis. Normalmente ela é fixada naquele valor que apresenta menor custo. O valor do efeito da variável Tatom é negativo, revelando que a passagem do nível menos (-) para o nível mais (+) desta variável contribui para uma queda na resposta e, portanto, deve-se estudar a região do nível mais baixo visto que o interesse é a maior resposta. Além disso, as interações TpirxTatom e TpirxCmod são significativas e positivas. Pode se concluir, considerando as interações individualmente, que se obtém uma maior resposta quando se trabalha simultaneamente no nível mais (+) das duas variáveis. No entanto, para um caso específico, recomenda-se avaliar os gráficos de médias marginais32 (não discutido neste trabalho), para uma avaliação mais criteriosa das interações de segunda ordem.
Pela ANOVA, pôde-se observar que o modelo linear apresentou um bom ajuste e regressão significativa, no entanto, como o objetivo é otimizar a resposta, um deslocamento para a região ótima foi executado através de um planejamento composto central, estudando agora, somente as três variáveis significativas. O leitor interessado poderá obter os resultados finais buscando o trabalho completo dos autores, disponível na referência citada.
Exemplo 2: Planejamento fatorial fracionário
O arquivo necessário para este exemplo é o fracpc 1.0, que contém o planejamento fatorial fracionário empregado neste exemplo.
Será descrito o planejamento fatorial fracionário utilizado por Dron et al.33.
Os autores tinham como objetivo adequar a microextração por fase sólida com "headspace" (HS-SPME) para determinação de metil terc-butil éter (MTBE) usando cromatografia gasosa com detecção de ionização em chama (FID). Planejamentos experimentais foram aplicados para determinar as variáveis significativas e otimizar o processo de HS-SPME de MTBE em água. As variáveis e níveis investigados na etapa de triagem são apresentados na Tabela 10, com o objetivo de definir o domínio experimental. Foi executado um planejamento de dois níveis e cinco variáveis com resolução III, ou seja, 25-2 experimentos. A resposta investigada foi a área do pico. Os autores realizaram três replicatas no ponto central para realizar a estimativa do erro (Figura 8).
De acordo com a Figura 8, os contrastes principais C2 e C5 e os contrastes de interação C25 e C124 são significativos a 95% de confiança. No contraste C2, ocorre a mistura da variável principal X2 com as interações X1X4 e X3X4X5. Observando que as variáveis X1, X3 e X4 não são significativas e apresentam baixos valores de efeito, certamente o valor do contraste é devido somente à influência da variável X2. Da mesma maneira, o valor do contraste C5 também pode ser considerado como resultado da influência da variável X5. O contraste C25 confirma o quanto as variáveis X2 e X5 são significativas. Já o contraste C124, seguramente, levando em consideração sua alta ordem, é significativo devido à presença da variável X2 em sua interação. Conclui-se, portanto, que as variáveis Temp e Sal são as mais importantes no processo da microextração de MTBE nas condições estudadas. As variáveis Time, Agit e HSvol não apresentaram efeitos significativos e devem ser fixadas em um nível entre os estudados.
Ressalta-se aqui o ganho de tempo que os resultados deste procedimento proporcionaram para a análise, além da minimização do consumo de reagentes e da geração de resíduos.
Os autores, interessados em otimizar a microextração, executaram o planejamento composto central com as duas variáveis mais importantes obtidas na etapa de triagem.
Os resultados finais deste estudo podem ser encontrados no trabalho completo dos autores, na referência citada.
Exemplo 3: Planejamento composto central
O arquivo necessário para este exemplo é o CCD 1.0, que contém a planilha utilizada neste estudo.
A metodologia de superfície de resposta é exemplificada utilizando o trabalho desenvolvido por Kukreja et al.34.
Os autores tinham como objetivo estabilizar a relação funcional entre os fatores (conteúdo de negro-de-fumo e óleo vegetal) e várias propriedades como tempo de cura, dureza, módulo de elasticidade, resistência à tração, resistência ao rasgo e ruptura no alongamento. O ótimo seria encontrar o nível de óleo vegetal no composto de maneira que tal nível contribuisse como um agente de acoplamento entre a interface negro-de-fumo borracha. Neste caso, os autores obtiveram várias respostas para um mesmo planejamento, o que contribuiu para a otimização simultânea das propriedades em uma mesma região experimental.
Como havia apenas dois fatores a serem estudados, a otimização, empregando o planejamento composto central, foi realizada sem a passagem pela etapa de triagem. Com duas variáveis, conforme Tabelas 6 e 7, são necessários quatro experimentos no planejamento fatorial, quatro experimentos nos pontos axiais e os autores optaram pela realização de duplicatas no ponto central, portanto, dez resultados experimentais foram necessários para cada propriedade.
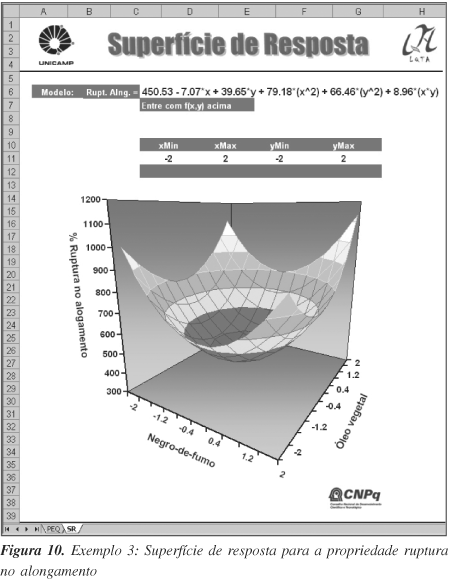
Neste trabalho, os autores não disponibilizaram diretamente as respostas obtidas para cada propriedade, porém, eles forneceram os valores dos coeficientes dos modelos e o planejamento usado. Empregando a Equação 8 é possível calcular as respostas obtidas e, para fins de exemplificação, foram adicionados erros aleatórios normalizados sobre as mesmas (respostas na Figura 9) e, certamente, os coeficientes obtidos aqui são ligeiramente diferentes daqueles publicados no trabalho original.
O leitor pode confirmar os valores usados para ± a através da Equação 21.
A Tabela 11 apresenta os resultados obtidos para a propriedade ruptura no alongamento. Observa-se que todos os coeficientes foram significativamente importantes com 95% de confiança, bem como o modelo de regressão avaliado pela ANOVA. Não houve falta de ajuste do modelo, o que é confirmado pela distribuição aleatória dos resíduos com baixas magnitudes em relação aos valores estimados.
A Figura 10 mostra a superfície de resposta do modelo obtida para a propriedade ruptura no alongamento. Através da superfície é possível concluir que com o aumento do conteúdo de óleo no composto de borracha ocorre um aumento na ruptura no alongamento; no entanto, tal propriedade diminui e alcança um mínimo no ponto central, seguido por um aumento com acréscimo do negro-de-fumo. Uma explicação para o valor mínimo da ruptura no alongamento na região do ponto central pode ser atribuída à ação do acoplamento do óleo vegetal e à formação de uma extensão máxima da ligação cruzada através da formação de ligações químicas e físico-químicas entre a interface negro-de-fumo borracha. Certamente, o aumento no alongamento ao redor do ponto central é causado pela plastificação das moléculas de borracha pelo óleo vegetal.
Os resultados para as outras propriedades estudadas e a conclusão geral do estudo podem ser obtidos da mesma maneira a partir do trabalho completo dos autores, disponível na referência citada.
CONCLUSÕES
Em todos os computadores pessoais e programas testados, os cálculos foram realizados com rapidez e não ocorreram falhas, exceto para a construção do gráfico da superfície de resposta. Isto ocorreu visto que a planilha do pacote Openoffice 1.1.1 não disponibiliza em sua biblioteca gráfica malhas contínuas, no entanto a superfície é construída, porém em barras descontínuas.
A montagem dos cálculos em uma planilha eletrônica é uma tarefa bastante simples e está ao alcance do leitor interessado. A versatilidade das planilhas permite implementar cálculos tanto de planejamentos experimentais usuais como de planejamentos que talvez nem estejam disponíveis em pacotes computacionais comerciais.
Assim, o uso das planilhas eletrônicas apresenta as seguintes vantagens principais: há versões gratuitas de planilhas eletrônicas tanto para sistemas operacionais Windows como Linux; o ambiente das planilhas eletrônicas é amigável e seu uso, bastante fácil; cálculos de planejamentos experimentais são facilmente implementados e controlados em seu ambiente oferecendo, ainda, facilidade de visualização das equações e de adaptação para planejamentos específicos, como é o caso do planejamento Doehlert ou planejamentos de misturas; os programas de edição de planilhas eletrônicas fornecem internamente bibliotecas de algoritmos, inclusive estatísticos, tornando possível realizar a avaliação em tempo real dos coeficientes, efeitos e modelos; gráficos, tabelas e dados podem ser facilmente construídos e transferidos para arquivos de textos e etc; o emprego deste tipo de ferramenta no ensino de quimiometria pode contribuir significativamente, uma vez que o estudante pode compreender a realização dos cálculos e a obtenção dos resultados, deixando-o mais entusiasmado e convencido sobre o potencial destas ferramentas35.
Enfim, as planilhas eletrônicas vêm enriquecer ainda mais as ferramentas de cálculos de planejamentos experimentais disponíveis para os profissionais interessados. Os potenciais deste tipo de ferramenta são imensos e é tarefa do usuário descobri-los.
AGRADECIMENTOS
Ao apoio financeiro do Conselho Nacional de Desenvolvimento Científico e Tecnológico CNPq e aos colegas A. Krell e G. A. da Silva pela leitura do texto e valiosas sugestões, ao colega T. P. Trindade pela colaboração na elaboração das planilhas e ao colega E. Correa pela colaboração na elaboração do web site.
4. http://www.statsoft.com, acessada em Novembro 2005.
5. http://www.camo.com, acessada em Novembro 2005.
6. http://www.statgraphics.com, acessada em Novembro 2005.
7. http://www.statease.com, acessada em Novembro 2005.
8. http://www. umetric.com, acessada em Novembro 2005.
9. http://www. minilab.com, acessada em Novembro 2005.
10. http://www. chemkeys.com/bra/index.htm, acessada em Novembro 2005.
11. http://openoffice.org.br, acessada em Novembro 2005.
12. http://www.microsoft.com, acessada em Novembro 2005.
13. http://lqta.iqm.unicamp.br, acessada em Novembro 2005
28. http://fedora.redhat.com, acessada em Outubro de 2004.
Recebido em 10/12/04; aceito em 20/5/05; publicado na web em 8/12/05
- 1. Box, G. E. P.; Hunter, W. G.; Hunter, J. S.; Statistic for Experimenters: An Introduction to Design, Data Analysis and Model Building, Wiley: New York, 1978.
- 2. Barros Neto, B.; Scarminio, I. S.; Bruns, R. E.; Como fazer experimentos: pesquisa e desenvolvimento na ciência e na indústria, 2Ş ed., Ed. Unicamp: Campinas, 2002.
- 3. Lundstedt, T.; Seifert, E.; Abramo, L.; Theilin, B.; Nyström, A.; Pettersen, J.; Bergman, R.; Chemom. Intell. Lab. Syst. 1998, 42, 3.
- 14. Plackett, R. L.; Burman, J. P.; Biometrika 1946, 33, 305.
- 15. Morgan, E.; Burton, K. W.; Church, P. A.; Chemom. Intell. Lab. Syst. 1989, 5, 283.
- 16. Langsrud, Ø.; Ellekjaer, M. R.; Naes, T.; J. Chemom. 1994, 8, 205.
- 17. Myers, R. H.; Montgomery, D. C.; Response surface methodology, Wiley: New York, 2002.
- 18. Box, G. E. P.; Draper, N. R.; Empirical Model-Building and Response Surfaces, Wiley: New York, 1987.
- 19. Sundberg, R.; Chemom. Intell. Lab. Syst 1994, 24, 1.
- 20. Schervish, M. J.; Am. Statist. 1996, 50, 203.
- 21. Christensen, R.; Analysis of variance, design and regression applied statistical methods, CRC: New York, 2000.
- 22. Spiegel, R. M.; Estatística, LTC: Rio de Janeiro, 1967.
- 23. Box, G. E. P.; Wilson, K. B.; J. Roy. Statist. Soc., Ser. B 1951, 13, 1.
- 24. Doehlert, D. H.; Appl. Statist. 1970, 19, 231.
- 25. Ferreira, S. L. C.; Santos, W. N. L. dos; Quintella, C. M.; Neto, B. B.; Bosque-Sendra, J. M.; Talanta 2004, 63, 1061.
- 26. Massart, D. L.; Vandeginste, B. G. M.; Buydens, L. M. C.; Jong, S.; Lewi, P. J.; Smeyers-Verbeke, J.; Handbook of Chemometrics and Qualimetrics, Part A, Elsevier: Amsterdam, 1998.
- 27. García-Campaña, A. M.; Rodríguez, L. C.; González, A. L.; Barrero, F. A.; Ceba, M. R.; Anal. Chim. Acta 1997, 348, 237.
- 29. Matlab, The Language of Technical Computing; Natick, USA, 2003.
- 30. Statistica, Data Analysis Software System; Tulsa, USA, 2001.
- 31. Arambarri, I.; Garcia R.; Millán, E.; Analyst 2000, 125, 2084.
- 32. Milliken, G.A.; Johnson, D. E.; Analysis of Messy Data, van Nostrand Reinhold, Co.: New York, 1984, vol. 1.
- 33. Dron, J.; Garcia, R.; Millán, E.; J. Chromatogr., A 2002, 963, 259.
- 34. Kukreja, T. R.; Kumar, D.; Prasad, K.; Chauhan, R. C.; Choe, S.; Kundu, P. P.; Eur. Polym. J. 2002, 38, 1417.
- 35. Teófilo, R. F.; Bruns, R. E; Ferreira, M. M. C.; Resumos da 27Ş Reunião Anual da Sociedade Brasileira de Química, Salvador, Brasil, 2004.
Datas de Publicação
-
Publicação nesta coleção
03 Abr 2006 -
Data do Fascículo
Abr 2006
Histórico
-
Recebido
10 Dez 2004 -
Aceito
20 Maio 2005