Resumos
This paper presents a proposal for optimizing the public health service in the state of Parana in terms of the flow of patients within the state's boundaries and the regionalization (division) of the state into new hierarchical configurations for this service. In terms of regionalization, the proposal consists of dividing the state into smaller regions comprising several towns connected to a headquarter city, which would be responsible for decisions affecting the region. With regard to the flow of patients, an algorithm is proposed which organizes the information while simultaneously optimizing the flow. The state was regionalized using a branch-and-price algorithm, which uses a column generating algorithm in each node of a branch-and-bound tree. The technique proposed here to optimize the patient flow proved effective and useful, controlling not only the medical procedures performed in each town but also defining the city to which each patient should be taken, according to the hierarchical division of the state. The branch-and-price algorithm used to optimize the regionalization of the state is very interesting, for it improves the hierarchical division of the state taking into account the number of inhabitants and the number of medical procedures in each city of the state. The results have met the expectations of State Health Services.
P-medians problem; Branch-and-price algorithm; Patient flow; Hierarchical configuration
Neste trabalho é apresentada uma proposta para a otimização no serviço de saúde no estado do Paraná com relação ao fluxo de pacientes dentro do estado e a regionalização (divisão) do estado, obtendo novas configurações hierárquicas para o mesmo. Quanto à regionalização, a proposta consiste em dividir o estado em regiões menores, formadas por várias cidades, vinculadas a uma cidade sede, principal responsável pelo atendimento no seu nível de resolutividade. Com relação ao fluxo de pacientes, é proposto um algoritmo que, ao mesmo tempo em que organiza as informações, otimiza o fluxo. Já para a regionalização, fez-se uso do algoritmo branch and price, que utiliza o algoritmo de geração de colunas em cada nó de uma árvore branch and bound. A técnica proposta apresentada para otimizar o fluxo de pacientes mostrou-se eficaz e útil, pois além de fazer o controle dos procedimentos médicos realizados em cada cidade, também define para qual cidade o paciente deve ser encaminhado, respeitando a divisão hierárquica do estado. Já o algoritmo branch and price, utilizado para a otimização na regionalização do estado, é bastante interessante, pois tenta melhorar a referida divisão hierárquica do estado, levando em consideração o número de habitantes e o número de procedimentos médicos de cada município do estado. Os resultados obtidos têm atendido às expectativas da SESA-PR.
Problema das p-medianas; Algoritmo branch and price; Fluxo de pacientes; Configurações hierárquicas
Otimização no serviço de saúde no estado do Paraná: fluxo de pacientes e novas configurações hierárquicas
Optimization of public health services in the state of Paraná: flow of patients and new hierarchical configurations
Cassius Tadeu ScarpinI; Maria Teresinha Arns SteinerI; Gláucio José Cardozo DiasII; Pedro José Steiner NetoII
IPrograma de Pós-graduação em Métodos Numéricos em Engenharia, Departamento de Matemática, Universidade Federal do Paraná UFPR, Setor de Tecnologia, Centro Politécnico s/n, Bloco Lame/Cesec, Jd Américas, CP 19081, CEP 81531-990, Curitiba, PR, Brasil, e-mails: cassiusts@yahoo.com.br; tere@ufpr.br
IIPrograma de Pós-graduação em Métodos Numéricos em Engenharia, Departamento de Administração, Universidade Federal do Paraná UFPR, Setor de Tecnologia, Centro Politécnico s/n, Bloco Lame/Cesec, Jd Américas, CP 19081, CEP 81531-990, Curitiba, PR, Brasil, e-mails: gláucio.dias@datasul.com.br; pedrosteiner@ufpr.br
RESUMO
Neste trabalho é apresentada uma proposta para a otimização no serviço de saúde no estado do Paraná com relação ao fluxo de pacientes dentro do estado e a regionalização (divisão) do estado, obtendo novas configurações hierárquicas para o mesmo. Quanto à regionalização, a proposta consiste em dividir o estado em regiões menores, formadas por várias cidades, vinculadas a uma cidade sede, principal responsável pelo atendimento no seu nível de resolutividade. Com relação ao fluxo de pacientes, é proposto um algoritmo que, ao mesmo tempo em que organiza as informações, otimiza o fluxo. Já para a regionalização, fez-se uso do algoritmo branch and price, que utiliza o algoritmo de geração de colunas em cada nó de uma árvore branch and bound. A técnica proposta apresentada para otimizar o fluxo de pacientes mostrou-se eficaz e útil, pois além de fazer o controle dos procedimentos médicos realizados em cada cidade, também define para qual cidade o paciente deve ser encaminhado, respeitando a divisão hierárquica do estado. Já o algoritmo branch and price, utilizado para a otimização na regionalização do estado, é bastante interessante, pois tenta melhorar a referida divisão hierárquica do estado, levando em consideração o número de habitantes e o número de procedimentos médicos de cada município do estado. Os resultados obtidos têm atendido às expectativas da SESA-PR.
Palavras-chave: Problema das p-medianas. Algoritmo branch and price. Fluxo de pacientes. Configurações hierárquicas.
ABSTRACT
This paper presents a proposal for optimizing the public health service in the state of Parana in terms of the flow of patients within the state's boundaries and the regionalization (division) of the state into new hierarchical configurations for this service. In terms of regionalization, the proposal consists of dividing the state into smaller regions comprising several towns connected to a headquarter city, which would be responsible for decisions affecting the region. With regard to the flow of patients, an algorithm is proposed which organizes the information while simultaneously optimizing the flow. The state was regionalized using a branch-and-price algorithm, which uses a column generating algorithm in each node of a branch-and-bound tree. The technique proposed here to optimize the patient flow proved effective and useful, controlling not only the medical procedures performed in each town but also defining the city to which each patient should be taken, according to the hierarchical division of the state. The branch-and-price algorithm used to optimize the regionalization of the state is very interesting, for it improves the hierarchical division of the state taking into account the number of inhabitants and the number of medical procedures in each city of the state. The results have met the expectations of State Health Services.
Keywords: P-medians problem. Branch-and-price algorithm. Patient flow. Hierarchical configuration.
1 Introdução
O trabalho da logística é prover a disponibilidade de produtos e/ou serviços, e onde e quando estes forem necessários. Uma questão básica do gerenciamento logístico é como estruturar sistemas e/ou configurações de distribuição capazes de atender de forma econômica os mercados geograficamente distantes das fontes de produção, oferecendo níveis de serviço cada vez mais altos em termos de disponibilidade de estoque ou capacidade de atendimento em um intervalo de tempo cada vez menor (BALLOU, 1993).
Decisões sobre a melhor configuração para a instalação de facilidades destinadas ao atendimento da demanda de uma população são tratadas em uma ampla classe de problemas, conhecidos como problemas de localização de instalações (facilities location). O modelo clássico utilizado para a representação dos problemas desta classe é o problema das p-medianas, no qual se procura em uma rede de n pontos, escolher p pontos (medianas) como sendo as facilidades, de forma a minimizar a soma das distâncias dos (n p) pontos de demanda às p medianas.
As 399 cidades do estado do Paraná, Brasil, formam um grafo que pode ser estruturado para a definição das p-medianas, sendo as cidades os pontos do grafo e as estradas entre elas, os arcos. A regionalização da saúde é uma proposta que permite organizar as cidades em divisões hierárquicas de forma a facilitar o deslocamento dos pacientes que necessitam de atendimento fora das suas cidades de origem (BRASIL, 2004b). Neste trabalho, propõe-se a otimização do fluxo de pacientes dentro do estado de acordo com a regionalização (divisão) atual do mesmo e, também, uma nova forma para a definição das cidades sede, construindo de forma otimizada as divisões hierárquicas (nova divisão), baseando-se no modelo clássico do problema das p-medianas.
Para a solução do problema de otimização de fluxo, foi desenvolvido um algoritmo que organiza as informações contidas em diversos bancos de dados da Secretaria Estadual de Saúde (SESA) do Paraná e, com base nesta organização, otimiza o fluxo dos pacientes. Para a solução do problema é utilizado o método branch and price, que está baseado no tradicional método branch and bound (JÄRVINEN; RAJALA; SINERVO, 1972), com a aplicação do método de geração de colunas utilizando a relaxação lagrangeana/surrogate como alternativa de estabilização, em cada nó da árvore. A regionalização da saúde no estado tem como um de seus objetivos o melhoramento na otimização do fluxo de pacientes (BRASIL, 2002b).
O trabalho está organizado da seguinte forma: na seção 2 é apresentada uma descrição completa do problema, dividindo-o em duas partes: o problema do fluxo de pacientes e o problema da regionalização da saúde no estado do Paraná; é feita, também, uma revisão da literatura comentando sobre alguns trabalhos quanto à regionalização, assim como alguns trabalhos que já utilizaram o método branch and price. Na seção 3 é descrito o algoritmo desenvolvido para a otimização do fluxo de pacientes utilizando a regionalização atual e é descrito, também, o algoritmo branch and price para a obtenção de soluções viáveis para o problema das p-medianas. As técnicas implementadas e desenvolvidas para o fluxo de pacientes, assim como para a regionalização do estado, são apresentadas na seção 4, e por fim, as conclusões e as sugestões para trabalhos futuros estão na seção 5.
2 Descrição do problema
O Sistema Único de Saúde do Estado do Paraná (SUS), através da SESA, busca uma solução para o problema de fluxo de pacientes que não encontram o procedimento médico necessário em sua cidade de origem e que necessitam ser encaminhados para outra cidade do estado para atendimento. Para que ocorra um encaminhamento eficaz, deve existir um sistema organizacional que defina para onde o cidadão deve ser encaminhado. Este processo de orientação aos pacientes deve ser definido pela SESA e realizado pelas secretarias municipais de saúde (PARANÁ, 2001). Esse encaminhamento deve ser o mais rápido possível, para que a enfermidade do paciente não se agrave ou, ainda, não haja o risco de contágio, se for o caso (CAMPINA GRANDE, 2004). Além disso, deve haver a otimização dos recursos envolvidos no transporte de pacientes, tais como veículos e funcionários.
O sistema de saúde no Brasil possui três níveis de resolutividade para os procedimentos médicos ofertados pelo estado: baixa, média e alta complexidade (BRASIL, 2002a). A SESA distribui os níveis de resolutividade de procedimentos em grupos de cidades da seguinte forma: certo número de cidades forma um grupo chamado de microrregião, onde a cidade sede fica responsável pelos procedimentos de baixa complexidade; certo número de microrregiões, por sua vez, forma um grupo maior chamado de regional, no qual a cidade sede fica responsável pelos atendimentos de média complexidade; a junção de regionais forma um grupo ainda maior de cidades, chamado de macrorregião, no qual a cidade sede é responsável pelos procedimentos médicos de alta complexidade ofertados pelo estado (BRASIL, 2004a).
Diante deste contexto, o problema geral pode ser dividido em duas partes: a primeira diz respeito ao estabelecimento do fluxo de pacientes, cujo objetivo é fornecer uma solução otimizada para o paciente fazendo uso da regionalização atual do estado. Esta solução deverá fornecer à cidade (que possui o procedimento de que ele necessita e capacidade para tal) para a qual o paciente deverá ser encaminhado, de forma que o trajeto seja mínimo, garantindo que o atendimento possa ocorrer o mais rapidamente e satisfatoriamente possível. A segunda parte diz respeito à regionalização da saúde no estado, otimizando a divisão hierárquica do estado (definindo as cidades sede das microrregiões regionais e macrorregiões), fazendo com que a otimização do fluxo de pacientes, anteriormente mencionada, seja melhorada ainda mais.
2.1 O problema do fluxo de pacientes
Cada cidade do Estado do Paraná recebe uma verba provinda do SUS (Sistema Único de Saúde), destinada à saúde, de acordo com os procedimentos médicos ofertados pela cidade dentro do rol de serviços catalogados (cerca de 6.000). Existem cidades que não possuem uma quantidade mínima de procedimentos, nem mesmo os de níveis baixos de resolutividade, tornando-se totalmente dependentes da sede de sua microrregião atual. Por outro lado, existem cidades que possuem todos os procedimentos ofertados pela saúde pública, tornando-se atrativas aos usuários.
Desta forma, procura-se definir uma organização ao sistema de saúde do estado, para que nos casos onde exista a necessidade de um paciente ser atendido por outra cidade, o mesmo saiba para onde se deslocar à procura de atendimento. Atualmente, não há instrumento implantado para fazer esta definição do fluxo de pacientes. As secretarias municipais de saúde não possuem orientações específicas para onde devem encaminhar seus cidadãos e, como conseqüência, os mesmos acabam se direcionando para os grandes centros das grandes cidades por iniciativa própria.
Uma forma de análise do fluxo de pacientes é verificar os fluxos de internamento hospitalar, que pode ser feita sob dois aspectos: através da quantidade de autorizações de internamento hospitalar (AIH) e através dos valores pagos pelos atendimentos. Além destas informações obtidas juntamente à SESA, obtiveram-se através do Departamento Nacional de Infra-estrutura do Transporte (DNIT), órgão federal, as distâncias entre as cidades do estado do Paraná para que pudessem ser utilizadas no cálculo da menor distância a ser percorrida pelo paciente para ser atendido. E ainda, os dados para construção das figuras e tabelas apresentadas neste trabalho foram obtidos junto ao Instituto Paranaense de Desenvolvimento Econômico e Social (IPARDES).
2.1.1 Situação atual do fluxo de pacientes
Por ocasião da pesquisa, a definição para onde o paciente deveria se direcionar para ser atendido resumia-se, basicamente, de duas maneiras: o próprio paciente decidia procurar pelo procedimento de que necessitava em alguma cidade próxima ou em algum grande centro ou, então, a secretaria municipal de sua cidade o direcionava à capital do estado ou a outro grande centro como, por exemplo, as cidades de Londrina, Cascavel ou Maringá, ocasionando uma grande sobrecarga em seus hospitais e em seus centros de atendimento. As conseqüências desse fato são amplamente divulgadas nos meios de comunicação como, por exemplo, a superlotação, as grandes filas de espera, a falta de leitos, o uso dos corredores dos hospitais para atendimento e a insatisfação dos cidadãos que necessitam do serviço.
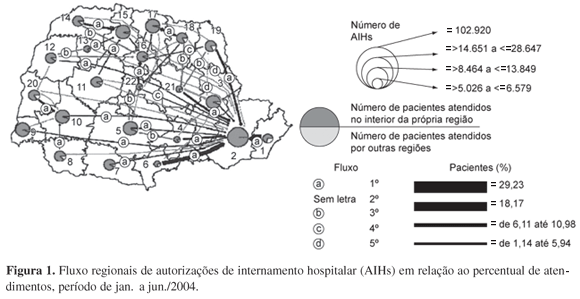
O último levantamento feito pela SESA detectou que a capital do estado está assumindo cerca de 50% dos pacientes que necessitam de atendimento fora de suas cidades de origem. A capacidade de produção das autorizações de internamento hospitalar (AIH) intra e inter-regional está relacionada com a qualidade do atendimento no setor público da saúde de cada região, considerando o número de habitantes da mesma (IPARDES, 2005). Esta capacidade e a direção dos fluxos de AIH se encontram sintetizadas e representadas na Figura 1.
Nesta Figura 1 tem-se, por exemplo, que a cidade de Curitiba (localizada no maior círculo, à direita do mapa) teve cerca de 103.000 AIHs no período de janeiro a junho de 2004, o que significa um número altamente elevado considerando o número de habitantes de Curitiba (cerca de 1,8 milhões de pessoas). Pode-se notar que da região de Paranaguá, círculo mais à direita no mapa, quase 30% dos pacientes que necessitam de internação foram para a capital (Curitiba), caracterizando uma das maiores vias do fluxo de pacientes inter-regional.
Na Figura 2, a seguir, esses mesmos fluxos estão representados em termos de valor das AIHs realizadas. Também está representada a proporção em termos de quantidade e de valor que cada região é capaz de resolver por si própria e a proporção que é encaminhada para ser atendida por outras regiões. Dadas as distintas capacidades produtivas e os montantes de valores gerados em cada região, as trocas inter-regionais apresentam significativas diferenças, que estão hierarquizadas na seqüência de fluxos.
Nesta Figura 2 tem-se, por exemplo, que os valores recebidos pela cidade de Curitiba para AIH foram de cerca de 87 milhões de reais em um período de seis meses (janeiro a junho de 2004) e que a região de Paranaguá (círculo mais à direita no mapa) repassava quase 62% de sua verba destinada à internação hospitalar para a capital paranaense, evidenciando que os atendimentos mais caros da população desta região (de Paranaguá) eram realizados em Curitiba. Cabe destacar que para a elaboração dos mapas foram desconsiderados os fluxos cuja quantidade e/ou valor eram inferiores a 1% do total da regional.
Observando os dados obtidos junto a SESA, pode-se concluir que os quatro maiores pólos (cidades de Curitiba, Londrina, Maringá e Cascavel) repartiam entre si 60% dos municípios paranaenses (238 municípios). A diferença entre eles estava na atuação de Curitiba, que extrapolava profundamente os limites de seu entorno, promovendo assistência hospitalar aos pontos mais esparsos do território estadual. A Figura 3 (auto-explicativa), a seguir, mostra a atuação desses quatro grandes centros no atendimento hospitalar.
2.1.2 Situação atual da regionalização (divisão do estado)
O grande problema encontrado para a regionalização da saúde é como dividir o estado em regiões de forma que realmente venham a garantir o acesso à saúde da população e, também, sobre os critérios a serem utilizados para se definir tais subdivisões, de forma a melhorar ainda mais o fluxo dos pacientes.
A Figura 4 (mapa da esquerda), a seguir, mostra as divisões por cores das atuais seis macrorregiões, sendo que as cidades sede estão em destaque em cada macrorregião. Já o mapa da direita da Figura 4 mostra as atuais 22 divisões regionais, sendo que os grupos de regionais com a mesma tonalidade de cor formam as macrorregiões.
Através da Figura 4 pode-se notar que a divisão hierárquica não está otimizada geograficamente, principalmente na 5ª e na 22ª regionais, sendo que a 22ª possui dois municípios isolados da 5ª regional. Outro caso que pode ser notado é o da 6ª regional, em que as cidades mais a oeste desta regional estão muito mais próximas de Pato Branco do que de Curitiba, sua sede de macrorregião. Esta situação agrava-se ainda mais na divisão das microrregiões, pois algumas cidades pertencem a mais de uma microrregião.
Para encontrar as divisões hierárquicas de forma otimizada utiliza-se, neste trabalho, o método branch and price aplicado ao problema das p-medianas, conforme já mencionado. Deste modo, podem-se definir novas cidades sede e novos agrupamentos de cidades para formação de microrregiões, regionais e macrorregiões da saúde. É claro que, utilizando apenas as distâncias entre as cidades podem-se encontrar situações que impossibilitariam a implementação; como, por exemplo, escolher para cidade sede de uma microrregião uma cidade que não possui os atendimentos básicos, mas que está em uma posição geograficamente estratégica. Para evitar este tipo de problema, foram utilizados " pesos" para as cidades como, por exemplo, o próprio número de habitantes das cidades (vale salientar que este é o critério utilizado pelo Ministério da Saúde para o cálculo do número de médicos, de hospitais e da estrutura geral da saúde), ou o número de procedimentos médicos realizados pelas cidades (o que necessitaria de informações mais seguras para demonstrar a realidade), ou ainda, " outros pesos" como, por exemplo, o número de postos de saúde, ou ainda, a capacidade de atendimento total das cidades.
Vale salientar que, as cidades sede são, dentro de uma divisão hierárquica, as cidades que possibilitam o atendimento condizente com sua responsabilidade, ou seja, as cidades sede de microrregiões são responsáveis pelos atendimentos de baixa complexidade, já as cidades sede de regionais pelos atendimentos de média complexidade e as cidades sede de macrorregião são as referências estaduais para os atendimentos de alta complexidade, conforme já comentado. O algoritmo utilizado está detalhadamente descrito na seção 3 deste trabalho.
2.2 Trabalhos correlatos
O estudo do fluxo de pacientes ganha uma importância relevante no contexto da regionalização sob o aspecto logístico, principalmente devido ao controle dos atendimentos que podem ser realizados em cidades diferentes da cidade de origem de um paciente. Não foram encontrados trabalhos que definissem um método para estabelecer o fluxo otimizado de pacientes. No algoritmo desenvolvido neste trabalho verificou-se a importância de se obter uma divisão hierárquica bem definida e otimizada e, com isso, viu-se a necessidade de encontrar as cidades sede das divisões de modo a facilitar o acesso do paciente, minimizando sua distância percorrida.
O problema das p-medianas pode ser utilizado como uma das maneiras de encontrar as cidades que possibilitarão uma otimização na construção das divisões hierárquicas. Para encontrar a solução do problema das p-medianas pode-se empregar algoritmos que podem ser divididos em quatro grupos: algoritmos primais, algoritmos duais, métodos heurísticos e meta heurísticos. Dentre os primeiros algoritmos primais desenvolvidos estão os trabalhos que apresentam algoritmos baseados no método branch and bound para obter soluções ótimas (JÄRVINEN et al., 1972), inclusive com estudos mais atuais sobre a convergência do método branch and bound em algumas aplicações, e também abordagens baseadas em programação linear (SWAIN, 1974).
A maioria dos métodos duais baseia-se no uso de técnicas da relaxação lagrangeana, sendo que o método de otimização de subgradientes é aplicado para resolver a relaxação lagrangeana/surrogate (SENNE; LORENA, 2000). A restrição surrogate, estudada por Glover (1968), foi inserida na relaxação para que se obtivessem melhores limitadores nas soluções duais, garantindo, assim, uma maior precisão para encontrar a solução do problema. A partir dessa junção de relaxações, vários estudos de casos foram publicados mostrando que o método de geração de colunas, utilizando a relaxação lagrangeana/surrogate, ganha em eficiência para encontrar a solução ótima (LORENA et al., 2003).
Os métodos heurísticos são aplicados freqüentemente para encontrar soluções em problemas considerados grandes, os quais possuem um número elevado de pontos num grafo, sendo que o mesmo acontece com os meta heurísticos; assim, a comparação entre os resultados obtidos através dessas duas formas de solucionar o problema é inevitável. Neste trabalho foi escolhido o método branch and price, dentre os métodos para encontrar as medianas e, conseqüentemente, os agrupamentos de pontos (clusters) associados a cada mediana. Este método proporciona uma solução bastante satisfatória e, muitas vezes, a solução ótima, e é apresentado na seção 3 a seguir.
3 Técnicas utilizadas para a resolução do problema
3.1 Algoritmo desenvolvido para o fluxo de paciente
Como o número de procedimentos para o controle é muito grande (cerca de 600.000) e os relacionamentos entre os mesmos são muitos, ao se apresentar os dados de entrada ao algoritmo com a cidade de origem e o procedimento requerido, faz-se um filtro nos mesmos para que se trabalhe apenas com os registros necessários à designação do paciente. Assim, armazenam-se as cidades que possuem o procedimento requerido e os dados das referidas cidades quanto à localização (a qual microrregião, regional e macrorregião a mesma pertence), para que a busca seja otimizada, minimizando-se o número de registros. É necessário obedecer à hierarquia para procurar o procedimento requerido, portanto, primeiramente verifica-se se a cidade de origem possui o procedimento. Se a resposta for afirmativa, observa-se se a sua capacidade de atendimento ainda possui disponibilidade no período (semana, mês ou outro, conforme definido pela SESA) e, se a resposta for novamente afirmativa, deve-se encaminhar o paciente para a sua própria cidade e local pré-definido pela SESA, com a autorização documentada em mãos, para a realização do procedimento.
Se ocorrer da cidade de origem não possuir o procedimento e/ou não houver capacidade para atender o paciente dentro do período e/ou, ainda, for um atendimento de emergência, é necessária a verificação de disponibilidade de atendimento/capacidade nas cidades pertencentes à mesma microrregião da cidade de origem do paciente, identificando, dentre elas, a cidade mais próxima da cidade de origem (local onde o paciente se encontra), colocando-a como 1ª opção; a segunda mais próxima como 2ª opção, e assim sucessivamente. Caso a microrregião não possua o atendimento/capacidade necessários, relacionam-se as cidades pertencentes à mesma regional da cidade de origem. Caso ocorra a negativa novamente, procura-se dentre as cidades da macrorregião e, se necessário, finalmente, para as cidades que não tenham vínculo com a cidade de origem, mas que tenham o procedimento, visando encontrar uma cidade que atenda às necessidades do atendimento solicitado.
Verificando a capacidade de atendimento da 1ª opção e ocorrendo a autorização (por haver capacidade), encaminha-se o paciente para esta cidade; se não houver capacidade, analisa-se a 2ª opção e assim por diante, até encontrar uma cidade que possa atender ao paciente e que o encaminhamento possa ser autorizado. A cada resposta negativa das cidades pesquisadas como possíveis opções, faz-se a inserção das mesmas em um relatório, com o nome da pessoa responsável pela não autorização, para que se possa, deste modo, conhecer as limitações dos procedimentos e das capacidades de cada cidade. Este procedimento possibilitará a emissão de relatório mensal que as cidades podem enviar à SESA para a devida checagem de dados e identificação de discordância dos mesmos.
O procedimento sugerido anteriormente faz com que seja obrigatória a procura de atendimento nas cidades mais próximas da cidade de origem do paciente, respeitando a uma hierarquia existente entre as cidades. As distâncias calculadas entre todas as cidades (399 x 399) são baseadas no algoritmo de Floyd (CHRISTOFIDES, 1975) que determina a menor distância entre quaisquer dois pontos (no caso, duas cidades) de um grafo G(N, A), em que N é o conjunto das 399 cidades e A é o conjunto de arcos que as une. O algoritmo para a otimização do fluxo dos pacientes do SUS, ou seja, para a designação otimizada dos mesmos às cidades, conforme descrito anteriormente, consta das seguintes etapas (SCARPIN; STEINER; DIAS, 2006):
a) dados de entrada: dados do paciente, cidade de origem e procedimento requerido;
b) faz-se a filtragem das cidades que possuem o procedimento requerido e de seus dados;
c) se a cidade de origem consta do filtro, deve-se colocá-la como 1ª opção;
d) caso a cidade de origem não conste do filtro, faz-se a verificação das cidades do filtro que pertençam a sua microrregião e que possuem o procedimento requerido. Colocam-se as mesmas em uma lista, em ordem crescente de distância (matriz de Floyd) e, por conseguinte, de opção;
e) nas cidades do filtro que pertencem a sua regional e a sua macrorregião, faz-se a mesma pesquisa em relação às distâncias e prossegue-se com a relação de opções;
f) caso a lista continue vazia, procedem-se analogamente nas demais cidades do filtro;
g) em cada uma das checagens anteriores com relação às opções, verifica-se a capacidade de atendimento:
h) se possuir atendimento, deve-se autorizar e encaminhar o paciente;
i) se não possuir atendimento, deve-se inserir a cidade no relatório final e prosseguir com a lista de opções; e
j) se não houver opção alguma (lista vazia), ou seja, nenhuma cidade pode atender o paciente, então, deve-se encaminhar o paciente para o próximo período, ou encaminhá-lo para o órgão estadual competente para prosseguir o atendimento.
3.2 Algoritmo branch and price para a divisão do estado
O método branch and price está baseado no método branch and bound para obtenção de soluções viáveis para o problema das p-medianas, no qual cada nó da árvore de busca utiliza o método de geração de colunas aplicado ao modelo matemático do problema de particionamento de conjuntos. No algoritmo, os problemas resultantes da aplicação das regras de ramificação são armazenados em uma lista. Essa lista pode ser explorada de diversas maneiras:
a) em largura, isto é, como uma fila simples também conhecida como FIFO (first in first out), ou seja, o primeiro que entra é o primeiro que sai, visando obter melhores limitantes e soluções viáveis;
b) em profundidade, como uma " pilha" , que é conhecido como LIFO (last in first out), que permite obter soluções viáveis mais rapidamente; e
c) podem-se determinar filas de prioridades, buscando explorar os nós mais promissores para a obtenção de uma solução ótima.
O método branch and price, neste trabalho, utiliza a relaxação lagrangeana/surrogate como alternativa à relaxação lagrangeana tradicional aplicada em algoritmos de otimização de subgradientes.
Para um dado vetor de multiplicadores λ Є Rn, substitui-se as n restrições da formulação do problema das p-medianas tradicional, que determinam para qual mediana cada ponto será destinado, por uma única restrição, denominada restrição surrogate. O vetor λi, ∀λi ЄN, usado neste trabalho é a solução dual relacionada ao conjunto destas restrições mencionadas acima de cada problema mestre restrito e a cada iteração do algoritmo gerador de colunas, esse vetor é atualizado. A formulação resultante correspondente à relaxação surrogate para o PPM (problema das p-medianas) é dada pela Equação 1:
SlPPM

s.a.

O valor ótimo v(SλPPM) é menor ou igual a v(PPM), e resulta da resolução do problema dual surrogate Max{v(SλPPM)}. O problema SλPPM é um problema linear inteiro sem qualquer característica que possa ser explorada. A obtenção da solução dual da função surrogate s: Rn→ R,(λ,v(SλPPM)) é considerada difícil devido a algumas propriedades, como: a não negatividade dos multiplicadores surrogate, os valores xij são soluções ótimas para o problema surrogate e viável para o problema original. Devido a tais dificuldades é relaxado novamente o problema no sentido lagrangeano. Sendo t Є R o multiplicador dual associado à restrição relacionada ao número de medianas (similar a restrição (a), porém da formulação tradicional do problema das p-medianas), pode-se obter a relaxação lagrangeana/surrogate de PPM (Equação 2).
L t S λ PPM

s.a. (b), (c) e (d).
Para t e λ dados (t é encontrado através de um cálculo que posteriormente será apresentado) tem-se que v(LtSλPPM) < v(SλPPM) < v(PPM). No caso em que o valor de t = 1, tem-se a relaxação lagrangeana tradicional no vetor de multiplicadores λi . Narciso (1998) demonstra que, para t* obtido como solução ótima do dual local do problema LtSλPPM, o valor v(LtSλPPM) fornece um melhor limitante que o obtido pela relaxação lagrangeana tradicional.
Para λ Є Rn dado, o melhor valor de t é obtido como solução ótima do dual do problema LtSλPPM, definido como na Equação 3.
Dt,λ
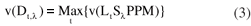
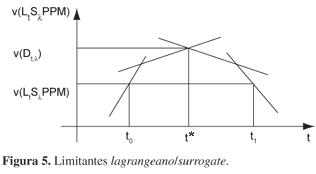
ou, por busca dicotômica, dado que a função lagrangeana l: R → R, (t, v(LtSλPPM)) é côncava e linear por partes (PARKER; HARDIN, 1988), conforme ilustrada na Figura 5.
O algoritmo de busca do multiplicador lagrangeano/surrogate, apresentado a seguir, foi baseado no algoritmo aplicado por Pereira (2005) para obtenção de valores aproximados para o melhor valor de t.
Algoritmo BM (busca do multiplicador lagrangeano/surrogate)
Defina o valor inicial t0 e o tamanho do passo s;
Faça t ← t0, a ← indefinido; b ← indefinido;
Enquanto (a = indefinido ou b = indefinido) repita:
Resolva LtSλPPM e defina xλ calculando βj =  min {0, dij tλ} ∀λj Є N, em que J é o conjunto dos índices jЄN que correspondem aos p menores valores de βj e definindo:
min {0, dij tλ} ∀λj Є N, em que J é o conjunto dos índices jЄN que correspondem aos p menores valores de βj e definindo:

Faça slopeλ → 
Se slopeλ > 0, faça a → t e t → t + s;
Senão, faça b → t e t → t s;
Encontre o melhor valor de t Є[a, b] pelo método da bisseção.
Testes realizados por Pereira (2005) comprovam que a obtenção de bons limitantes para o problema das p-medianas tradicional não dependem do cálculo exato de t*, sendo suficiente encontrar um valor t Є[a, b]. O método da bisseção é utilizado neste momento. Notar que o vetor λi não muda no decorrer do algoritmo, mudando apenas o valor de t a cada iteração (os parâmetros usados neste trabalho são: t0 = 0,0; s = 0,5) (SENNE; LORENA, 2003).
3.2.1 O Método gerador de colunas
Ao reescrever a formulação do problema das p-medianas para a formulação do problema de particionamento de conjuntos, procura-se fazer a combinação de todas as possíveis soluções viáveis para o problema. Ao se escolher p subconjuntos de S = {S1, S2,..., Sm} que representem uma solução viável para o problema, pode-se, dentre várias dessas combinações, encontrar a solução de menor custo que será a solução ótima desejada. As técnicas utilizadas no desenvolvimento do algoritmo são baseadas em Pereira (2005).
A ordem de grandeza do conjunto S pode ser muito grande. Para um problema com n vértices, o conjunto S relativo terá a grandeza da ordem de 2n elementos e a enumeração de todos os subconjuntos SkЄS, quando o valor de n vai aumentando, torna-se uma tarefa exponencialmente mais difícil. Como cada subconjunto Sk representa uma coluna das restrições da formulação para o problema de particionamento de conjuntos, então se escritas as restrições com todos os subconjuntos Sk, o número de variáveis seria enorme, pois cada coluna está relacionada a uma variável, e a dificuldade computacional seria um desafio extremamente árduo.
Quando é utilizada a técnica de geração de colunas, pode-se manipular o conjunto de colunas usadas de acordo com as informações das variáveis duais de um problema mestre. Um conjunto bastante reduzido de colunas é utilizado inicialmente. Novas colunas são calculadas como soluções de subproblemas e somente as novas colunas que contribuírem para a melhoria da solução principal serão utilizadas. Quando não houver mais colunas com custo reduzido negativo (positivo) a serem incluídas na matriz de restrições, o processo é encerrado.
3.2.1.1 O problema mestre restrito
Partindo-se de um conjunto inicial de colunas, novas colunas são inseridas em um problema mestre, a cada iteração. Um problema mestre restrito (PMR) para resolver o problema das p-medianas pode ser definido, considerando-se um subconjunto K ⊂ M = {1, 2,..., m} dos índices das colunas da formulação completa do Problema de Particionamento de Conjuntos (MINOUX, 1987), que considera todas as combinações possíveis para a formação de conjuntos de pontos, com a seguinte formulação (Equação 4).
s.a.


Observa-se que as variáveis xk podem assumir valores fracionários, entre zero e 1 e, por esse motivo, a solução de  pode não ser viável para o PPC. A aplicação de métodos tipo branch and bound, pode produzir soluções viáveis para o PPC, mas o conjunto final de colunas do
pode não ser viável para o PPC. A aplicação de métodos tipo branch and bound, pode produzir soluções viáveis para o PPC, mas o conjunto final de colunas do  pode não ser suficiente para a obtenção da solução ótima. As restrições duais ótimas λ Є
pode não ser suficiente para a obtenção da solução ótima. As restrições duais ótimas λ Є  e µ Є R, associadas às restrições (e) e (f), respectivamente, serão utilizadas para o cálculo de novas colunas.
e µ Є R, associadas às restrições (e) e (f), respectivamente, serão utilizadas para o cálculo de novas colunas.
3.2.1.2 O conjunto inicial de colunas
A importância de um conjunto inicial de colunas é muito grande quanto ao sucesso ou fracasso na resolução do PMR. Uma rotina desenvolvida por Pereira (2005) sugere a construção desse conjunto da seguinte maneira:
a) defina MaxC como o número referência de colunas a serem geradas;
b) faça NumC → 0;
c) repita;
d) seja P = {n1,...,np} contido em N um conjunto de vértices escolhido aleatoriamente;
e) para j = 1,..., p faça (p é o número de colunas a serem geradas (clusters)):
- Sj ← {nj} ∪ {q Є N P |  =
=  {dqt}
{dqt}
- cj ←
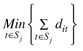
- Para i = 1,..., n faça
- Se i Є Sj, faça aij← 1;
- Se i ∉ Sj, faça aij← 0;
- Adicione a coluna Aj ao conjunto inicial de colunas;
f) NumC ← NumC + p;
g) enquanto (NumC < MaxC); e
h) fim
Uma base viável para o problema linear inicial deve estar contida nesse conjunto de colunas inicial. Um novo conjunto de p colunas é adicionado a cada iteração.
3.2.1.3 O subproblema gerador de colunas
A junção do processo de geração de colunas com a relaxação lagrangeana/surrogate é feita na resolução do subproblema gerador de colunas ao utilizar os multiplicadores duais ótimos λi, ∀λi Є N, do problema , para resolver o problema Dt,λ e obter soluções aproximadas para o multiplicador lagrangeano/surrogate t.
A mediana escolhida como centro do cluster de menor contribuição ao valor de v(Dt,λ) corresponde ao vértice j* obtido como solução ótima do subproblema:
SGCt

Considerando cada vértice j Є N como mediana e fixando aij, ∀λi Є N, o problema SGCt é resolvido, por inspeção, da seguinte maneira:

Sendo j* o índice que resultar no menor valor para v(SGCt), define-se um novo subconjunto Sj* como:
Sj* = { i Є N | aij* = 1}
e a coluna Aj* será incluída em se obedecer a Equação 7:
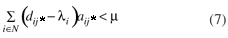
Para acelerar o processo de resolução utiliza-se, neste momento, a estratégia de multi pricing, ou seja, todas as colunas que satisfizerem a Equação (7) serão adicionadas ao PMR.
3.2.1.4 O algoritmo de geração de colunas
As variáveis duais ótimas do PMR são utilizadas para calcular novas colunas, solução de um subproblema, a cada iteração. Essas variáveis também são utilizadas para calcular limitantes inferiores, obtidos como o valor da solução ótima do problema LtSλPPM. Para a atualização dos limitantes superiores é utilizado o valor ótimo da função objetivo do PMR, v(). O processo é finalizado se os limitantes atingirem uma precisão desejada. No caso em que esses limites não atinjam tal precisão, então se as novas colunas obtidas apresentarem custos reduzidos adequados (que satisfaçam a condição imposta), elas serão adicionadas ao PMR a ser resolvido na próxima iteração. Se nenhuma coluna for adicionada também se finaliza o processo.
3.2.1.5 A retirada de colunas
Para se obter um gerenciamento do tamanho do problema deve-se levar em consideração que à medida que ocorre a inclusão de novas colunas à formulação do PMR, este também será aumentado. Deste modo, podem-se exigir mais recursos computacionais que os disponíveis para sua solução. Assim, uma rotina para retirada de colunas, que não contribuem significativamente para uma melhoria na solução, pode ser utilizada.
A remoção dessas colunas ocorre quando o problema apresentar um número de colunas maior que um valor estabelecido anteriormente e/ou sempre que se desejar eliminar da formulação as colunas com custo reduzido elevado, quando comparadas com um valor médio de referência. Deve-se levar em conta que a utilização desse procedimento também pode ser prejudicial para o processo de resolução do problema, pois ao remover colunas podem-se retirar informações relevantes da formulação prejudicando a solução final.
Um parâmetro fator_rc permite controlar a intensidade do teste aplicado para a remoção de colunas, limitando o número de colunas consideradas úteis para o problema. A rotina utilizada é a seguinte:
a) defina TotC como o número total de colunas de
b) defina fator_rc como um número positivo;
c) defina cr_médio como o custo reduzido médio das colunas do conjunto inicial;
d) obtenha crj, j = 1,..., TotC, o custo reduzido de cada coluna j de
e) para j = 1,..., TotC faça:
f) se crj > fator_rc * cr_médio, remova a coluna j de
g) fim
3.2.1.6 O algoritmo branch and price
Em cada nó de uma árvore de busca branch and bound utiliza-se a técnica de geração de colunas para a obtenção de novas variáveis não básicas para um PMR e essa é a essência do método branch and price. Na formulação do PMR tem-se que as variáveis podem assumir valores fracionários e, deste modo, podem não fornecer uma solução para os problemas de p-medianas. Desta forma, ao obter-se uma solução não inteira utiliza-se a técnica de ramificação, baseada no branch and bound, que diferencia os coeficientes de linha (q,r) que são do mesmo cluster (pertencentes a uma mesma mediana) ou não. O ponto q é escolhido, dentre as colunas cujo valor da variável correspondente na função objetivo é fracionário na iteração, como sendo o que mais aparece nessas colunas do problema mestre restrito atual. O ponto r é escolhido como sendo o ponto que, dentre as mesmas colunas mencionadas, seja o ponto que menos aparece nestas colunas. Para a identificação do par de vértices (q,r) observa-se somente as colunas que possuírem valores fracionários na linha da função objetivo. Para que a árvore de busca não seja explorada em nós não promissores impõem-se condições de poda para tais nós e, assim, economiza-se esforço computacional significativo. Uma vez determinados os índices de linha (q,r), são acrescentadas restrições ao problema para que se possa encontrar uma solução final inteira.
3.2.1.7 Condições de poda
As soluções do PMRs resolvidos em cada nó da árvore podem ser viáveis ou não. As condições de poda implementadas neste trabalho são baseadas na exploração de nós promissores, podando os nós não promissores. Caso se tenha uma solução viável em um nó, chamado de bound, armazenam-se os resultados de , valores primais e v(), e os nós a serem explorados serão comparados agora com o nó considerado bound de melhor valor de v(). No caso em que é encontrada uma solução não viável, deve-se ramificar este nó da maneira descrita no item " h" a seguir, e o v() obtido nestes nós ramificados deverá ser comparado ao melhor bound. Caso o valor do nó ramificado seja pior do que o melhor bound, em um nível igual ou inferior ao nó ramificado, então este nó será descartado e não haverá ramificação a partir dele. Repete-se este procedimento até não haver mais possibilidade de ramificação devido às podas realizadas, e a solução ótima será o melhor bound.
3.2.1.8 Regras de ramificação
Na ramificação da árvore, dois novos PMR's são criados e acrescidos na lista de modelos do algoritmo. O processo, chamado bifurcação, tem o efeito de contrair a região viável de um modo que elimina de considerações posteriores a solução corrente não inteira para o par de vértices (q, r), preservando ainda todas as possíveis soluções inteiras do problema original. Neste trabalho, considera-se que os ramos à esquerda, modelos P com índice par, correspondem aos problemas nos quais os coeficientes das linhas q e r de uma dada coluna com valor fracionário na solução final do PMR são idênticos, e que nos ramos à direita, modelos P com índice ímpar, apenas um dos coeficientes pode assumir o valor 1. Esta regra permite identificar os pares de vértices que pertencem ao mesmo cluster na solução ótima de . O fluxograma do algoritmo é apresentado na Figura 6.
4 Implementação e resultados
4.1 Para o fluxo de pacientes
Nesta seção são apresentadas as implementações e os resultados obtidos para os dois problemas descritos anteriormente: o fluxo ótimo de pacientes utilizando a divisão atual do estado e a otimização na divisão do estado.
A técnica desenvolvida para a definição do fluxo de pacientes que percorrem o estado à procura de atendimento médico foi implementada em linguagem Delphi, em um computador Pentium 4, 1GB de RAM, utilizando o banco de dados MySQL.
Podem-se comparar os resultados obtidos através da técnica desenvolvida e a técnica vigente na SESA. A técnica desenvolvida neste trabalho apresenta várias vantagens em relação à adotada atualmente pela SESA: traz mais opções de atendimento ao paciente; a distância a ser percorrida pelo paciente até ser atendido é consideravelmente menor; descongestionamento dos grandes centros. Apresenta-se, a seguir, um exemplo ilustrativo.
" Seja um paciente da cidade de Guapirama (Microrregião 72 Santo Antônio da Platina, 19ª regional - Jacarezinho e macrorregião Norte Londrina) à procura do procedimento Apendicectomia, código 33005060" . Este paciente tem como opção através da técnica da SESA, ir para a cidade Jacarezinho, cidade sede da 19ª regional, já que a cidade sede da microrregião Santo Antônio da Platina não possui tal procedimento, percorrendo a distância de 47 km, considerando somente a distância de ida de Guapirama a Jacarezinho. Se não conseguir atendimento em Jacarezinho, então o paciente deve procurá-lo na cidade de Londrina, cidade sede da macrorregião Norte, percorrendo 132 km. Se ainda assim, não conseguir atendimento, então, como última opção, o paciente deve ir à cidade de Curitiba (referência estadual para qualquer atendimento) percorrendo 274 km.
Na técnica desenvolvida neste trabalho, o paciente tem 137 cidades como opções de atendimento, em ordem hierárquica atual e distância, são elas:
a) Microrregião 72 Santo Antônio da Platina
- Joaquim Távora, percorrendo 18 km, pertencente a microrregião 72.
b) 19ª Regional - Jacarezinho
- Carlópolis, percorrendo 42 km, pertencente a 19ª regional;
- Ibaiti, percorrendo 44 km, pertencente a 19ª regional;
- Jacarezinho, percorrendo 47 km, pertencente a 19ª regional;
- Pinhalão, percorrendo 62 km, pertencente a 19ª regional;
- Tomazina, percorrendo 62 km, pertencente a 19ª regional;
- Cambará, percorrendo 64 km, pertencente a 19ª regional;
- Ribeirão Claro, percorrendo 65 km, pertencente a 19ª regional;
- Salto do Itararé, percorrendo 67 km, pertencente a 19ª regional;
- Figueira, percorrendo 68 km, pertencente a 19ª regional; e
- Wenceslau Braz, percorrendo 72 km, pertencente a 19ª regional.
c) Macrorregião Norte Londrina (MRNL)
- Congonhinhas, percorrendo 55 km, pertencente a MRNL, 18ª regional;
- Andirá, percorrendo 60 km, pertencente a MRNL, 18ª regional;
- Bandeirantes, percorrendo 67 km, pertencente a MRNL, 18º regional;
- Santa Mariana, percorrendo 76 km, pertencente a MRNL, 18ª regional;
- Cornélio Procópio, percorrendo 81 km, pertencente a MRNL, 18ª regional;
- Assaí, percorrendo 95 km, pertencente a MRNL, 18ª regional; e
- Mais 120 cidades pelo resto do Estado, ordenadas pela hierarquia e distância.
Vê-se que as opções de atendimento através da técnica desenvolvida trazem uma melhor distribuição de pacientes que percorrem o estado à procura de atendimento médico. A maneira de confirmar o atendimento dos pacientes em cada cidade, seguindo a seqüência, seria via telefone, já que o estado não possui uma rede computacional integrada entre as secretarias municipais da saúde. No entanto, no momento em que essa rede for implementada pelo governo estadual, essa técnica poderá ficar ainda mais útil, tendo em vista que, disponibilizando este serviço on-line, os pacientes poderão procurar a melhor opção para seu atendimento com a devida confirmação de sua consulta feita via e-mail ou, até mesmo, automaticamente via internet.
4.2 Para a divisão do estado
Já o algoritmo branch and price foi implementado em linguagem Progress Full, a qual utiliza através de linha de código o software LINGO 8 (Language for Interactive General Optimizer) para a solução dos modelos matemáticos gerados no programa. Para os testes realizados foi utilizado um computador Pentium 4 (2,8 GHz de processador e 512 Mb de RAM). Foram destacados cinco testes para encontrar a melhor divisão hierárquica entre as cidades definindo as macrorregiões regionais e microrregiões mantendo o mesmo número atual de divisões (6, 22 e 83, respectivamente). Após estes testes realizados, três propostas de divisão hierárquica são apresentadas utilizando diferentes números de cidades sede das divisões. Nas duas últimas propostas são alterados os critérios para a escolha das cidades candidatas à sede de divisão (explicadas posteriormente).
No primeiro teste realizado, fixaram-se as 22 cidades (medianas) consideradas sedes de regionais e se definiram os clusters através da distância mais próxima de cada cidade a uma mediana. Foram utilizadas as distâncias reais entre as cidades para a utilização do algoritmo, o qual foi aplicado para encontrar as seis (dentre as 22 fixadas) cidades sede de macrorregiões. Além disso, em cada uma das 22 regionais definiu-se 83 microrregiões, respeitando a proporcionalidade de cidades de cada microrregião atual.
No segundo teste fixaram-se as 83 cidades sede de microrregiões, designando cada grupo de cidades através da menor distância. Dentre estas 83 cidades, determinaram-se através do algoritmo as 22 medianas consideradas sedes de regional. As cidades não medianas são designadas a uma regional de acordo com a formação do cluster de sua cidade sede. Da mesma forma, dentre estas 22 cidades, definiram-se as seis sedes de macrorregiões. No terceiro teste são fixadas previamente as cidades sede das macrorregiões (atuais sedes de macrorregião: Cascavel, Curitiba, Londrina, Maringá, Pato Branco e Ponta Grossa), devido à estrutura encontrada nessas cidades. Com isso, pretende-se apresentar um teste mais próximo do viável, definindo as cidades sede das regionais e microrregiões utilizando as distâncias reais.
No quarto e quinto teste utilizou-se a mesma configuração de macrorregião do teste anterior (3º teste), porém para definir as cidades sede de regionais e de microrregiões foram utilizadas as distâncias reais ponderadas pelo número de habitantes e pelo número de procedimentos ofertados por cada cidade, respectivamente.
Na primeira proposta, alterou-se a configuração atual apenas em relação ao número de sedes de macrorregião, aumentando para sete cidades, incluindo a cidade de Paranavaí. Os critérios utilizados para escolher a cidade de Paranavaí foram: sua localização privilegiada na região Noroeste do estado (região mais carente de atendimento) e a sua capacidade de atendimento ser equivalente às cidades sede já definidas. Após a construção das macrorregiões, foram determinadas as 22 regionais, respeitando a proporcionalidade de cidades em cada macrorregião e, por fim, as 83 microrregiões também considerando a proporção vigente.
A segunda e a terceira propostas são apresentadas a seguir, ambas com apenas cinco macrorregiões, sendo as cidades sede: Cascavel, Curitiba, Guarapuava, Londrina e Maringá. Os critérios usados para escolher a cidade de Guarapuava como sendo sede de macrorregião (ao invés de Pato Branco ou de Ponta Grossa) são: melhor localização geográfica (região central do estado) e a equivalência de capacidade de atendimento em relação às cidades retiradas (Pato Branco e Ponta Grossa).
Na segunda proposta escolhe-se apenas 18 cidades sede de regionais dentre as 40 principais cidades do estado. Essas 40 principais cidades do estado foram escolhidas pelo critério de capacidade de atendimento médico. O número de 18 cidades foi determinado pelo seguinte fato: das 40 cidades escolhidas, cinco eram as sedes das macrorregiões, sobrando 35 cidades; a metade dessas, arredondando para cima, foi o número escolhido para a quantidade de sedes de regionais. Depois de determinadas as regionais através do algoritmo, determinou-se as 43 cidades sede de microrregião, sendo esse número escolhido entre as 100 principais cidades do estado.
Finalmente, na terceira proposta, aumentaram-se para 22 as sedes de regionais, escolhidas agora entre as 50 cidades mais capacitadas para atendimento, já retiradas as cinco sedes de macrorregião. As 43 sedes de microrregião foram determinadas da mesma forma da primeira proposta. Nesta proposta, porém, não se impõe a necessidade das cidades pertencentes a uma microrregião estarem na mesma regional, bem como as cidades de uma regional não necessitarem estar na mesma macrorregião. Desta forma, o algoritmo determina as divisões hierárquicas sem nenhum tipo de restrição, ou seja, são escolhidas sempre as cidades sede de divisão entre todas as cidades candidatas, independente da divisão superior e, ainda, se uma cidade é sede de uma divisão não poderá mais ser candidata à sede de uma divisão inferior. Assim, cada cidade do estado terá sempre diferentes opções para seus cidadãos procurarem atendimento médico no caso em que o atendimento só possa ser feito pela própria cidade ou pela cidade sede de sua divisão, como hoje se discute na secretaria estadual de saúde. Assim garantem-se, nessa proposta discutida pela SESA-PR, mais opções para os cidadãos das cidades menos estruturadas.
4.2.1 Resultados dos testes e propostas
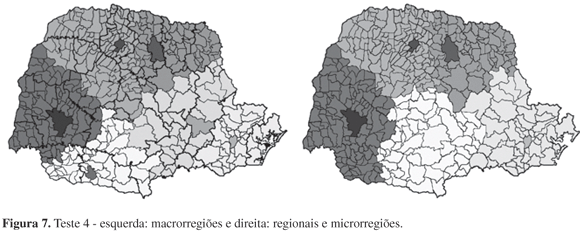
As Figuras 7 e 8, mostram os melhores resultados obtidos, combinando os resultados numéricos e avaliando a escolha das cidades sede, considerando sua estrutura na área da saúde. O melhor teste considerado foi o teste 4 (Figura 7), e a proposta 3 (Figura 8) foi considerada a que possui os melhores resultados combinados.
Nesta Figura 7 tem-se que o mapa da esquerda apresenta a divisão das macrorregiões por cores, com as cidades sede na cor destacada dentro de sua respectiva macrorregião. O mapa da direita mostra as divisões das regionais por cor e das microrregiões por reforço das fronteiras. As cidades sede das regionais estão sinalizadas com um ponto branco e as cidades sede das microrregiões com um ponto preto. Da mesma forma, tem-se a interpretação para a Figura 8 a seguir, em que as cidades em branco são as cidades sede de divisão e, desta forma, são excluídas das cidades candidatas a serem sedes das divisões inferiores.
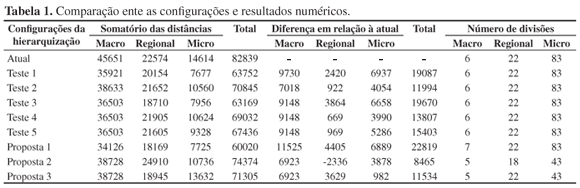
Na Tabela 1, são apresentados, para cada um dos testes, os somatórios das distâncias (em quilômetros) das cidades de cada subdivisão para a cidade sede de cada macrorregião, regional e microrregião. É feita, ainda, uma comparação da configuração atual com os resultados obtidos nos testes e nas propostas.
Nesta Tabela 1, utilizando a linha sete para exemplificar, referente à proposta 1, tem-se o seguinte: as colunas 2, 3 e 4 mostram o somatório das distâncias das cidades que compõem as macrorregiões às cidades sede de suas macrorregiões (34.126 km), regionais (18.169 km) e microrregiões (7.725 km), respectivamente. Na quinta coluna é apresentada a soma dessas distâncias (60.020 km). Nas três colunas seguintes, são apresentadas as diferenças entre o somatório das distâncias encontradas na proposta e o somatório das distâncias com a configuração usada atualmente pela SESA; nas macrorregiões encontrou-se a diferença de 11.525 km, nas regionais a diferença foi de 4.405 km e nas microrregiões a diferença ficou em 6.889 km, totalizando assim uma diferença total de 22.819 km, mostrada na coluna nove. A coluna 10 mostra o número de macrorregiões utilizadas na proposta 1 (7), assim como nas colunas 11 e 12, que mostram o número de regionais (22) e de microrregiões (83), respectivamente.
5 Conclusões e sugestões para trabalhos futuros
A técnica apresentada para otimizar o fluxo de pacientes mostrou-se muito eficaz e extremamente útil, já que além de definir para qual cidade deve ser encaminhado o paciente, respeitando a divisão hierárquica da cidade de origem, ela também faz o controle dos procedimentos médicos realizados por cada cidade, em cada período estipulado, fornecendo melhores informações à SESA-PR sobre a capacidade de atendimento das cidades, indicando carências de atendimento de uma cidade ou, até mesmo, de uma região.
Desta forma, o fluxo de pacientes tenderá a ser cada vez mais regionalizado, desafogando as principais cidades, economizando no transporte público desses pacientes e estimulando a economia local, já que em muitos casos os familiares costumam acompanhar os pacientes. Considerando que o tempo computacional para se obter a resposta ao fluxo de pacientes é muito pequeno (aproximadamente dois segundos), a ferramenta pode ser utilizada em uma futura e possível integração computacional do sistema de saúde estadual para marcações de consultas e de internamentos hospitalares. Assim, os pacientes poderiam procurar o atendimento necessitado na Internet e obteriam a resposta rapidamente, facilitando a resolução de seu caso.
A nova proposta para a regionalização da saúde (divisão otimizada do estado) apresentada neste trabalho consiste em retirar as cidades sede de divisão superiores para serem candidatas a sedes das divisões inferiores; com isso, aumenta-se o número de opções para atendimento dos pacientes, que terão no mínimo três diferentes cidades para buscar atendimento, mesmo se utilizada na política atual de designação de pacientes para outras cidades que não a sua de origem. A política atual permite que somente as cidades sede recebam os cidadãos de sua divisão hierárquica.
Outro aspecto importante na nova proposta de divisão otimizada do estado é o fato de haver menos divisões hierárquicas do que atualmente, principalmente nas microrregiões, e também ao fato da distância total da configuração se equivaler à atual. A conseqüência deste fato é que o investimento em saúde pública se tornará mais eficaz, equilibrando a capacidade das cidades sede para atendimento na sua responsabilidade, conforme a complexidade dos atendimentos, com menos recursos, já que existem menos cidades para investir. Em contrapartida, os cidadãos terão mais opções para atendimento do que atualmente, percorrendo uma menor distância, melhorando assim o desempenho da saúde pública estadual.
O tempo computacional para encontrar as medianas aumenta muito quando a relação de pontos n e o número p de medianas é grande. Por exemplo, para 151 pontos e seis medianas, maior caso aqui resolvido, o algoritmo foi executado por cerca de seis horas; já nos casos mais simples, por exemplo, 23 pontos e cinco medianas, o algoritmo levou cerca de um minuto. Para o problema de p-medianas abordado, no entanto, o tempo computacional é irrelevante sob o aspecto logístico, pois a qualidade da solução é muito mais importante do que o tempo para encontrá-la.
Aliando a técnica do fluxo dos pacientes à otimização na divisão do estado, tem-se que na proposta 3 de divisão hierárquica há uma possibilidade real de melhorias no atendimento da saúde pública no estado do Paraná. O menor número de cidades sede, a menor distância percorrida pelos pacientes, mais opções de atendimento, identificação das carências regionais e maior controle dos procedimentos realizados constituem uma proposta de melhorar os investimentos na saúde, otimizando recursos públicos, criando parâmetros para investimentos realmente necessários, e aumentando a satisfação dos pacientes, atendendo a todos que necessitam, procurando assim atingir o objetivo constitucional do estado que é o de fornecer atendimento médico para todos gratuitamente e de qualidade.
Fica para trabalhos futuros a comparação de resultados encontrados pelo algoritmo branch and price e outros métodos heurísticos e/ou meta heurísticos. Vale salientar que todo problema de logística pode e deve ser estudado combinando ferramentas matemáticas existentes e levando em consideração as características específicas dos problemas que se encontram no mundo atual. Assim, com esta combinação, poderemos encontrar melhores soluções práticas e também desenvolver ferramentas matemáticas cada vez mais eficazes para a busca de melhores soluções.
Recebido em 6/7/2007
Aceito em 10/6/2008
Agradecimentos: Os autores agradecem à SESA, ao IPARDES e ao DNIT pelos dados concedidos que permitiram o desenvolvimento deste trabalho.
- BALLOU, R. H. Logística empresarial São Paulo: Editora Atlas, 1993.
- BRASIL. Ministério da Saúde. Secretaria de Assistência à Saúde. Norma Operacional da Assistência à Saúde – NOAS – SUS 01/2002. Portaria GM. Brasília, 2002a Disponível em: <http://www.saude.gov.br >. Acesso em: 22 de novembro de 2005.
- BRASIL. Ministério da Saúde. Secretaria de Assistência à Saúde. Departamento de Descentralização da Gestão da Assistência. Norma Operacional da Assistência à Saúde – NOAS-SUS 01/2002. Regionalização da assistência à saúde: aprofundando a descentralização com eqüidade no acesso. Portaria MS/GM n.º 373, de 27 de fevereiro de 2002, e regulamentação complementar. 2.ª ed. Brasília, DF, 2002b.
- BRASIL. Ministério da Saúde. Departamento de Apoio à Descentralização. A regionalização da saúde Brasília, 2004a. (Versão preliminar).
- BRASIL. Conselho Nacional de Secretários da Saúde. Regionalização solidária: proposta para a Oficina Agenda para um novo pacto de gestão do SUS. Brasília: CONASEMS, 2004b. (Documento preliminar).
- PREFEITURA MUNICIPAL DE CAMPINA GRANDE, PB. Regionalização do serviço de atendimento móvel de urgência de Campina Grande Projeto de Regionalização do SAMU de Campina Grande-PB, elaborado de acordo com as Normas de Cooperação Técnica e Financeira de Programas e Projetos do Ministério da Saúde. 2. ed. Campina Grande, 2003.
- CHRISTOFIDES, N. Graph Theory: An Algorithmic Approach. New York: Academic Press, 1975.
- GLOVER, F. Surrogate constraints. Operations Research, USA, v. 16, n.4, p. 741-749, 1968.
- IPARDES. Tecnologias adequadas em equipamentos e serviços à saúde para escalas regionalmente diferenciadas: referência para rediscussão da regionalização em saúde. Curitiba: Secretaria de Estado da Ciência, Tecnologia e Ensino Superior/ Fundo Paraná, 2005. 198 p.
- JÄRVINEN, P. J.; RAJALA, J.; SINERVO, H. A branch and bound algorithm for seeking the p-median. Operations Research, USA, v. 20, no. 1, p. 173-178, 1972.
- LORENA, L. A. N.; SENNE, E. L. F.; SALOMÃO, S. N. A. A relaxação lagrangeana/surrogate e o método de geração de colunas: novos limitantes e novas colunas. Pesquisa Operacional, Rio de Janeiro, v. 23, n.1, p. 29-47, 2003.
- MINOUX, M. A. A class of combinatorial problems with polynomially solvable large scale set covering/partitioning relaxations. R.A.I.R.O. Recherche Opérationnelle, Paris, França, v. 21, n. 2, p. 105-136, 1987.
- NARCISO, M. G. A relaxação lagrangeana/surrogate e algumas aplicações em otimização combinatória São José dos Campos, 1998. 134p. Tese - (Doutorado em Computação Aplicada), Instituto Nacional de Pesquisas Espaciais.
- SECRETARIA DE ESTADO DA SAÚDE DO PARANÁ. Plano diretor de regionalização Curitiba, 2001.
- PARKER, R. G.; HARDIN, R. L. Discrete Optimization. New York: Academic Press, 1988. 472 p.
- PEREIRA, M. A. Um método Branch-and-price para o problema de localização de p-medianas São José dos Campos, 2005. 88 p. Tese - (Doutorado em Computação Aplicada), Instituto Nacional de Pesquisas Espaciais.
- SCARPIN, C. T.; STEINER, M. T. A.; DIAS, G. J. C. Técnicas de Pesquisa Operacional aplicadas na Otimização do Fluxo de Pacientes do Sistema único de Saúde do Estado do Paraná. In: Simpósio Brasileiro de Pesquisa Operacional - SBPO, 38, 2006, Goiânia, GO. Anais... Goiânia, 2006.
- SENNE, E. L. F.; LORENA, L. A. N. Lagrangean/surrogate heuristics for p-median problems. In: M. Laguna and J. L. Gonzales-Velarde (Eds.). Computing Tools for Modeling, Optimization and Simulation: Interfaces in Computer Science and Operations Research. Kluwer Academic Publishers, 2000. p. 115-130.
- SENNE, E. L. F.; LORENA, L. A. N. Abordagens complementares para problemas de p-medianas São José dos Campos: Instituto Nacional de Pesquisas Espaciais (LAC/IMPE), 2003.
- SWAIN, R. W. A parametric decomposition approach for the solution of uncapacitated location problems. Management Science, Application Series, v.21, n.2, p. 189-198, oct. 1974.
Datas de Publicação
-
Publicação nesta coleção
17 Set 2008 -
Data do Fascículo
Ago 2008
Histórico
-
Aceito
10 Jun 2008 -
Recebido
06 Jul 2007