Resumos
Estudou-se o modelo de análise de covariância com um fator e erro de medida na covariável. Avaliou-se, neste modelo, por meio de simulação, a acurácia e precisão de dois estimadores, propostos na literatura para estimar parâmetros de um modelo de regressão com erro de medida. Sobre diferentes distribuições dos resíduos, coeficientes de determinação e tamanhos amostrais, estudou-se o comportamento de ambos os estimadores. No modelo de análise de covariância, quanto maior o tamanho amostral e o coeficiente de determinação, melhor se comportam os estimadores avaliados com relação à acurácia e à precisão. As conclusões encontradas sugerem que o estimador Plug-in obteve desempenho superior, tanto na acurácia quanto na precisão em situações de normalidade, nas diferentes configurações analisadas sobre o modelo avaliado. Quando os estimadores foram avaliados no modelo de ANCOVA com os resíduos distribuídos pela Gama, obtiveram o pior desempenho em relação a quando eram avaliados pelas demais distribuições.
erros de medida; viés; acurácia
The present paper approaches the covariance analysis model with one factor and measurement error in the covariate. Accuracy and precision of two estimators suggested in the literature were evaluated through data simulation, for estimating parameters of a regression model with measurement error. So called Plug-in method estimates the real value based on the observed ones and then uses the common function for estimating the desired parameter. The other estimator, known as bias smoother, only performs a bias correction on the usual estimator by computing a factor. Behavior of both estimators was studied under different residual distributions, goodness of fit and sample sizes. It is worth noting that, in covariance analysis model, the high the sample size, the better for accuracy and precision. Results suggest that the Plug-in estimator presented the best performance both for accuracy and precision under normality, for the distinct evaluated situations. When the estimators had been evaluated in the model of ANCOVA with the residues distributed for Gamma, the same ones had gotten the worse performance in relation when they were evaluated by the others distributions.
error in variables; bias; accuracy
ARTIGOS CIENTÍFICOS
AGRONEGÓCIO
Métodos de estimação de parâmetros em modelo de covariância com erro na covariável
Parameter estimation methods in covariance model with error in covariate
Tiago Almeida de OliveiraI,1 1 Autor para correspondência. ; Augusto Ramalho de MoraisII; Marcelo Angelo CirilloII
IDepartamento de Estatística, Universidade Estadual da Paraíba (UEPB), 58429-500, Campina Grande, PB, Brasil. E-mail: tiagoestatistico@gmail.com
IIDepartamento de Ciências Exatas, Universidade Federal de Lavras (UFLA), Lavras, MG, Brasil
RESUMO
Estudou-se o modelo de análise de covariância com um fator e erro de medida na covariável. Avaliou-se, neste modelo, por meio de simulação, a acurácia e precisão de dois estimadores, propostos na literatura para estimar parâmetros de um modelo de regressão com erro de medida. Sobre diferentes distribuições dos resíduos, coeficientes de determinação e tamanhos amostrais, estudou-se o comportamento de ambos os estimadores. No modelo de análise de covariância, quanto maior o tamanho amostral e o coeficiente de determinação, melhor se comportam os estimadores avaliados com relação à acurácia e à precisão. As conclusões encontradas sugerem que o estimador Plug-in obteve desempenho superior, tanto na acurácia quanto na precisão em situações de normalidade, nas diferentes configurações analisadas sobre o modelo avaliado. Quando os estimadores foram avaliados no modelo de ANCOVA com os resíduos distribuídos pela Gama, obtiveram o pior desempenho em relação a quando eram avaliados pelas demais distribuições.
Palavras-chave: erros de medida, viés, acurácia.
ABSTRACT
The present paper approaches the covariance analysis model with one factor and measurement error in the covariate. Accuracy and precision of two estimators suggested in the literature were evaluated through data simulation, for estimating parameters of a regression model with measurement error. So called Plug-in method estimates the real value based on the observed ones and then uses the common function for estimating the desired parameter. The other estimator, known as bias smoother, only performs a bias correction on the usual estimator by computing a factor. Behavior of both estimators was studied under different residual distributions, goodness of fit and sample sizes. It is worth noting that, in covariance analysis model, the high the sample size, the better for accuracy and precision. Results suggest that the Plug-in estimator presented the best performance both for accuracy and precision under normality, for the distinct evaluated situations. When the estimators had been evaluated in the model of ANCOVA with the residues distributed for Gamma, the same ones had gotten the worse performance in relation when they were evaluated by the others distributions.
Key words: error in variables, bias, accuracy.
INTRODUÇÃO
A análise de covariância (ANCOVA) é comumente descrita para o ajuste de variáveis que não podem ser controladas pelo pesquisador. É uma técnica estatística bastante utilizada para análise de dados originados de pesquisas, na qual uma variável dependente (y) é relacionada com uma variável independente (x) para proceder a um ajustamento das médias dos tratamentos, em que cada variável quantitativa independente adicionada ao estudo é chamada de variável concomitante, covariável ou variável auxiliar (NETER et al., 2004).
Os textos clássicos da estatística experimental sobre ANCOVA, como FEDERER (1955), MONTGOMERY (2009), entre outros, consideram a covariável x de efeito fixo e medida sem erro. No entanto, nem sempre essa suposição é satisfeita, sendo o mais comum não se ter acesso aos seus verdadeiros valores.
Geralmente, ao se estimar os parâmetros de uma função, o interesse recai em verificar se a presença de erros de mensuração pode afetar a precisão dos estimadores (BOLFARINE et al., 1992). Foram desenvolvidos estimadores para modelar dados com erros nas covariáveis, dentre eles, existem os estimadores de JAMES & STEIN (1961) e FULLER (1987), conhecidos também como estimadores Plug-in e atenuador de vício, respectivamente, que foram desenvolvidos com o intuito de minimizar os riscos de incerteza, diminuindo o efeito do erro de medida. A diferença na formalização desses métodos, citada por CUNHA & COLOSIMO (2003), é que os estimadores Plug-in estimam o valor verdadeiro por meio dos valores observados e, de posse dos respectivos valores ajustados, utilizam a função de estimação usual no modelo para estimar o parâmetro de interesse e o estimador atenuador de vício realiza uma correção no vício a partir do estimador usual.
A análise de covariância com erro de medida com aplicação na área agronômica foi abordada, entre outros, por DEGRACIE & FULLER (1972), que propuseram estimadores para o coeficiente de regressão b, considerando o modelo com erros nas variáveis, que têm viés em menor ordem e erro quadrático médio, em relação ao estimador usual de mínimos quadrados.
A distribuição estatística do erro nem sempre é fácil de ser obtida, tornando-se complexa a inferência e a formulação de métodos de estimação. Uma alternativa para solucionar esse problema é o uso de técnicas de simulação Monte Carlo e métodos de computação intensiva. Como os erros nas variáveis podem estar presentes em um experimento, verifica-se a necessidade de realizar aferições do erro na medida de suas variáveis por meio do estudo da acurácia e precisão (BARKER & ROSE, 1984).
Uma vez que não se conhece o comportamento dos estimadores quando estes são aplicados ao modelo de ANCOVA com erro nas covariáveis e é de conhecimento que, nesse modelo, as estimativas de mínimos quadrados são viciadas, objetivou-se avaliar os dois métodos de estimação de parâmetros (Plug-in e Atenuador de vício), por meio de acurácia e precisão, considerando diferentes distribuições nos resíduos de um modelo linear simples de ANCOVA com erro nas covariáveis com uso de simulação Monte Carlo.
MATERIAL E MÉTODOS
A metodologia utilizada neste trabalho considerou um modelo de ANCOVA com uma covariável, supondo que exista uma relação linear entre a variável independente (covariável) e a variável dependente. O modelo de análise de covariância considerado neste trabalho é semelhante ao mencionado por SEARLE (1997) e foi definido por  . Para esse modelo, sem perda de generalidades, considerou-se como pólo de comparação um experimento conduzido em delineamento inteiramente casualizado com quatro tratamentos, em que y é o vetor das observações da variável resposta de dimensões n x 1; X é a matriz de incidência dos tratamentos nas repetições, de valores (0,1) de dimensão n x 5; β é o vetor de parâmetros relativos à média geral µ e aos correspondentes efeitos do fator, de dimensões 5 x 1; Z é o vetor cujos componentes são os valores da covariável ou variável independente, de dimensões n x 1; γ é o vetor do coeficiente de regressão associado à covariável de dimensões 1 x 1; ε é o vetor de erros experimentais, de dimensões n x 1. O pesquisador pode ter motivos para acreditar que o valor observado da covariável não corresponde ao valor exato, contendo algum erro. O erro de medida pode ser incorporado em um modelo linear, por meio da relação, zij=xij+uij, sendo xij o valor ideal (observado sem erro de medida), zij o valor observado e uij uma variável aleatória que representa o erro de medida não observável.
. Para esse modelo, sem perda de generalidades, considerou-se como pólo de comparação um experimento conduzido em delineamento inteiramente casualizado com quatro tratamentos, em que y é o vetor das observações da variável resposta de dimensões n x 1; X é a matriz de incidência dos tratamentos nas repetições, de valores (0,1) de dimensão n x 5; β é o vetor de parâmetros relativos à média geral µ e aos correspondentes efeitos do fator, de dimensões 5 x 1; Z é o vetor cujos componentes são os valores da covariável ou variável independente, de dimensões n x 1; γ é o vetor do coeficiente de regressão associado à covariável de dimensões 1 x 1; ε é o vetor de erros experimentais, de dimensões n x 1. O pesquisador pode ter motivos para acreditar que o valor observado da covariável não corresponde ao valor exato, contendo algum erro. O erro de medida pode ser incorporado em um modelo linear, por meio da relação, zij=xij+uij, sendo xij o valor ideal (observado sem erro de medida), zij o valor observado e uij uma variável aleatória que representa o erro de medida não observável.
O estimador proposto por JAMES & STEIN (1961) pode ser utilizado para a determinação ou ajuste dos valores zij (i=1,..,I;j=1, ,K) da covariável observada com o erro de medida, obtida nas k repetições e I tratamentos. Essas repetições são independentes e identicamente distribuídas por uma distribuição normal com média χi e variância σu2 . O estimador de JAMES & STEIN (1961) parte do pressuposto de ajustar um novo valor para a covariável zij. Para isso, utilizou-se a expressão  < com i=1, ,I, sendo que
< com i=1, ,I, sendo que  corresponde à média das k repetições; Su2 refere-se ao estimador da variância do erro de medida, ao estimador da distância do valor observado para a média das repetições , com
corresponde à média das k repetições; Su2 refere-se ao estimador da variância do erro de medida, ao estimador da distância do valor observado para a média das repetições , com  em que
em que  .
.
O estimador proposto por FULLER (1987) baseou-se na determinação do viés (ou tendência erro/desvio) produzido pelo erro na observação dos dados. Ele é conhecido na literatura como estimador atenuador de vício. Para a obtenção do estimador, é necessário determinar, inicialmente, o fator,  .
.
FULLER (1987) descreve valores de kx-1 para diversas variáveis quando é considerado conhecido. Por exemplo, mensuração de erro em torno de 15% para variação observada para renda. Entretanto, segundo BOLFARINE & CORDANI (1993), há um grande número de situações em que kx-1 não é conhecido, mas pode ser estimado e, desse modo, ser tratado como conhecido. Quando isso ocorre, pode-se estimar o fator de Fuller por meio da expressão  ,em que Sz2 corresponde à variância amostral da covariável ajustada com o erro de medida e Su2 refere-se ao estimador da variância do erro de medida. Com base nesse fator, o estimador de menor vício foi obtido calculando
,em que Sz2 corresponde à variância amostral da covariável ajustada com o erro de medida e Su2 refere-se ao estimador da variância do erro de medida. Com base nesse fator, o estimador de menor vício foi obtido calculando  , em que
, em que  referi-se ao estimador de mínimos quadrados.
referi-se ao estimador de mínimos quadrados.
Para verificar se o coeficiente de determinação pode afetar no processo de estimação, diferentes situações foram consideradas: tamanhos amostrais, distribuições dos erros e os estimadores avaliados (JAMES & STEIN, 1961; FULLER, 1987). Os diferentes valores para o coeficiente de determinação R2 foram previamente fixados em 20%; 50%; 70% e 90% sob a restrição da equação  , sendo Eyy a soma de quadrados do erro na variável dependente;
, sendo Eyy a soma de quadrados do erro na variável dependente;  a soma de quadrados para o parâmetro regressivo e R2 o coeficiente de determinação do modelo.
a soma de quadrados para o parâmetro regressivo e R2 o coeficiente de determinação do modelo.
A adoção de diferentes diferentes distribuições para os resíduos teve como objetivo avaliar o comportamento dos estimadores sob a violação de normalidade, assim como compará-los quando a normalidade está presente. Para isso, adotaram-se as seguintes distribuições: Normal padrão (0,1), Uniforme (0,1) e a Gama (4,1), tendo esta última sido escolhida por ter um comportamento assimétrico. Desse modo, a avaliação de acurácia e precisão abrangem diferentes configurações. Para se obter uma variável aleatória das distribuições citadas, foram utilizadas rotinas construídas no software estatístico R, versão, 2.9.2. (R Core Development Team, 2009). Foram simuladas diferentes situações, considerando as configurações que a covariável assume nas distintas repetições, ou seja, as distribuições envolvidas e os coeficientes de determinação do modelo.
Para cada situação simulada (coeficiente de determinação, diferentes distribuições do erro e tamanhos amostrais), as estimativas dos parâmetros do modelo, obtidas por meio das equações dos estimadores de James-Stein e Fuller, respectivamente, foram avaliadas a acurácia, por meio do viés médio, pela expressão  , em que N representa as 5000 simulações monte Carlo e yl é a l-ésima observação.
, em que N representa as 5000 simulações monte Carlo e yl é a l-ésima observação.
A precisão das estimativas foi verificada por meio da raiz quadrada média do erro de predição. A RQMEP ou RMSPE (root mean square prediction error) (BIBBY & TOUTENBURG, 1977) é uma medida de quanto às predições se adequam bem aos dados observados, definida por  .
.
Possivelmente, em algumas situações, o viés médio (Vm) poderá ser relativamente alto, devido à falta de acurácia. Nesse caso, ocorrerá um inflacionamento da estimativa do Rqmep. Em virtude desse problema, julgou-se necessário avaliar a precisão por meio do erro residual, sendo este corrigido pela falta de acurácia:  .
.
A acurácia do parâmetro de regressão associado à covariável foi avaliada e, para o parâmetro de regressão, adotaram-se os valores 0,2; 0,5 e 0,8, com o objetivo de verificar o comportamento dos estimadores nas diferentes distribuições, coeficientes de determinação e tamanhos amostrais.
RESULTADOS E DISCUSSÃO
Com o propósito de avaliar o comportamento do estimador Plug-in, em uma situação de baixa qualidade de ajuste, foi gerado um modelo linear pré-fixando o valor do R2= 20%. Comparando o viés médio obtido no ajuste dos três modelos diferenciados pela distribuição dos resíduos Normal (0,1), Uniforme (0,1) e Gama (4,1), percebe-se que, no caso de amostras menores (n=16), os estimadores foram menos acurados, pois apresentaram vieses superiores a 10% (Figura 1A) sob todas as distribuições, ato este esperado, pois, na experimentação, ao se utilizar um estimador para um parâmetro de um modelo estatístico, a comparação entre as médias é recomendada apenas para um mínimo de 20 parcelas. Percebe-se, no entanto, que o tamanho amostral (n=40) é apropriado para esse "modelo", sobre normalidade dos resíduos, pois, a partir deste tamanho amostral, o ganho em acurácia é muito pequeno.
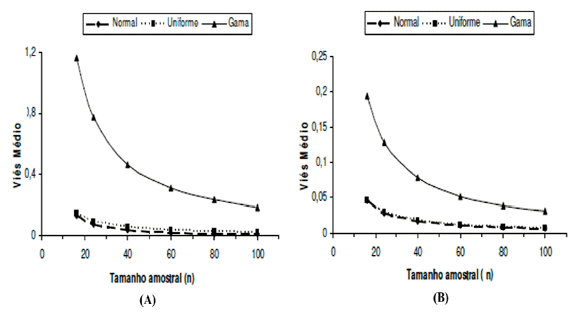
A baixa acurácia foi mais pronunciada (dez vezes maior) ao considerar o modelo com os resíduos dados pela distribuição Gama (4,1). Esses resultados, considerando um baixo coeficiente de determinação, estão de acordo com os encontrados por CHAN et al. (2004), em que os estimadores que consideram os erros nas covariáveis são viesados em pequenas amostras, mesmo na melhor situação simulada para essa qualidade de ajuste (n=100), o viés médio do estimador Plug-in sob a distribuição Gama (4,1) não se aproximou suficientemente do viés médio das distribuições normal e uniforme, sendo superior a 18%. O aumento do tamanho amostral propiciou uma melhoria na acurácia, em virtude de o viés médio ter sido reduzido nos três casos, chegando perto de 1% para as distribuições Normal padrão e Uniforme. WHITTEMORE (1989) obteve resultados parecidos, pois, conforme o tamanho da amostra aumentava, a raiz quadrada do quadrado médio do erro diminuía, indicando uma melhora assintótica para o estimador de James-Stein.
Aumentando o coeficiente de determinação, R2=90%, os resultados evidenciaram que os modelos com os resíduos gerados da distribuição Normal (0,1) e Uniforme (0,1) foram mais acurados (Figura 1B), tendo um comportamento similar em todos os tamanhos amostrais estudados, incluindo até mesmo as amostras menores, nas quais o viés médio não ultrapassou 5% em nenhum dos dois casos. O modelo, quando os resíduos eram distribuídos pela Gama (4,1), para grandes valores da amostra (n=100), teve um ganho considerável (cinco vezes) em relação ao mesmo modelo, quando o coeficiente de determinação era pequeno. Mesmo assim, o modelo de ANCOVA, quando distribuído pela Gama, obteve a pior acurácia.
As estimativas dos parâmetros dos modelos (Normal, Uniforme e Gama), obtidas pelo estimador de Fuller (atenuador de vício), para o caso de baixo coeficiente de determinação, R2=20% (Figura 1C), apresentou viés médio muito semelhante ao obtido pelo estimador Plug-in (Figura 1A), sendo que os vieses são menores quando os erros têm distribuição Normal. Porém, existe uma leve vantagem para o estimador Plug-in sobre essa distribuição.
Com um alto coeficiente de determinação, R2=90% (Figura 1D), pode-se verificar que o viés médio estimado para todos os tamanhos amostrais avaliados foram semelhantes aos encontrados para o estimador Plug-in (Figura 1B). Esse fato permitiu inferir que, mediante o alto coeficiente de determinação, ambos os métodos foram precisos, porém acurados apenas para os modelos com distribuições Normal e Uniforme, com um pequeno destaque para a distribuição simétrica.
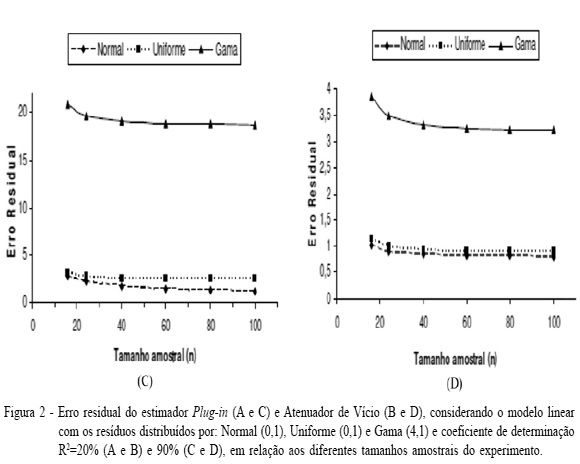
O modelo com os resíduos gerados por meio da distribuição Gama (4,1), utilizando o estimador Plug-in, foi o menos preciso em relação aos demais. Esse comportamento foi verificado para todos os tamanhos amostrais e diferentes coeficientes de determinação, especificados, respectivamente, pelos valores de R2=20 e 90% (Figura 2A e 2B). Em relação às distribuições Normal (0,1) e Uniforme (0,1) dos resíduos, confrontando ambos os modelos com diferentes valores de R2, notou-se que ambos apresentaram alta precisão, confirmada pelos baixos valores do erro residual, quando estes apresentam alta explicação da variabilidade amostral.

Em se tratando dos modelos lineares com o estimador dos parâmetros dados pelo método de FULLER (1987), considerando coeficiente de determinação, R2=20% (Figura 2C) e R2=90% (Figura 2D), observou-se praticamente a mesma precisão ao comparar-se o erro residual dos modelos, cujas estimativas foram obtidas pelo método Plug-in, apresentadas nas figuras 2A e 2B, respectivamente. Um resultado de destaque entre os estimadores é quando se comparam os coeficientes de determinação, pois, claramente, percebe-se que o coeficiente de determinação (R2) obteve grande influência na precisão do estimador, principalmente quando os resíduos são distribuídos pela Gama (4,1), de forma que a precisão foi seis vezes maior na situação de alto coeficiente. Porém, entre os estimadores, os valores não foram tão incisivos, pelo fato de que os métodos de JAMES-STEIN (1961) e FULLER (1987) obtiveram valores próximos sobre tamanho amostral alto (n=100) e alto coeficiente de determinação (R2=90%), tanto para a precisão quanto para a acurácia, com leve vantagem para o estimador Plug-in, em todas as distribuições dos resíduos. Esses resultados estão em conformidade com os obtidos por CUNHA & COLOSIMO (2003), que obtiveram intervalos de confiança por meio da técnica bootstrap. O estimador James-Stein obteve melhor desempenho que o estimador de Fuller, com intervalos de confiança menores.
Avaliando-se os resultados referentes aos vieses das estimativas do coeficiente de regressão γ na tabela 1, observa-se que os métodos de estimação foram acurados e precisos em todas as situações envolvendo os modelos nas diferentes distribuições dos resíduos, coeficientes de determinação e tamanhos amostrais, simuladas conforme os valores de R2 previamente fixados. Cabe salientar que foram estudados os valores de R2 (20,50,70 e 90%), mas para efeito de visualização optou-se por colocar os valores de baixo (20%) e alto coeficiente de determinação (90%), por julgar serem os de maior importância (Tabela 1).
De maneira geral, quando os estimadores foram avaliados considerando as distribuições dos resíduos, Normal e Uniforme (Tabela 1), o estimador de James-Stein foi mais acurado que o estimador de Fuller, com melhora na acurácia à medida que o tamanho amostral e o coeficiente de determinação aumentaram. Quanto ao parâmetro regressivo, não houve um comportamento homogêneo para a acurácia, não havendo uma tendência clara de melhora à medida que houve acréscimo em γ. Quando o parâmetro γ foi avaliado com baixa relação entre a variável independente e dependente (γ=0,2), o estimador de Fuller obteve melhor acurácia que o estimador de James-Stein na situação de grandes amostras (n=100).
Novamente, sob a distribuição Gama (Tabela 1), houve uma tendência geral de melhora para a acurácia à medida que o tamanho da amostra, o coeficiente de determinação do modelo e o parâmetro regressivo aumentavam. Para γ=0,8, a maior diferenciação entre a acurácia dos métodos Plug-in e atenuação de vício foi restringida para os tamanhos amostrais (n=16 e 60), já que, sob estes tamanhos amostrais, o estimador de James-Stein superou o estimador de Fuller. Quando comparado os estimadores no tamanho amostral (n=100), percebeu-se que, conforme o coeficiente de determinação aumentava, o estimador atenuador de vício diminuía a sua diferença de acurácia para o estimador Plug-in. Esse fato ocorreu para todos os coeficientes de determinação simulados e sobre o tamanho amostral (n=100), sendo que o estimador de FULLER (1987) superou o estimador de James-Stein no coeficiente (R2=90%). Esses resultados retrataram uma vantagem desse método em situações de falta de normalidade na estimação do parâmetro de regressão γ em grandes amostras.
CONCLUSÃO
Foi possível diferenciar entre os estimadores avaliados. Os estudos de simulação demonstraram que o método Plug-in obteve melhor desempenho em relação ao atenuador de vício, quanto à acurácia e à precisão em situações de normalidade, nos diferentes tamanhos amostrais e coeficientes de determinação estudados.
AGRADECIMENTO
Ao Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq), pela concessão da bolsa de estudos.
Recebido para publicação 19.07.10
Aprovado em 21.06.11
Devolvido pelo autor 04.09.11
CR-3850
- BARKER, D.J.P.; ROSE, G. Epidemiology in medical practice London: Churchill Living-stone, 1984. 151p.
- BIBBY, J.; TOUTENBURG, H. Prediction and improved estimation in linear models London: John Wiley, 1977. 188p.
- BOLFARINE, H.; CORDANI, L.K. Estimation of a structural linear regression model with a known reliability ratio. Annals of the Institute of Statistical Mathematics, v.45, p.531-540,1993. Disponível em: <http://dx.doi.org/10.1007/BF00773353>. Acesso em: 20 out. 2008. doi: 10.1007/BF00773353.
- BOLFARINE, H. et al. On the estimation of the size of a finite and closed population. Biometrical Journal, v.5, p.577-593, 1992. Disponível em: <http://dx.doi.org/10.1002/bimj.4710340507>. Acesso em: 8 jul. 2008. doi: 10.1002/bimj.4710340507.
- CHAN, S.F. et al. Adjustment for baseline measurement error in randomized controlled trials induces bias. Controlled Clinical Trials, v.25, p.408-416, 2004. Disponível em: <http://dx.doi.org/10.1016/j.cct.2004.06.001>. Acesso em: 11 jan. 2009. doi: 10.1016/j.cct.2004.06.001.
- CUNHA, W.J.; COLOSIMO, E.A. Intervalos de confiança bootstrap para modelos de regressão com erros de medida. Revista de Matemática e Estatística, v.21, n.2, p.25-41, 2003. ISSN 0102-0811.
- FEDERER, W.T. Experimental design New York: Macmillan, 1955. Chap.16.
- FULLER, W.A. Measurement error models New York: Wiley, 1987 440p.
- FULLER, W.A.; DEGRACIE, J.S. Estimation of the slope and analysis of covariance when the concomitant variable is measured with error. Journal of the American Statistical Association, v.67, n.340, p.930-937, 1972.
- JAMES, W.; STEIN, C. Estimation with quadratic loss. In: BERKELEY SYMPOSIUM ON MATHEMATICS, STATISTICS AND PROBABILITY, 4., 1961, Berkeley. Proceedings... Berkeley: University of California, 1961. V.1, p.361-380.
- MONTGOMERY, D.C. Design and analysis of experiments New York: Jonh Wiley and Sons, 2009. 656p.
- NETER, J. et al. Applied linear statistical models Sidney: Richard D. Irwin, 2004. 1408p.
- R Development Core Team. R: a language and environment for statistical computing Vienna, Austria: R Foundation for Statistical Computing, 2009. Disponível em: <http://www.R-project.org>. Acesso em: 01 jun. 2009. ISBN 3-900051-07-0.
- SEARLE, S.R. Linear models New York: John Wiley & Sons, 1997. 532p.
- WHITTEMORE, A.S. Errors-in-variables regression using Stein estimates. American Statician, v.43, n.4. p.226-228, 1989. ISSN: 00031305.
Datas de Publicação
-
Publicação nesta coleção
11 Nov 2011 -
Data do Fascículo
Out 2011
Histórico
-
Aceito
21 Jun 2011 -
Recebido
19 Jul 2010