Abstract
This paper joins the main properties of joint regression analysis (JRA), a model based on the Finlay-Wilkinson regression to analyse multi-environment trials, and of the additive main effects and multiplicative interaction (AMMI) model. The study compares JRA and AMMI with particular focus on robustness with increasing amounts of randomly selected missing data. The application is made using a data set from a breeding program of durum wheat (Triticum turgidum L., Durum Group) conducted in Portugal. The results of the two models result in similar dominant cultivars (JRA) and winner of mega-environments (AMMI) for the same environments. However, JRA had more stable results with the increase in the incidence rates of missing values.
AMMI models; genotype by environment interaction; joint regression analysis; missing values; durum wheat
NOTE
A comparison between Joint Regression Analysis and the Additive Main and Multiplicative Interaction model: the robustness with increasing amounts of missing data
Paulo Canas RodriguesI; Dulce Gamito Santinhos PereiraII; João Tiago MexiaI
IUniversidade Nova de Lisboa/Faculdade de Ciências e Tecnologia/CMA Depto. de Matemática 2829-516 Caparica, Portugal
IIUniversidade de Évora /Colégio Luís António/CIMA Depto. de Matemática, Rua Romão Ramalho, 59 7000-671 Évora, Portugal
Corresponding author Corresponding author : < paulocanas@fct.unl.pt>
ABSTRACT
This paper joins the main properties of joint regression analysis (JRA), a model based on the Finlay-Wilkinson regression to analyse multi-environment trials, and of the additive main effects and multiplicative interaction (AMMI) model. The study compares JRA and AMMI with particular focus on robustness with increasing amounts of randomly selected missing data. The application is made using a data set from a breeding program of durum wheat (Triticum turgidum L., Durum Group) conducted in Portugal. The results of the two models result in similar dominant cultivars (JRA) and winner of mega-environments (AMMI) for the same environments. However, JRA had more stable results with the increase in the incidence rates of missing values.
Keywords: AMMI models, genotype by environment interaction, joint regression analysis, missing values, durum wheat.
Introduction
Joint Regression Analysis (JRA) has been widely used in crop sciences, to structure and understand Genotype by Environment Interaction (GEI) (Eberhart and Russell, 1966; Finlay and Wilkinson, 1963; Gusmão, 1985; Mooers, 1921; Pereira and Mexia, 2008; Yates and Cochran, 1938; Zheng et al., 2009), and in genetics, to analyse quantitative trait loci (QTL) by environment interaction (Emebiri and Moody, 2006; Korol et al., 1998). In this paper we are mainly interested in the approach proposed by Gusmão (1985) in which the precision in analysing series of randomized block experiments was highly increased, by considering environmental indexes for individual blocks instead of only one environmental index per experiment. In the literature some variants of JRA are also denoted as SREG (Sites Regression) model (Cornelius et al., 1992; Crossa et al., 2002; Setimela et al., 2007).
Williams (1952), Gollob (1968), Mandel (1971), Bradu and Gabriel (1978) and Gauch (1988) have made an important contribution to the development of additive main effects and multiplicative interaction (AMMI) models. These models have been widely used to analyze multi-environment trials because of their flexibility in allowing the use of several multiplicative terms to explain the GEI. One of the difficulties in choosing the right tool to analyse multi-environment trials arises when there are missing values in the two-way table of genotypes and environments. These missing values can be either systematic (Calinski et al., 1992; Denis and Baril, 1992), or selected completely at random in the two-way table.
This paper brings together the main features of JRA and AMMI models, and compares them for analyzing a durum wheat (Triticum turgidum L., Durum Group) trial with particular focus on robustness with increasing amounts of random missing data, either missing replications or missing cells (more likely when the proportion of missing values is high). The aim here is not to compare the method's ability to estimate missing values in comparison to real data (Alarcón et al., 2010; Bergamo et al., 2008) but to compare the overall stability when increasing the incidence rate of missing values. An emphasis is made in the comparison between (i) the upper contour of JRA and the mega-environments of the AMMI model; and (ii) the stability of the dominant/winner genotypes across environments. To obtain the results for the JRA we developed an R code, and the MATMODEL software (Gauch and Furnas, 1991) was used to fit the AMMI models.
Materials and Methods
Joint regression analysis
JRA has proven to be an important model for analysing and interpreting the GEI of two-way classified data tables and continues to be largely used as a complement of traditional statistical analysis in genetics, plant breeding, and agronomy, for determining yield stability of different genotypes or agronomic treatments across environments (Crossa, 1990). JRA may also be used for the analysis of series of experiments in genotype comparison and selection. This technique is based on the adjustment of a linear regression, per genotype, of the yield on a synthetic variable measuring productivity, the environmental index.
JRA, when applied to two-way tables obtained from multi-environment trials, aims to determine the stability of the genotypes or agronomic treatments over a wide range of environmental conditions and to interpret the interaction (non-additivity). Let Yij be a continuous response variable (usually yield) corresponding to a row factor j, j = 1, ..., J (usually the genotypes), and a column factor j, j = 1, ..., J (usually the environments). The model used for the analysis of multi-environment variety trials can be defined as

where μ is the grand mean, Gi and Ej are the genotype and environment main effects, (GE)ij is the interaction and εij is the residual. A sub-model of (1), aiming at estimating some stability parameters for making comparisons between varieties is given by JRA, and allows us to partitioning the GEI into two parts of interest, i.e.

where bi is a linear regression coefficient for the i-th genotype and δij a deviation (unexplained GEI) (Freeman, 1973). The JRA model can then be written as
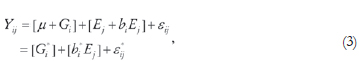
where eij comprises both the unexplained GEI and the experimental error (Shukla, 1972). We assume fixed genotypic and environmental effects and random residual term.
The model (3) used in the present paper does not take into account the block effects since it uses the blocks as environments, following Gusmão (1985). If an experiment is designed with randomized blocks and the treatments correspond to the J genotypes to be compared, for each block in each design, the environmental index is measured by the average yield. For each of the J genotypes, a linear regression of yield on environmental indexes is adjusted.
L2 environmental indexes
For convenience, let us consider the joint regression model of the second equation in (3), where 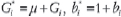 , Ej, j = 1, ... b, is the environmental index corresponding to blocks instead of environments, b the number of blocks, Yij is a continuous response (e.g. yield) for cultivar/genotype i in block j if present, and the pairs
, Ej, j = 1, ... b, is the environmental index corresponding to blocks instead of environments, b the number of blocks, Yij is a continuous response (e.g. yield) for cultivar/genotype i in block j if present, and the pairs 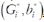 , i = 1,..., I, are the regression coefficients, for the I genotypes.
, i = 1,..., I, are the regression coefficients, for the I genotypes.
To obtain the estimates for the regression coefficients and the environmental indexes, the goal function to be minimized should be
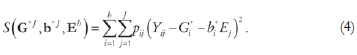
Usually the weight pij is 1 [0] when genotype i is present [absent] in block j. These weights may differ from block to block to express differences in representativeness of the blocks and thus we take pij = pj when the i-th genotype is present. The main problem in such modeling is how to estimate the parameters. However, the lately proposed so called zigzag algorithm (Pereira and Mexia, 2010) is very efficient in finding the estimates of (Gi*,bi*), i =1,...,I,and Ej, j = 1, b. This zigzag algorithm is an alternating least squares based algorithm (Calinski et al., 1992; Denis and Baril, 1992; Digby, 1979; Gabriel and Zamir, 1979; Gauch and Zobel, 1990). For the complete case, Pereira and Mexia (2010) presented an alternative algorithm, the double minimization algorithm, which converges to the absolute minimum of the goal function (4) and is an adaptation of the algorithm first presented by Fisher and Mackenzie (1923). More details on the zigzag and double minimization algorithms can be found in Pereira and Mexia (2010).
Upper contour
When two of the regressions on genotypes intersect it means that one of the genotypes is better for higher environmental indexes while the other is preferable for lower environmental indexes. The intersection of regressions shows more than one genotype with similar performance. The upper contour of the JRA is a concave polygonal (Mexia et al., 1997), constituted by segments of the adjusted regression lines, that contains the higher adjusted yields for the environmental indexes (Figure 1). Each of these segments will correspond to a range of variation of the environmental indexes in which the associated genotype will have the maximum adjusted yield (Pereira and Mexia, 2008). These genotypes are called dominant and should be selected. The remaining genotypes should be compared with the dominant to check whether they are dominated on entire range for the adjusted environmental indexes, [c, d]. If so, they can be safely discarded from the breeding program.
An analogy can be made between Figure 1 in this paper and Figure 2 in Gauch (1997), where the AMMI1 nominal yields for a corn trial is depicted as a function of the environment interaction principal component (IPC) axis 1. A more detailed comparison in what concerns the winner genotypes across the environments is presented latter in this paper.
Genotype comparison and selection
Let L be the number of dominant genotypes with dominant ranges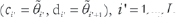 The entire range for the environmental indexes will be
The entire range for the environmental indexes will be 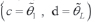 . To have interaction between genotypes and environments there are two possible cases for different slopes,
. To have interaction between genotypes and environments there are two possible cases for different slopes, 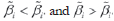 . After establishing the upper contour, non-dominant genotypes should be compared with the dominant ones. This comparison should be made on the left [right] extreme of the dominance range if the non-dominated genotypes have lower [greater] slope than the dominant one. So, when
. After establishing the upper contour, non-dominant genotypes should be compared with the dominant ones. This comparison should be made on the left [right] extreme of the dominance range if the non-dominated genotypes have lower [greater] slope than the dominant one. So, when 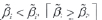 we are led to compare the adjusted values
we are led to compare the adjusted values 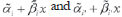 at the environmental index
at the environmental index 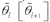 . These comparisons between slopes may be made using one of following statistical tools: (i) one-sided t tests for the null hypothesis; (ii) Scheffé multiple comparison tests (Scheffé, 1959); (iii) Bonferroni multiple comparison method (Seber and Lee, 2003); (iv) Tukey multiple comparison method (only for the complete case); and (v) Control of False Discovery Rate which is robust against erroneous rejections (Benjamini and Hochberg, 1995). More details of these tests can be found in Pereira and Mexia (2008).
. These comparisons between slopes may be made using one of following statistical tools: (i) one-sided t tests for the null hypothesis; (ii) Scheffé multiple comparison tests (Scheffé, 1959); (iii) Bonferroni multiple comparison method (Seber and Lee, 2003); (iv) Tukey multiple comparison method (only for the complete case); and (v) Control of False Discovery Rate which is robust against erroneous rejections (Benjamini and Hochberg, 1995). More details of these tests can be found in Pereira and Mexia (2008).
AMMI models
The core idea of the AMMI models is: (i) first apply the additive analysis of the variance model (ANOVA) to a two-way data (in the present case with genotypes and environments); and (ii) secondly apply the multiplicative principal component analysis (PCA) model to the residual from the additive model (in this case to the interaction) (Gauch, 1992). The AMMI model with N multiplicative terms can be written as
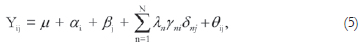
where Yij is the yield of genotype i in environment j; 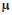 the grand mean;
the grand mean; 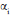 the genotype mean deviations (the genotype means minus the grand mean); βj the environment mean deviations;
the genotype mean deviations (the genotype means minus the grand mean); βj the environment mean deviations; 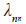 the singular value for the PCA axis n; γni and
the singular value for the PCA axis n; γni and 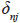 are the genotype and environment PCA scores for PCA axis n; N is the number of PCA axes retained by the model; and
are the genotype and environment PCA scores for PCA axis n; N is the number of PCA axes retained by the model; and 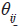 is the residual. If the experiment is replicated, an error term εijr, which is the difference between the Yij mean and the single observation for replicate r, should be added.
is the residual. If the experiment is replicated, an error term εijr, which is the difference between the Yij mean and the single observation for replicate r, should be added.
The main purposes of the AMMI models were pointed out by Crossa (1990): (i) model diagnosis (Bradu and Gabriel, 1978); (ii) to clarify GEI (Crossa et al., 1990; Zobel et al., 1988); and (iii) to improve the accuracy of yield estimates (Crossa et al., 1990; Zobel et al., 1988).
Durum Wheat Yield Data
All the properties and comparisons presented in this paper are illustrated with a data set resulting from a breeding program in Portugal, carried out by the Portuguese National Plant Breeding Station (ENMP, Elvas) in the years of 1992/1993 and 1993/1994. It contains the yield from nine genotypes (CELTA; HELVIO; TE9006; TE9007; TE9008; TE9110; TE9115; TE9204; and TROVADOR) of durum wheat (Triticum turgidum L., Durum Group), measured in 11 environments (Benavila1; Revilheira; Évora; Elvas1; Beja1; Tavira1; Elvas2; Tavira2; Elvas3; Benavila2 and Beja2), and performed in complete randomized blocks with four replicates. These environments were obtained in two years, the first 6 in the first and the second 5 in the second year. Only the locations Tavira, Benavila and Beja were the same in both years. All the locations in this data set are in south Portugal, Tavira being at the sea side (Algarve) while the remaining in the inland (Alentejo). More details about this data set can be found in Pereira and Mexia (2010).
Simulation of missing values
Since the plants may be destroyed by animals, floods or during the harvest, and the yield measurements may be erroneously performed and inadequately introduced in the data base, missing values are common in agricultural experiments. When dealing with missing values researchers should decide between: (i) find a good tool to estimate the missing values (Alarcón et al., 2010; Bergamo et al., 2008), or (ii) chose a robust technique against missing observations to perform the analysis. In the present study we will be interested in the second approach, namely to compare the robustness of JRA and AMMI with the increasing of missing data. Our interest here is to study the case where the missing values were selected completely at random, instead of having systematic patterns (Calinski et al., 1992; Denis and Baril, 1992).
Our simulation procedure can be summarized in the following steps:
(i) Choose the incidence rate of missing values α (e.g. α = 5, 10, 25, 50, 75 %);
(ii) Remove, randomly, α % of the two-way table with genotypes and environments, leaving at least one observation in each environment and in each genotype;
(iii) a. Use the zigzag algorithm (Pereira and Mexia, 2010) to compute the regression coefficients and the L2 environmental indexes for JRA by minimizing the loss function (4); Results such as those shown in Figure 1 and in Table 3 can be obtained using the appropriated multiple comparison tests mentioned above. b. Use the MATMODEL software (Gauch and Furnas, 1991) to estimate the missing values; Results such as those shown in Table 3 can be obtained by this software;
(iv) Repeat (ii) and (iii) n times for each incidence rate of missing values. The number of interactions n should be chosen based on the size of the original two-way table. In this particular case we used n=100.
For higher incidence rates of missing values it is more likely that not only replications are missing, but cells (means). In this case an Expectation-Maximization (EM) algorithm provides an effective general strategy for obtaining maximum likelihood estimates (Gauch, 1992). This procedure has been adapted for AMMI and is called EM-AMMI (Gauch and Zobel, 1990), and is implemented in the MATMODEL software (Gauch and Furnas, 1991).
Results and Discussion
A comparison between the algorithms and the alternative methods
This subsection presents a comparison between the two algorithms mentioned in the above section - (i) zigzag algorithm (Pereira and Mexia, 2010) and (ii) double minimization algorithm (Pereira and Mexia, 2010); and the two methods based in the joint regression model - (iii) the regression analysis of the mean yield of individual genotypes on the overall mean of the trial (Finlay and Wilkinson, 1963), and (iv) the regression analysis of the genotype mean yield on block mean, proposed by Gusmão (1985). This comparison is illustrated with a numerical example using the durum wheat yield population. Estimates of intercept, slope and the coefficients of determination, obtained from the Finlay and Wilkinson (1963) and Gusmão (1985) methods, and the zigzag and double minimization algorithms are presented in Table 1.
To compare these four procedures it is important to analyze the slopes and coefficients of determination. They produced almost the same results regarding the ordering of the genotypes per slope (only the Gusmãos method gave a small difference). The coefficients of determination are mainly similar, the zigzag and Double Minimization algorithms being lower than Gusmão (1985) only for three environments (HELVIO, TE9110 and TE9115). Moreover, the zigzag and double minimization have completely agreed and may be seen as the most suited for regression analysis of complete randomized blocks because of their convergence to the minimum of the loss function (4).
Another comparison can be made regarding the sums of the sums of squares of residuals for the two procedures and two algorithms (Table 2). Here the advantage of the zigzag and double minimization algorithms over the two other procedures is evident since the algorithms induce lower sums of the sums of squares of residuals. This result is true for all the examples and the mathematical proof can be found in Pereira and Mexia (2010). If we compute the pairwise Pearson correlations between the environmental indexes for the four alternatives in Table 2, we conclude that all the obtained environmental indexes are highly correlated (minimum of 0.984). In particular, the results obtained using the zigzag and double minimization algorithms have a coefficient of correlation of 1.000 since they completely agree with each other, and they are slightly better than the Finlay and Wilkinson (1963) and Gusmão (1985) approaches. In the case of a comparison using α-designs or incomplete blocks (instead of the randomized complete block design) some advantage within the two algorithms could better be presented (Pereira and Mexia, 2010).
Genotype comparison and selection
The results for some of the multiple comparison tests mentioned above can be found in Table 3. The graphical representation of the dominant genotypes, together with the ranges of dominance (i.e. the lower and upper bound for the interval where the each genotype is dominant) and environments where that dominance occurs, is depicted in Figure 1. The bounds of the environmental indexes 2.21 and 8.84 (Table 3, complete data) are kept unchanged by the zigzag algorithm and correspond to the lowest and highest mean yield of all the blocks.
AMMI preliminary analyses
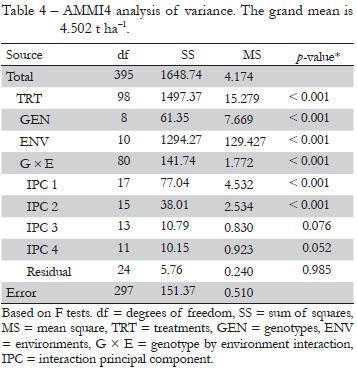
Table 4 gives the ANOVA for AMMI4. The genotypes, environments and GEI account for 4.1 %, 86.4 %, and 9.5 % of the treatment sum of squares (SS). The noise in the GEI may be estimated by the interaction df times the error MS, namely 40.80, which by difference from the total of 141.74 (total GEI SS) implies a GEI signal SS of 100.94, or 71.21 % (Gauch, 1992). Figure 2 shows the numbers of indirect replications for the AMMI model family from AMMI0 to AMMI8. The models are less parsimonious, or more complex, moving to the right. AMMI2 achieves the highest number of indirect replications of 1.66 (i.e. 1 replication gives 1.66 more information when considering the parsimonious AMMI2 model). To the left of this model, excessively simple models underfit the real signal, whereas to the right, excessively complex models overfit the spurious noise. This relationship between accuracy and parsimony has been named as Ockham's hill (Gauch, 2006; Mackay, 1992).
Since the signal is much simpler than the noise, the signal is extracted selectively in early model parameters whereas noise is extracted selectively in late model parameters. A parsimonious model, which captures most signals and discards most of the noise, can be chosen by stopping at the right point (Gauch, 1992). From Table 4 it is possible to obtain the SS of the GEI signal of 100.94 (total GEI SS minus noise in GEI) and the SS for the first two PCs together of 115.05 (77.04 for IPC1 and 38.01 for IPC2), which means that these two PCs are mostly signal whereas the remaining are mostly noise. The F tests in Table 4 also suggested retaining the first two PCs. For comparison with AMMI, the Finlay-Wilkinson linear regressions on environment mean capture a SS of 43.63, which is about 56.6 % of the GEI SS captured by IPC1.
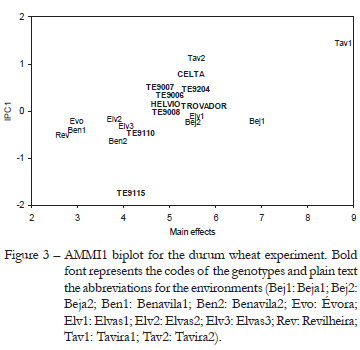
Figure 3 depicts the AMMI1 biplot for the durum wheat experiment. The choice of the AMMI1 biplot instead of AMMI2 was made to allow the comparison with Figure 1. The abscissa shows the main effects and the ordinate shows the IPC1 scores. The 9 genotypes are represented in bold font and the 11 environments in normal font. The first IPC captures 54.73 % (77.04/141.74) of the GEI sum of squares. But, since this GEI is only 71.23 % (100.94/141.74) signal, this graph captures the most of GEI signal and a small amount of noise (Gauch, 1992). With this biplot it is easier to understand the association between genotypes and environments where they perform better regarding grain yield.
IPC1 makes a distinction between Tavira (Algarve, sea side) and the rest of the environments (Alentejo, inland) (Figure 3). When comparing with Figure 1, we can see that the four dominant genotypes are ordered by IPC1 scores in Figure 3. This provides an agreement between the environmental indexes and IPC1 scores, and connects them to a measure of yield production. The order of environments along the main effects of Figure 3 and environmental indexes of Figure 1 is the same, as expected.
Upper contour and mega-environments
In this subsection we intend to make a comparison between the upper contour of JRA and the AMMI mega-environments (Gauch and Zobel, 1997). Figure 1 shows the 11 environments placed in the axis of the environmental indexes. The first three environments, namely Rev, Ben1 and Evo, have higher yield with the genotype TE9008, and the remaining eight environments have better production with the genotype CELTA. Following the same analysis using the AMMI mega-environments as Gauch and Zobel (1997), based on AMMI1 estimates, we may conclude that this data set has three winners: (i) CELTA wins in nine environments; (ii) TE9008 wins in the environment Rev; and (iii) TE 9115 wins in the environment Ben2. However the main conclusion is taken by both analyses: CELTA is the universal winner (Table 3).
Stability with missing values
JRA is an extremely robust technique against missing observations in what concerns genotype comparison and selection (Pereira et al., 2007). They used a series of 17 experiments of α−designs of winter rye genotypes, in the years of 1997 and 1998, and considered proportions of missing values from 5 % to 75 %, with step size of 5 % generated randomly in triplicate. The durum wheat data set was used here to test the stability and agreement in choosing the dominant genotypes for different incidence rates of missing values, between JRA and AMMI. Table 3 presents the main results for different incidence rates of missing values. The missing values were chosen randomly as described before.
The analysis of Table 3 should be performed between methods and between incidence rates of missing values. Regarding the comparison between methods, the most similar results are for the complete data without missing values, with eight environments having higher yield for the same (dominant/winner) genotypes. The number of environments dominated/won by the same genotypes decreases when increasing the proportion of missing values. The only exception is the case with 75 % of missing values, with 6 agreements between analyses, which is more likely to change each time the random procedure to remove observations is run.
Regarding the comparison between percentages of missing values, Table 3 (second, eighth and ninth columns) illustrates a more stable and robust performance of JRA, since the dominant genotypes are kept unchanged for an incidence of missing values until 50 %. While for JRA there are six environments (Rev, Elv1, Bej1, Tav1, Tav2 and Bej2) which are dominated by the same genotypes in all the cases (with exception of the extreme 75 % incidence rate of missing values), for the AMMI analysis it only happens in 4 environments (all of then are won by CELTA). Moreover for the AMMI model the genotype TE9008 and TE9115 only win in one of the five cases (incidence rates), while for the JRA the dominant genotypes are more stable.
Although the dominant genotypes have little change with the incidence rate of missing values it seems clear that CELTA is the strongest genotype regarding the yield production. It is always dominant for higher environmental indexes and always wins one mega-environment. With 75 % of missing values (297 out of 396 observations) the JRA yet identifies two of the dominant genotypes presented in the upper contour of Figure 1, while AMMI identifies a small mega-environment Elv3 and a larger mega-environment with the remaining ten environments (Table 3).
We carried out 100 simulations as described before, and Table 3 shows the results for one of them chosen randomly. The 100 data sets for each proportion of missing values resulted in the identification of, at least, one dominant/winner genotype coincident to the complete data set when considering 75 % of missing values. For 50 % or less JRA always identified TE9008 and CELTA as dominant genotypes, whereas TE9204 (not dominant/winner in the complete data set) and CELTA almost always win one AMMI mega-environment. A detailed summary of the 100 runs is presented in Table 5.
Conclusion
The aim was not to compute estimates of missing values and compare them with the original data, but to compare the final results (i.e. dominant/winner genotypes and environments where the were dominant/winner) between JRA and AMMI and between the complete data and incomplete data sets with different incidence rates of missing values. The main conclusions were the similarity between the dominant genotypes in JRA and the winners of the mega-environments in the AMMI analysis; and a more stable performance of JRA for higher proportions of missing values. The results from JRA trend to be more significant than those from AMMI models in these kind of trials, because the genotypes in the program have proved to have strong adaptability.
Acknowledgements
Paulo C. Rodrigues acknowledges financial support from Fundação para a Ciência e Tecnologia (Portuguese Foundation for Science and Technology), of Ministério da Ciência, Tecnologia, e Ensino Superior, Portugal, for doctoral grant SFRH/BD/35994/2007, and the project N N310 447838 supported by the Ministry of Science and Higher Education, Poland.
Edited by: Marcin Kozak
Received November 16, 2010
Accepted March 24, 2011.
- Alarcón, S.A.; Peńa, M.G.; Dias, C.T.S.; Krzanowski, W.J. 2010. An alternative methodology for imputing missing data in trials with genotype-by-environment interaction. Biometrical Letters 47: 1-14.
- Benjamini, Y.; Hochberg, Y. 1995. Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal Statistical Society Series B-Methodological 57: 289-300.
- Bergamo, G.C.; Dias, C.T.D.S.; Krzanowski, W.J. 2008. Distribution-free multiple imputation in an interaction matrix though singular value decomposition. Scientia Agricola 65: 422-427.
- Bradu, D.; Gabriel, K.R. 1978. Biplot as a diagnostic tool for models of 2-way tables. Technometrics 20: 47-68.
- Calinski, T.; Czajka, S.; Denis, J.B.; Kaczmarek, Z. 1992. EM and ALS algorithms applied to estimation of missing data in series of variety trials. Biuletyn Oceny Odmian 24-25: 9-31.
- Cornelius, P.L.; Seyedsadr, M.; Crossa, J. 1992. Using the shifted multiplicative model to search for separability in crop cultivar trials. Theoretical and Applied Genetics 84: 161-172.
- Crossa, J. 1990. Statistical analyses of multilocation trials. Advances in Agronomy 44: 55-85.
- Crossa, J.; Cornelius, P.L.; Yan, W.K. 2002. Biplots of linear-bilinear models for studying crossover genotype x environment interaction. Crop Science 42: 619-633.
- Crossa, J.; Gauch, H.G.; Zobel, R.W. 1990. Additive main effects and multiplicative interaction analysis of 2 international maize cultivar trials. Crop Science 30: 493-500.
- Denis, J.B.; Baril, C.P. 1992. Sophisticated models with numerous missing values: the multiplicative interaction model as an example. Biuletyn Oceny Odmian 24-25: 33-45.
- Digby, P.G.N. 1979. Modified joint regression-analysis for incomplete variety x environment data. Journal of Agricultural Science 93: 81-86.
- Eberhart, S.A.; Russell, W.A. 1966. Stability parameters for comparing varieties. Crop Science 6: 36-40.
- Emebiri, L.C.; Moody, D.B. 2006. Heritable basis for some genotype-environment stability statistics: Inferences from qtl analysis of heading date in two-rowed barley. Field Crops Research 96: 243-251.
- Finlay, K.W.; Wilkinson, G.N. 1963. Analysis of adaptation in a plant-breeding programme. Australian Journal of Agricultural Research 14: 742-754.
- Fisher, R.A.; Mackenzie, W.A. 1923. Studies in crop variation. II. The manurial response of different potato varieties. The Journal of Agricultural Science 13: 311-320.
- Freeman, G.H. 1973. Statistical-methods for analysis of genotype-environment interactions. Heredity 31: 339-354.
- Gabriel, K.R.; Zamir, S. 1979. Lower rank approximation of matrices by least-squares with any choice of weights. Technometrics 21: 489-498.
- Gauch, H.G. 1988. Model selection and validation for yield trials with interaction. Biometrics 44: 705-715.
- Gauch, H.G. 1992. Statistical analysis of regional yield trials: AMMI analysis of factorial designs. Elsevier, Amsterdam, The Netherlands.
- Gauch, H.G. 2006. Winning the accuracy game - three statistical strategies - replicating, blocking and modeling: can help scientists improve accuracy and accelerate progress. American Scientist 94: 133-141.
- Gauch, H.G.; Furnas, R.E. 1991. Statistical-analysis of yield trials with MATMODEL. Agronomy Journal 83: 916-920.
- Gauch, H.G.; Zobel, R.W. 1990. Imputing missing yield trial data. Theoretical and Applied Genetics 79: 753-761.
- Gauch, H.G.; Zobel, R.W. 1997. Identifying mega-environments and targeting genotypes. Crop Science 37: 311-326.
- Gollob, H.F. 1968. A statistical model which combines features of factor analysis and analysis of variance techniques. Psychometrika 33: 73-115.
- Gusmăo, L. 1985. An adequate design for regression-analysis of yield trials. Theoretical and Applied Genetics 71: 314-319.
- Korol, A.B.; Ronin, Y.I.; Nevo, E. 1998. Approximate analysis of QTL-environment interaction with no limits on the number of environments. Genetics 148: 2015-2028.
- Mackay, D.J.C. 1992. Bayesian interpolation. Neural Computation 4: 415-447.
- Mandel, J. 1971. New analysis of variance model for non-additive data. Technometrics 13: 1-18.
- Mexia, J.T.; Amaro, A.P.; Gusmao, L.; Baeta, J. 1997. Upper contour of a joint regression analysis. Journal of Genetics and Breeding 51: 253-255.
- Mooers, C.A. 1921. The agronomic placement of varieties. Journal of the American Society of Agronomy 13: 337-352.
- Pereira, D.G.; Mexia, J.T. 2008. Selection proposal of cultivars of spring barley in the years from 2001 to 2004, using joint regression analysis. Plant Breeding 127: 452-458.
- Pereira, D.G.; Mexia, J.T. 2010. Comparing double minimization and zigzag algorithms in joint regression analysis: the complete case. Journal of Statistical Computation and Simulation 80: 133-141.
- Pereira, D.G.; Mexia, J.T.; Rodrigues, P.C. 2007. Robustness of joint regression analysis. Biometrical Letters 44: 105-128.
- Scheffé, H. 1959. The Analysis of Variance. Wiley, New York, NY, USA.
- Seber, G.A.F.; Lee, A.J. 2003. Linear Regression Analysis. Wiley-Interscience, Hoboken, NJ, USA.
- Setimela, P.S.; Vivek, B.; Banziger, M.; Crossa, J.; Maideni, F. 2007. Evaluation of early to medium maturing open pollinated maize varieties in sadc region using gge biplot based on the sreg model. Field Crops Research 103: 161-169.
- Shukla, G.K. 1972. Some statistical aspects of partitioning genotype environmental components of variability. Heredity 29: 237-245.
- Williams, E.J. 1952. The interpretation of interactions in factorial experiments. Biometrika 39: 65-81.
- Yates, F.; Cochran, W.G. 1938. The analysis of groups of experiments. The Journal of Agricultural Science 28: 556-580.
- Zheng, B.S.; Le Gouis, J.; Daniel, D.; Brancourt-Hulmel, M. 2009. Optimal numbers of environments to assess slopes of joint regression for grain yield, grain protein yield and grain protein concentration under nitrogen constraint in winter wheat. Field Crops Research 113: 187-196.
- Zobel, R.W.; Wright, M.J.; Gauch, H.G. 1988. Statistical-analysis of a yield trial. Agronomy Journal 80: 388-393.
Corresponding author
Publication Dates
-
Publication in this collection
02 Feb 2012 -
Date of issue
Dec 2011
History
-
Received
16 Nov 2010 -
Accepted
24 Mar 2011