Resumo
A simple, robust, versatile, high analytical frequency method was proposed to check if a sample of wine is within the range of standards set by the manufacturer, using the UV-VIS spectroscopy, multivariate analysis and a flow-batch analyzer. Two hundred and fifty-two samples of wines were analyzed. The results from the application of Hierachical Cluster Analysis (HCA) to the matrix of the data involving all samples show the formation of fifteen types of wine. A Soft Independent Modelling of Class Analogy (SIMCA) model was constructed and used to classify the samples of the overall forecast. As a result, it is observed that the prediction was performed with a success rate of 99.2% for a confidence level of 95%. This shows that the proposed methodology can be used as an effective tool for classifying of samples of wines.
quality control of wines; flow-batch analyzer; chemometrics
quality control of wines; flow-batch analyzer; chemometrics
ARTIGO
Análise screening de vinhos empregando um analisador fluxo-batelada, espectroscopia UV-VIS e quimiometria
Screening analysis of wines using flow-batch analyzer, UV-VIS spectroscopy and chemometrics
Jaqueline Azevedo Nascimento* * e-mail: jaquelinejp@yahoo.com.br ; Amália Geíza Gama Dionísio; Elaine Cristina Lima do Nascimento; Sueny Kêlia Barbosa Freitas; Mário César Ugulino de Araújo
Departamento de Química, Universidade Federal da Paraíba, CP 5093, 58051-970 João Pessoa - PB, Brasil
ABSTRACT
A simple, robust, versatile, high analytical frequency method was proposed to check if a sample of wine is within the range of standards set by the manufacturer, using the UV-VIS spectroscopy, multivariate analysis and a flow-batch analyzer. Two hundred and fifty-two samples of wines were analyzed. The results from the application of Hierachical Cluster Analysis (HCA) to the matrix of the data involving all samples show the formation of fifteen types of wine. A Soft Independent Modelling of Class Analogy (SIMCA) model was constructed and used to classify the samples of the overall forecast. As a result, it is observed that the prediction was performed with a success rate of 99.2% for a confidence level of 95%. This shows that the proposed methodology can be used as an effective tool for classifying of samples of wines.
Keywords: quality control of wines; flow-batch analyzer; chemometrics.
INTRODUÇÃO
O vinho é uma bebida simples, resultante da conversão gradual dos açúcares presentes no mosto de uvas frescas em álcool, CO2 e energia por intermédio do levedo.1 Desta forma, vinhos de má qualidade são facilmente elaborados, bem como bastante propícios a falsificações e/ou adulterações. As falsificações e/ou adulterações de alimentos constituem crime contra a saúde pública, na medida em que são comercializados produtos ilegais, sem controle e sem fiscalização, que podem prejudicar a saúde da população, além de lesar o consumidor que paga caro por um produto de qualidade e de sonegar impostos aos órgãos governamentais. Muitos são os relatos de casos de falsificação e/ou adulterações de vinhos e, preocupadas com este problema, as indústrias produtoras tentam, a todo custo, tomar medidas que amenizem esta situação.
Existe uma vasta variedade de vinhos e a forma mais comum para classificá-los corresponde ao seu aspecto visual e pigmentação característica. Porém, existem outras classificações que têm a ver com o processo de vinificação ou, ainda, quanto ao teor de açúcar. A classificação e a caracterização de vinhos vêm sendo realizadas através da utilização de alguns parâmetros como teor alcoólico, pH, acidez fixa e volátil, teor de cinzas etc.2 Para isso têm sido utilizados métodos espectroscópicos de massa,3 de emissão óptica,4 de espectroscopia NIR5 e de absorção atômica em chama.6 No entanto, a técnica analítica padrão de referência utilizada para a verificação da autenticidade de vinhos no Brasil é a cromatografia.7 Tal técnica apresenta um custo elevado de seus instrumentos e de manutenção constante, bem como requer a preparação de reagentes e soluções padrão com produção de resíduos prejudiciais à saúde e/ou ao meio ambiente, além de apresentar uma baixa frequência analítica. Uma boa alternativa para superar estes inconvenientes é o desenvolvimento de métodos analíticos que combinam o uso da espectrometria de absorção molecular UV-VIS, analisadores automáticos em fluxo e quimiometria.
A espectrofotometria molecular na região ultravioleta-visível (UV-VIS) é uma técnica analítica que vem sendo empregada há mais de 50 anos para identificação e determinação quantitativa de muitas espécies moleculares inorgânicas, orgânicas e bioquímicas em diferentes tipos de materiais.8 A determinação qualitativa e quantitativa de cada constituinte de uma amostra é uma tarefa muito laboriosa ao se usar a espectrofotometria UV-VIS. Devido às bandas de absorção se apresentarem muito alargadas, sobrepostas e carentes de detalhes, torna-se muito complexa e de difícil interpretação uma análise qualitativa da amostra. Além disso, para uma completa caracterização de uma amostra muitas vezes recorre-se a reagentes específicos para a espécie absorvente, cuja determinação quantitativa é desejada.9
Algumas vezes pode não ser necessário o uso de vários procedimentos analíticos para a análise preliminar de uma amostra. Neste contexto, o uso da análise screening como processo preliminar de análise, mostrando a necessidade ou não de uma análise pelos métodos de referência, para classificação e verificação da falsificação em vinhos torna-se um objetivo bastante relevante, pois diminui os custos da indústria com análises desnecessárias.10-14 Em termos de fornecimento de resultados rápidos, a análise screening torna-se ainda mais interessante se realizada usando analisadores automáticos.
Os analisadores automáticos em fluxo são, em geral, sistemas mais simples, versáteis e flexíveis do que os analisadores em batelada e robotizado. Dentre os diversos analisadores automáticos em fluxo, pode-se destacar o analisador automático fluxo-batelada (Flow-Batch Analyser - FBA), desenvolvido em 1999, que alia as características vantajosas dos diferentes tipos de analisadores em fluxo, em batelada e dos em multicomutação.15 Tal analisador vem sendo usado em titulações,16 em pré-tratamento da amostra para ajustá-la ao pH17 ou à salinidade18 adequada do meio de análise, em adições de padrão,19 na preparação de soluções multicomponentes para calibração multivariada,20,21 em análise screening de cátions e de dureza de água.22
Pelo exposto, uma boa alternativa para a realização rápida de uma análise screening de vinhos é a combinação da espectrometria UV-VIS associada ao uso de analisadores automáticos em fluxo; entretanto, esta metodologia gera sinais complexos do ponto de vista matemático sendo então necessária a utilização da quimiometria.23-34 O uso da quimiometria tem como objetivo tratar dados de caráter multivariado retirando o máximo de informações presentes em suas matrizes complexas, facilitando assim a interpretação dos mesmos. Diferentes ferramentas quimiométricas são utilizadas, tais como, análise de agrupamento hierárquica (HCA - Hierachical Cluster Analysis), análise em componentes principais (PCA - Principal Component Analysis), modelagem independente flexível por analogia de classe (SIMCA - Soft Independent Modelling of Class Analogy), dentre outras.
A HCA usa distâncias interpontos entre todas as amostras, representando-as em forma de um gráfico bidimensional, denominado dendrograma. Na geração destes gráficos, cada amostra é tratada inicialmente como uma classe que a uma determinada distância se une às amostras mais próximas para formar os agrupamentos ou classes (clusters), e assim sucessivamente, até formar um único agrupamento ou classe conjunta de todas as amostras.23 A proximidade de amostras ou variáveis dentro de um agrupamento ou classe pode ser associada à similaridade de propriedades químicas e/ou físicas.33
A PCA23-25,30,34 é uma manipulação matemática de dados de uma matriz cuja finalidade é transformar e extrair informações relevantes de dados complexos, tornando-os de mais fácil interpretação. Isso é possível pela combinação linear das variáveis originais, constituindo um novo conjunto de variáveis que contém apenas as informações importantes, criando-se novos eixos no espaço multidimensional, chamados de componentes principais (PC). Assim, cada amostra é representada por um ponto no espaço multidimensional, do qual é possível extrair informações sobre a mesma e/ou sobre agrupamentos ou classes que apresentem características semelhantes. Tal ferramenta fornece uma visão estatisticamente privilegiada e simples do conjunto de dados, além de permitir a inferência de correlações existentes entre amostras e/ou variáveis independentes. As PCA utilizam diferentes métodos para validar os seus modelos. Para validação de modelos PCA construídos com muitas amostras é mais indicado utilizar o método série de teste. Para validar modelos PCA construídos com poucas amostras é mais indicado utilizar o método validação cruzada (cross-validation).23 O método de validação cruzada divide o conjunto de calibração em 2 sub-conjuntos: calibração e validação. Este método se processa da seguinte forma: constrói-se o modelo com o sub-conjunto de calibração e usa-se este modelo para prever o sub-conjunto de validação; repete-se este processo usando diferentes sub-conjuntos de calibração e validação até que todas as amostras do conjunto de calibração tenham sido incluídas no sub-conjunto de validação; os resultados da predição são usados para validar a performance do modelo com um todo.
O SIMCA23,35-37 é um método de reconhecimento de padrões que modela a localização das classes no espaço multidimensional através do uso de componentes principais, de forma que para cada agrupamento ou classe de amostras é criado um modelo PCA que delimita uma região espacial (as fronteiras), construindo-se caixas multidimensionais. Assim, pode-se classificar uma amostra desconhecida como pertencente a uma das classes previamente modeladas, se ela possuir características que permitam que seja inserida na caixa multidimensional de um dos agrupamentos. Para prever com um modelo SIMCA a classe a que pertence uma amostra, primeiramente é necessário determinar que região do espaço ela ocupa, projetando o seu vetor de medida em cada um dos modelos SIMCA do conjunto de validação. Na predição SIMCA, uma amostra pode ser classificada como pertencente a uma, a várias ou a nenhuma classe.
As amostras anômalas (outliers), ou seja, as que não se encaixam em nenhuma classe, podem ocorrer devido a um erro nas medidas, a uma má rotulação, a um fenômeno químico e/ou físico anômalo ou desconhecido ou, ainda, essa amostra pode pertencer a uma outra classe que não foi inclusa no conjunto de calibração/validação usado na construção dos modelos de cada classe.
Para realizar uma classificação SIMCA, a direção da PC e os limites estabelecidos para a mesma (as fronteiras) definem o modelo das classes. Para saber se uma amostra desconhecida X pertence a uma determinada classe calculam-se duas distâncias: a distância entre a amostra e o eixo da componente principal "c" e a distância entre a projeção da amostra na direção da componente principal e a fronteira da classe "b". A amostra é classificada como pertencente à classe se apresentar variância dentro de um valor crítico determinado pelo modelo. Este valor crítico é função do valor de "a", que corresponde à proximidade de X em relação à caixa tridimensional, e pode ser obtido pela Equação a2 = b2 + c2. Por esta equação calcula-se o valor de "a", que é dividido pela variância da classe para formar um valor calculado, Fcal. Utiliza-se, então, o teste F onde um valor crítico, Fcrit, é escolhido empiricamente ou a partir de uma tabela do teste F. Se o Fcal for menor do que o valor crítico adotado, a amostra desconhecida pode ser classificada como pertencente à classe considerada.23,35-37 Em geral, esta manipulação matemática já se encontra inserida nos pacotes quimiométricos e os resultados das classificações são apresentados em tabelas.37 Nessas tabelas as amostras classificadas como pertencentes ao respectivo modelo SIMCA são indicadas pela presença de asteriscos (*); a ausência do asterisco indica que as amostras não estão inseridas naquele respectivo modelo (classe).
Portanto, é proposta deste trabalho é uma metodologia de análise screening para identificar se uma determinada amostra de vinho está ou não dentro dos padrões estabelecidos pelo fabricante, usando-se a espectrofotometria de absorção molecular UV-VIS, um analisador automático em fluxo-batelada e métodos quimiométricos de análise multivariada.
PARTE EXPERIMENTAL
Amostras e diluentes
Foram analisadas 252 amostras de vinhos diferentes quanto à marca, tipo (branco ou tinto), classe (suave, demiseco ou seco) e valor associado (qualidade) de lotes distintos, das quais 128 amostras foram adquiridas em supermercados da grande João Pessoa e 124 amostras fornecidas por seus respectivos produtores.
Um grupo de 8 amostras de uma das marcas foi acondicionado de maneira inadequada por um longo período de tempo e analisado separadamente para ser incluído no conjunto de predição. Devido à forte absorção das amostras puras na região espectral estudada, antes de registrar seus espectros, estas foram diluídas com água destilada usando o analisador FBA, nas seguintes proporções: vinhos tintos = 1:101, vinhos brancos = 1:26.
Materiais e equipamentos
Na montagem do analisador FBA foram empregadas 3 válvulas solenoides three-way, da Cole-Parmer, para intercalação dos fluidos no percurso analítico; 1 acionador de válvulas lab-made para controlar a abertura das válvulas solenoides; 1 bomba peristáltica Ismatec MS-Reglo, modelo 73315-15, da Cole-Parmer, de modo a propulsionar os fluidos ao detector; 1 câmara de mistura constituída por um cilindro de acrílico lab-made contendo em seu interior, uma barra magnética para promover uma melhor diluição e homogeneização entre as amostras e a água destilada, cuja rotação é proporcionada por um agitador magnético Ika, modelo 8068; 1 cela de fluxo de quartzo comercial da Hellma com caminho óptico de 1,0 cm; 1 espectrofotômetro de absorção molecular UV-VIS com arranjo de fotodiodos da marca Hewllet Packard, modelo 8453; 1 microcomputador Pentium Intel 233 MHz para controle, aquisição de dados do analisador FBA utilizando um software desenvolvido e escrito em linguagem visual LabView 5.1.
Os espectros de cada amostra foram registrados na região de 190 a 1100 nm e foram tratados com técnicas quimiométricas de reconhecimento de padrões e classificação (HCA, PCA e SIMCA) usando os softwares Statistic 7.0 e The Unscrambler® 9.7 (Camo S.A.).37
Procedimento analítico
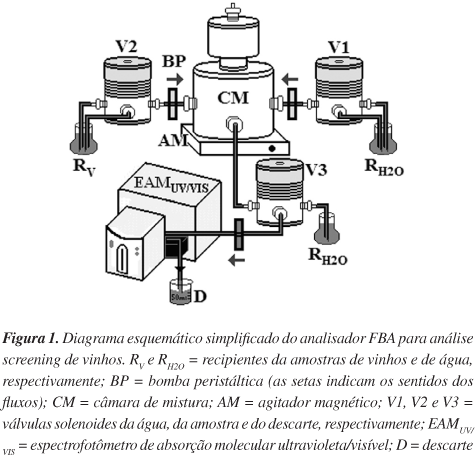
Para facilitar o entendimento do procedimento do analisador FBA para análise screening de vinhos, é mostrado um diagrama simplificado na Figura 1.
O procedimento completo é realizado em quatro etapas: 1ª) etapa de enchimento dos canais - inicialmente a amostra de vinho e a água foram bombeadas e ficaram reciclando em direção aos seus frascos (fluxo intermitente), isso ocorre quando as válvulas não estão acionadas. Depois, as válvulas V1 e V2 (Figura 1) foram simultaneamente acionadas durante 5 s, bombeando água e vinho de forma a encher os canais entre as válvulas e a câmara de mistura. Esta etapa deve sempre ser repetida quando a amostra e/ou a água forem trocadas. Foram retiradas alíquotas das amostras de suas embalagens originais e mantidas à temperatura ambiente; 2ª) de limpeza da câmara - ao final da etapa anterior, é necessária uma limpeza da câmara de mistura, devido a resquícios de água e amostra provenientes desta etapa. Desta forma, fez-se a drenagem de todo líquido existente na câmara de mistura, que se iniciou com o acionamento da válvula V3 durante 5 s. Após a drenagem, acionou-se a válvula V1 durante 10 s, o que proporcionou um enchimento da câmara com água e, posteriormente, o seu esvaziamento através do acionamento da válvula V3 por 12 s, repetindo-se esta última etapa por duas vezes.
A terceira etapa é a de diluição e registro dos espectros das amostras - uma vez enchidos os canais e limpa a câmara, prossegue-se com a diluição das amostras. Esta etapa é fundamental, pois ao analisar as amostras puras de vinho, constatou-se que havia uma forte absorção na região espectral estudada. Assim, antes de registrar seus espectros, as amostras foram diluídas com água destilada (Tabela 1). Sabendo-se que o tempo de abertura das válvulas é diretamente proporcional ao volume adicionado na câmara de mistura, e que este volume varia com a vazão utilizada em cada canal, em todo o procedimento de diluição descrito abaixo, usa-se sempre o termo tempo em vez de volume. Ao acessar a janela do programa desenvolvido para controle, escolhem-se as válvulas e os tempos de abertura de cada uma delas. Os tempos de abertura das válvulas para a diluição das amostras e para medidas dos espectros no detector são apresentados na Tabela 1.
O início do processo de análise se deu pelo registro do espectro do branco, para isso foi aspirada água para o detector via a válvula V3, durante 5 s. Em seguida, foi feita a diluição das amostras na câmara, dependendo do tipo do vinho (Tabela 1), acionando-se as válvulas V1 e V2 simultaneamente, durante t1 e, em seguida, apenas a válvula V1 durante t2. Após a homogeneização da diluição, sempre durante 10 s, as amostras foram aspiradas para o detector abrindo-se a válvula V3 durante o tempo t3 e seus espectros foram registrados e arquivados no microcomputador. Ao término dessa etapa foram feitas a drenagem e limpeza do analisador.
A quarta etapa é a de drenagem-limpeza do analisador: terminada a etapa de diluição e registro dos espectros das amostras, fez-se a limpeza do analisador com a finalidade de evitar contaminação cruzada. Nesta etapa, água destilada foi bombeada no canal da amostra, e as válvulas V1, V2 e V3 foram acionadas simultaneamente por 10 s, permanecendo apenas a válvula V3 ativada por mais 30 s para garantir o esvaziamento da câmara de mistura. Após a drenagem, acionou-se a válvula V1 durante 10 s, o que proporcionou um enchimento da câmara com água e, posteriormente, o seu esvaziamento através do acionamento da válvula V3 por 12 s, repetindo-se esta última etapa por duas vezes.
RESULTADOS E DISCUSSÃO
Seleção da região espectral de trabalho e pré-processamento dos dados
Ao se observar os perfis espectrais das 252 amostras de vinhos constatou-se que na região entre 190 e 220 nm as medidas absorbância se encontram saturadas, enquanto que na região entre 350 e 1100 nm, elas não apresentam informações espectrais relevantes, e a inclusão destas regiões poderia prejudicar os modelos quimiométricos de classificação. Tais fatos evidenciam que a região espectral de trabalho entre 220 e 350 nm traz maiores informações referentes aos vinhos. A Figura 2 apresenta os perfis espectrais de 21 amostras de vinhos (1 amostra para cada vinho estudado) antes do pré-processamento dos dados.
Na Figura 2 são observadas variações sistemáticas e perfis bastante ruidosos, havendo assim a necessidade de pré-processar os dados. Os espectros originais de cada amostra contêm 131 pontos, correspondentes aos 131 comprimentos de onda da região espectral utilizada (220 a 350 nm). Estes espectros originais foram pré-processados usando-se dois métodos. Inicialmente foi aplicado o método de suavização Savitzky-Golay. Os espectros suavizados resultantes foram, depois, pré-processados usando-se o método de normalização pela média.
No método de suavização Savitzky-Golay usou-se um polinômio móvel de segunda ordem com janela de 11 pontos. Estes pré-processamentos geram espectros bastante similares aos espectros originais das amostras, com a diferença que a variação ruidosa aleatória encontra-se suavizada e que 10 pontos (10 comprimentos de ondas), 5 em cada extremo dos espectros, são excluídos devido a este pré-processamento. Com a perda desses 10 pontos excluídos, os espectros gerados com esta suavização passam a ter uma faixa espectral mais estreita (225 a 345 nm) e, consequentemente, um número menor de pontos (121 comprimentos de onda).
Os espectros suavizados, contendo 121 variáveis, foram pré-processados usando-se o método de normalização pela média, a qual é calculada pela Equação matricial (1):
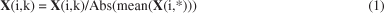
Esta normalização dá como resultado os perfis espectrais mostrados na Figura 3.
Observa-se na Figura 3 uma significativa mudança nos perfis das curvas resultante do pré-processamento pelo método de normalização pela média, em relação aos espectros originais. Esta mudança ocorre porque neste pré-processamento os valores de absorbância de cada espectro suavizado são transformados em valores normalizados pela média, ou seja, não são mais valores em absorbância. Quando o valor individual de cada variável de um espectro for maior que o valor da média absoluta de todas as variáveis deste espectro, ele dará um valor superior a 1 (linha contínua na Figura 3); quando for igual à média dará valor igual a 1 e quando for menor dará valor menor que 1. Na Figura 3 pode ser observado que, após os pré-processamentos de suavização Savitzky-Golay e de normalização pela média, as curvas resultantes se encontram bem comportadas quanto à presença de variações sistemáticas e de ruídos. A matriz de dados resultante destes dois pré-processamentos foi utilizada para a construção dos modelos quimiométricos discutidos a seguir.
Construção dos modelos quimiométricos
Na Tabela 2 estão apresentadas as legendas e os números de amostras dos conjuntos de calibração, validação e de predição dos vinhos.
Utilizaram-se as amostras de vinhos do conjunto de calibração/validação (cross-validation) na construção de modelos quimiométricos de análise exploratória (HCA e PCA) e as de calibração, validação e de predição para a classificação (SIMCA). Estes modelos foram utilizados para a distinção e classificação de diferentes vinhos.
No dendrograma resultante da HCA (Figura 4), observa-se a formação de 15 agrupamentos de vinhos bem definidos numa distância aproximadamente de 0,4 e que cada agrupamento corresponde a uma classe de vinho, com exceção do agrupamento 4-5, resultante da sobreposição de duas classes (BSeP e BSuP).
Numa distância de aproximadamente 2,8 os vinhos BSuW (1), BSuG (2), BSuC (3), BSuP (4) e BSeP (5) se ligam formando um único agrupamento de vinhos brancos suaves (exceto o BSeP (5) que é um vinho branco seco). Uma possível explicação para a classe BSeP (5) estar inclusa no agrupamento da classe de vinhos brancos suaves será descrita após a análise dos perfis espectrais. Numa distância de aproximadamente 1,6 os vinhos BSeG (14), BSeW (15) e BSeC (16) se ligam formando um único agrupamento de vinhos brancos secos. Os vinhos TSuP (10) e TSeP (11) se ligam em uma distância de aproximadamente de 0,3 formando um único agrupamento dos vinhos tintos suaves e secos do tipo P. Observa-se que nesta classe (tipo P tintos) os vinhos se comportam de maneira análoga aos do tipo P brancos. Os vinhos TSuW (8), TSuC (9), TSuP (10) e TSeP (11) se ligam formando um agrupamento dos vinhos tintos suaves (exceto o TSeP (11) que é um vinho da classe tinto seco). Se ligaram na distância 5,4, aproximadamente, os vinhos secos (6) e demisecos (7) da marca G. Observa-se, com base nas distâncias, que esta classe tem um comportamento diferente das demais amostras de vinhos tintos. Estes vinhos apresentam um teor alcoólico diferenciado dos demais vinhos, bem como o valor associado. Consagradamente estes vinhos apresentam uma melhor qualidade, apesar de serem do mesmo tipo (tinto) dos demais vinhos.
Analisando os perfis dos espectros para os vinhos BSeP e BSuP, observa-se que os mesmos apresentam perfis bastantes semelhantes, confirmando a sobreposição entre eles (Figura 5) como já vista pelo gráfico bidimensional (dendrograma) obtida pela HCA.
Uma possível explicação para esta sobreposição é que eles pertencem ao mesmo fabricante P, e que a única diferença entre os vinhos brancos suaves (BSuP) e os vinhos brancos secos (BSeP), segundo o fabricante, é simplesmente a adição de 50 g de açúcar por litro nos vinhos suaves. Portanto, o teor de açúcar usado na elaboração destes vinhos não os distingue e, desta forma, considerar-se-á como um único agrupamento de vinho branco (suaves e secos) da marca P, denominado agora (legendados) como BP.
Para a classificação das diferentes classes de vinhos analisados, foram construídos modelos PCA's individuais para cada classe de vinho utilizando-se a técnica de validação cruzada (cross-validation). Através dos gráficos das variâncias explicadas versus os números de componentes principais, foram escolhidos os números ótimos de componentes principais a serem usados nos modelos de calibração. A inclusão de outras componentes principais pode incluir ruídos e ampliar as fronteiras da caixa multidimensional prejudicando, consequentemente, o modelo elaborado e a eficiência dos resultados.
Foram construídos modelos SIMCA para cada tipo de vinho, com o objetivo de usá-los na classificação de todos os vinhos analisados (Tabela 2). Os modelos PCA's anteriormente elaborados foram utilizados para construção destes modelos. Cada modelo SIMCA foi construído separadamente, usando as amostras do conjunto de calibração de cada tipo de vinho. Para avaliar a capacidade preditiva destes modelos estes foram empregados na classificação das amostras do conjunto de predição (que não fizeram parte do procedimento de calibração e de validação). Para confirmar a inserção das amostras do conjunto de calibração e de validação em seu próprio modelo SIMCA, estas também foram empregadas nas classificações. Deste modo, após a construção dos modelos SIMCA para cada classe de vinho, foi feita a classificação utilizando todas as amostras analisadas (Tabela 2).
A tabela de resultados das classificações SIMCA mostra que todas as amostras do conjunto de predição foram classificadas corretamente (100% de acerto em nível de confiança de 95%) para 13 modelos SIMCA (BSeC, BSeG, BSuC, BSuW, BSuG, TdsG, TSeC, TSeW, TSeP, TSeG, TSuC, TSuW, TsuP), o que demonstra a boa capacidade preditiva destes modelos. Na validação, observou-se que todas as amostras do conjunto de calibração e de validação foram classificadas corretamente em seu próprio modelo SIMCA. Isso pode ser observado nos gráficos dos scores com as amostras da classe do vinho modelado e algumas amostras de outras classes. Observou-se nestes gráficos que as amostras pertencentes às classes modeladas se encontravam afastadas das demais amostras (outras classes) no espaço tridimensional e que as amostras usadas para a validação dos modelos se encontravam inseridas entre as amostras de calibração do modelo. Desta forma, pode-se afirmar que esta metodologia é capaz de classificar as amostras de outras marcas (amostras estas que podem ser utilizadas para falsificar um vinho de melhor qualidade e custo), bem como classificar vinhos fora dos padrões de qualidades, por exemplo, fora da data de validade, ou que possam ter sido adulterados por adições inadequadas de outros componentes, por exemplo, água. Com a análise espectrofotométrica é possível determinar as características intrínsecas de cada amostra de vinho analisada. Com base nessas informações, modelos quimiométricos são construídos e utilizados para fins de classificações. Amostras que se assemelham às características modeladas são classificadas como pertencentes ao respectivo modelo; as amostras com características diferentes são classificadas como não pertencentes ao modelo. Estas amostras podem ser classificadas quanto às características peculiares ou quanto à falsificação e/ou adulteração.
Usando os modelos SIMCA para as classes dos vinhos BSeW e BP com o nível de confiança de 95%, obteve-se 99,6% de acerto, pois foram classificadas como pertencentes à classe dos vinhos BSeW apenas as amostras de vinhos pertencentes a esta classe, sendo que uma amostra pertencente a esta classe (BSeW5) não foi classificada como tal. De forma análoga, foram classificadas como pertencentes à classe dos vinhos BP apenas as amostras de vinhos pertencentes a esta classe, sendo que uma amostra pertencente a esta classe (BSuP1) não foi classificada como tal. Desta forma, analisando os perfis dos espectros para a classe BSeW, observa-se que a amostra BSeW5 tem um perfil bastante diferente quando comparada aos perfis das demais amostras, o que evidencia o fato dela não estar inserida na sua classe. Certamente esta amostra apresenta uma composição química ou propriedades físicas diferentes das demais amostras, sendo que para esta investigação se necessita recorrer a outros métodos de análises químicas como, por exemplo, a cromatografia.
No gráfico dos scores com as amostras da classe dos vinhos BSeW e algumas amostras de outras classes (Figura 6), observa-se que as amostras classificadas como não pertencentes à classe de vinhos BSeW encontram-se bem separadas das amostras classificadas como pertencentes à esta classe no espaço tridimensional. Observa-se ainda que as amostras utilizadas para validar este modelo se encontram inseridas no espaço tridimensional desta classe, enquanto que a amostra BSeW5, que não foi classificada como pertencente à esta classe, se encontra bem afastada do espaço tridimensional reservado para a sua classe, caracterizando uma amostra anormal (outlier).
Da mesma forma, no gráfico dos scores com as amostras da classe dos vinhos BP e algumas amostras de outras classes (Figura 7), observa-se que as amostras classificadas como não pertencentes à classe de vinhos BP se encontram afastadas das amostras classificadas como pertencente à esta classe no espaço tridimensional. Observa-se ainda que as amostras utilizadas para validar este modelo se encontram inseridas no espaço tridimensional desta classe, enquanto que a amostra BSuP1 (que não foi classificada como pertencente à esta classe) se encontra bem afastada das fronteiras da caixa multidimensional reservada para a sua classe, caracterizando a necessidade de se reavaliar as fronteiras desta caixa (dimensionalidade inerente) ou a presença de uma amostra anômala.
CONCLUSÃO
Neste trabalho foi desenvolvida uma metodologia de análise screening para fins de identificação e classificação usando-se a espectrometria de absorção molecular UV-VIS, um analisador automático em fluxo-batelada e métodos quimiométricos de análise multivariada. Para determinar se as amostras de vinhos estavam dentro ou não das conformidades, modelos quimiométricos de análise exploratória e de classificação foram elaborados usando um conjunto de treinamento formado por 252 amostras de vinhos. Comprovou-se que a metodologia desenvolvida foi capaz de classificar corretamente 99,2% das amostras de vinhos em nível de confiança de 95%. Conclui-se que esta metodologia mostrou-se bastante eficiente como processo preliminar de análise (análise screening), mostrando a necessidade ou não de uma análise pelos métodos clássicos de referência, proporcionando as seguintes vantagens: menor custo operacional, maior simplicidade e rapidez das análises, baixo consumo de amostras, dispensando tratamento prévio das amostras e uso de reagentes caros, tóxicos e danosos ao meio ambiente.
AGRADECIMENTOS
À CAPES (Coordenação de Aperfeiçoamento de Pessoal de Nível Superior) e ao CNPq (Conselho Nacional de Desenvolvimento Científico e Tecnológico) pelas bolsas concedidas.
Recebido em 12/3/09; aceito em 13/8/09; publicado na web em 8/1/10
-
1http://quark.qmc.ufsc.br/qmcweb/artigos/vinho/capa.html, acessada em Dezembro 2008.
» link - 2. Arvanitoyannis, I. S.; Katsota, M. N.; Psarra, E. P.; Soufleros, E. H.; Kallithraka, S.; Food Sci. Technol. 1999, 10, 321.
- 3. Martí, M. P.; Busto, O.; Guasch, J.; J. Chromatogr., A 2004, 1057, 211.
- 4. Sperková, J.; Suchánek, M.; Food Chem. 2005, 93, 659.
- 5. Liu, L.; Cozzolino, D.; Cynkar, W. U.; Dambergs, R. G.; Janik, L.; O'neill, B. K.; Colby, C. B.; Gishen M.; Food Chem. 2008, 106, 781.
- 6. Frías, S.; Conde, J. E.; Rodríguez-bencomo, J. J.; García-Montelongo, F.; Pérez-Trujillo, J. P.; Talanta 2003, 59, 335.
- 7. Berente, B.; García, D. C.; Reichenbacher, M.; Danzer, K.; J. Chromatogr., A 2000, 871, 95.
- 8. Skoog, D. A.; Holler, F. J.; Nieman, T. A.; Princípios de Análise Instrumental, 5Ş ed., Bookman: Porto Alegre, 2002.
- 9. Rodriguez, A. M. G.; Torres, A. G.; Cano pavon, J. M.; Bosch ojeda, C.; Talanta 1998, 47, 463.
- 10. Kellner, R.; Mermet, J. M.; Otto, M.; Widner, H. M.; Analytical Chemistry, J. Wiley: New York, 1998.
- 11. Valcárcel, M.; Princípios de Química Analítica, Springer-Verlag Ibérica: Madrid, 1999.
- 12. Pulido, A.; Ruisanchez, I.; Boque, R.; Rius, F. X.; Trends Anal. Chem. 2003, 22, 647.
- 13. Trullols, E.; Ruisanchez, I.; Rius, F. X.; Trends Anal. Chem. 2004, 24, 137.
- 14. Valcárcel, M.; Cáardenas, S.; Gallego, M.; Trends Anal. Chem. 1999, 18, 685.
- 15. Honorato, R. S.; Araújo, M. C. U.; Lima, R. A. C.; Zagatto, E. A. G.; Lapa, R. A. S.; Lima, J. L. F. C.; Anal. Chim. Acta 1999, 396, 91.
- 16. Lima, R. A. C.; Santos, S. R. B.; Costa, R. S.; Honorato, R. S.; Nascimento, V. B.; Araújo, M. C. U.; Anal. Chim. Acta 2004, 518, 25.
- 17. Honorato, R. S.; Carneiro, J. M. T.; Zagatto, E. A. G.; Anal. Chim. Acta 2001, 441, 309.
- 18. Carneiro, J. M. T.; Dias, A. C. B.; Zagatto, E. A. G.; Honorato, R. S.; Anal. Chim. Acta 2002, 455, 327.
- 19. Almeida, L. F.; Martins, V. L.; Silva, E. C.; Moreira, P. N. T.; Araujo, M. C. U.; J. Am. Soc. Brew. Chem. 2003a, 14, 249.
- 20. Gaião, E. da N.; Tese de Doutorado, Universidade Federal da Paraíba, Brasil, 2003.
- 21. Visani, V.; Dissertação de Mestrado, Universidade Federal da Paraíba, Brasil, 2002.
- 22. Formiga, F. M.; Medeiros, E. P.; Neto, J. G. V.; Gaiao, E. N.; Silva, E. C.; Araújo, M. C. U.; Controle & Instrumentação 2003, 83, 65.
- 23. Beeb, K. R.; Pell, R. J.; Seasholtz, M. B.; Chemometrics: A Practical Guide, J. Wiley: New York, 1998.
- 24. Massart, D. L.; Vandeginste, B. G. M.; Buydens, S. J.; Lewi, P. J.; Smeyers-Verbeke, J.; Handbook of Chemometrics and Qualimetrics: Parte B, Elsevier: Amsterdam, 1997.
- 25. Brereton, R. G.; Chemometrics: data analysis for the laboratory and chemical plant, Ed. Wiley: University of Bristol, 2003.
- 26. Capella-Peiró, M. E.; Bossi, A.; Esteve-Romero, J.; Anal. Biochem. 2006, 352, 41.
- 27. Urabano, M.; Luque de castro, M. D.; Pérez, P. M.; García-Olmo, J.; Gómez-Nieto, M. A.; Food Chem. 2006, 97, 166.
- 28. Ni,Y.; Qi, Z.; Kokot, S.; Chemom. Intell. Lab. Syst. 2006, 82, 241.
- 29. Hair Jr., J. F.; Anderson, R. E.; Tatham, R. L.; Black, W. C.; Análise Multivariada de Dados, 5Ş ed., Bookman: Porto Alegre, 2005.
- 30. Wold, S.; Chemom. Intell. Lab. Syst. 1987, 2, 37.
- 31. Morgano, M. A.; Queiroz, S. C. N.; Ferreira, M. M. C.; Brazilian J. Food Tech. 1999, 2, 73.
- 32. Branden, K. V.; Hubert, M.; Chemom. Intell. Lab. Syst. 2005, 79, 10.
- 33. Massart, D. L.; Kaufman, L. J.; The interpretation of analytical chemical data by the use of cluster analysis, Wiley: New York, 1983.
- 34. Moita Neto, J. M.; Moita, G. C.; Quim. Nova 1998, 21, 467.
- 35. Downey, G.; Analyst 1994, 119, 2367.
- 36. Blanco, M.; Coelho, J.; Iturriaga, H.; Maspoch, S.; De La Pezuela, C.; Analyst 1998, 123, 135.
- 37. Manual do Usuário, The Unscrambler 9.7, Camo S.A.: Noruega, 1998.
Datas de Publicação
-
Publicação nesta coleção
12 Mar 2010 -
Data do Fascículo
2010
Histórico
-
Aceito
13 Ago 2009 -
Recebido
12 Mar 2009