Resumos
A análise de capacidade do processo para dados com distribuição não-normal tem sido explorada nos últimos anos, porém ainda são poucas as referências que abordam este assunto. Por isto, este trabalho apresenta os principais métodos de análise de capacidade do processo para dados com distribuição não-normal, sendo o primeiro deles o método proposto por Clements em 1989, o segundo, proposto por Pearn e Chen (1997) e o terceiro método apresentado foi proposto por Chen e Ding (2001). Os métodos de Clements (1989) e Pearn e Chen (1997) são parecidos em muitos aspectos, mas cada um deles apresenta uma novidade em relação ao cálculo dos índices de capacidade. Em comum, ambos os métodos apresentam índices semelhantes aos índices tradicionais, que supõem normalidade dos dados. O método de Chen e Ding (2001) é em si uma forma de estimar o número de não-conformes observado no processo em estudo. Além de abordar os métodos, são apresentados dois casos. No primeiro deles, comparando-se os métodos de Clements (1989) e de Pearn e Chen (1997), procura-se concluir qual dos métodos é o melhor para o cálculo da capacidade do processo não-normal. No segundo, os três métodos apresentados são aplicados em um conjunto de dados, obtidos de uma indústria metalúrgica. Para a execução das análises nos casos, foi aplicado o software livre R versão 2.2.
Índices de capacidade; Dados não-normais; Capabilidade
Although process capability analysis for non-normal data has been used lately, there are only few works on this subject. This article presents the major methods for process capability analysis with non-normal data. Tree methods are presented, which were proposed by Clements in 1989, Pearn and (1997), and Chen and Ding (2001). The first two methods are similar in many aspects, but each one presents novelties in the computation of the capability indexes. They present indexes similar to the traditional ones, which assume normality. The method by Chen and Ding (2001) brings as novelty the use of an index to estimate the number of nonconforming items produced in the process. After the review of these methods, they are compared by means of their application in two cases. In the first case, the methods by Clements (1989) and by Pearn and Chen (1997) were analyzed to identify the best for the non-normal process capability determination. In the second case, all three methods were applied in a metallurgical industry data set. In both cases, the free software R (version 2.2) was used for the statistical analysis.
Capability index; Non-normal data; Capability
Comparação dos índices de capacidade do processo para distribuições não-normais
Comparations of process capability index to non-normal distribuitions
Patricia Ueda Gonçalez; Liane Werner
Programa de Pós-Graduação em Engenharia de Produção Universidade Federal do Rio Grande do Sul, Av. Osvaldo Aranha, 99, 5º andar, Porto Alegre, RS, CEP 90035-190, e-mails: patyueda@yahoo.com.br; liane@producao.ufrgs.br
RESUMO
A análise de capacidade do processo para dados com distribuição não-normal tem sido explorada nos últimos anos, porém ainda são poucas as referências que abordam este assunto. Por isto, este trabalho apresenta os principais métodos de análise de capacidade do processo para dados com distribuição não-normal, sendo o primeiro deles o método proposto por Clements em 1989, o segundo, proposto por Pearn e Chen (1997) e o terceiro método apresentado foi proposto por Chen e Ding (2001). Os métodos de Clements (1989) e Pearn e Chen (1997) são parecidos em muitos aspectos, mas cada um deles apresenta uma novidade em relação ao cálculo dos índices de capacidade. Em comum, ambos os métodos apresentam índices semelhantes aos índices tradicionais, que supõem normalidade dos dados. O método de Chen e Ding (2001) é em si uma forma de estimar o número de não-conformes observado no processo em estudo. Além de abordar os métodos, são apresentados dois casos. No primeiro deles, comparando-se os métodos de Clements (1989) e de Pearn e Chen (1997), procura-se concluir qual dos métodos é o melhor para o cálculo da capacidade do processo não-normal. No segundo, os três métodos apresentados são aplicados em um conjunto de dados, obtidos de uma indústria metalúrgica. Para a execução das análises nos casos, foi aplicado o software livre R versão 2.2.
Palavras-chave: Índices de capacidade. Dados não-normais. Capabilidade.
ABSTRACT
Although process capability analysis for non-normal data has been used lately, there are only few works on this subject. This article presents the major methods for process capability analysis with non-normal data. Tree methods are presented, which were proposed by Clements in 1989, Pearn and (1997), and Chen and Ding (2001). The first two methods are similar in many aspects, but each one presents novelties in the computation of the capability indexes. They present indexes similar to the traditional ones, which assume normality. The method by Chen and Ding (2001) brings as novelty the use of an index to estimate the number of nonconforming items produced in the process. After the review of these methods, they are compared by means of their application in two cases. In the first case, the methods by Clements (1989) and by Pearn and Chen (1997) were analyzed to identify the best for the non-normal process capability determination. In the second case, all three methods were applied in a metallurgical industry data set. In both cases, the free software R (version 2.2) was used for the statistical analysis.
Keywords: Capability index. Non-normal data. Capability.
1 Introdução
Atualmente as empresas buscam produzir com a menor perda possível, de tempo, recursos e custos, sem deixar de atender aos desejos e necessidades dos clientes. Para atingir esse objetivo, muitas empresas fazem uso do controle estatístico do processo, um dos ramos do controle de qualidade, que trata da coleta, análise e interpretação de dados para a proposta de melhorias e controle da qualidade de produtos e serviços.
Analisando-se a variabilidade do processo, têm-se duas classificações possíveis para ele. O processo é dito estatisticamente sob controle quando somente causas comuns de variabilidade estiverem presentes. Ao contrário, se um processo apresentar, além das causas comuns de variabilidade, causas especiais, ele será dito fora de controle estatístico.
Quando se verifica que o processo encontra-se sob controle estatístico, pode-se medir quanto esse processo consegue gerar produtos que atendam às especificações de projeto que refletem os desejos e exigências de seus clientes. Para isso, faz-se uso dos índices de capacidade do processo. Os índices estabelecidos nos estudos tradicionais de capacidade do processo, ou de capabilidade do processo, do inglês process capability, procuram detectar dois tipos de problemas. O primeiro é de localização do processo, se o processo atende em média ao valor nominal de especificação, e o segundo, de variabilidade, quando o processo apresenta muita dispersão e não atende às especificações (bilaterais) que são estabelecidas no projeto.
A teoria de capacidade do processo foi primeiramente desenvolvida supondo-se que o processo em análise apresenta distribuição normal e quando a característica de qualidade é do tipo nominal com especificações bilaterais, porém, em algumas situações, é desejável atender a uma especificação unilateral, na qual, certamente, um processo não-normal seria desejado. Por exemplo, produtos alimentares, que são obrigados por lei a ter certo peso, por causa do custo, terão uma quantidade mais próxima desse peso, o que certamente irá gerar um processo com assimetria (não-normal). Sendo assim, é importante que se busquem alternativas para atender a este tipo de situação, visando minimizar conclusões errôneas na análise da capacidade.
2 Capacidade do processo
Quando as causas especiais de variação são eliminadas de um processo com distribuição normal relativo à característica de qualidade em estudo, diz-se que o processo está sob controle estatístico ou que se trata de um processo estável. Porém, mesmo um processo sob controle estatístico produz itens defeituosos. Logo, não é suficiente colocar e manter um processo sob controle; é fundamental avaliar se o processo é capaz de atender às especificações estabelecidas a partir das necessidades dos clientes. É esta avaliação que constitui a análise da capacidade do processo, que é medida através da relação entre a variabilidade natural do processo em relação à variabilidade que é permitida a esse processo, dada pelos limites de especificação.
Conforme Montgomery (1997) e Deleryd (1999), quatro são os índices de capacidade para dados normalmente distribuídos. Estes índices são números adimensionais que permitem uma quantificação do desempenho de processos, sendo eles: Cp, Cpk, Cpm e Cpmk.
2.1 Índice Cp
O índice Cp, chamado de índice de capacidade potencial do processo, considera que o processo está centrado no valor nominal da especificação. Caso a característica de qualidade em estudo tenha distribuição bilateral, o índice Cp é definido pela Equação (1).

em que: LSE é o limite superior de especificação; LIE é o limite inferior de especificação e σ é o desvio-padrão do processo.
Este índice relaciona a variabilidade permitida ao processo (especificada no projeto) com a variabilidade natural do processo, e com isso tem-se que quanto maior for o valor de Cp, maior será a capacidade do processo em satisfazer às especificações, desde que a média esteja centrada no valor nominal. Uma regra prática, conforme Montgomery (1997), para analisar este índice é definir três intervalos de referência, mostrados na Tabela 1.
Porém, o índice Cp, não considera a localização do processo, estando embasado apenas na relação entre a amplitude do intervalo de especificação e da variabilidade natural do processo para o seu cálculo. Como consequência disto, para um determinado valor de Cp, pode-se ter qualquer percentual de itens fora das especificações, este percentual vai depender apenas de onde está localizada a média do processo. Por isso, o índice Cp dá apenas uma idéia de quanto o processo é potencialmente capaz de produzir dentro do intervalo especificado no projeto.
2.2 Índice Cpk
Como na prática nem sempre o processo está centrado no valor nominal da especificação então, o uso do índice Cp pode levar a conclusões erradas, Kane (1986) propôs o índice de desempenho Cpk, que leva em consideração a distância da média do processo em relação aos limites de especificação. Este índice é dado pela Equação (2).

em que: LSE é o limite superior de especificação; LIE é o limite inferior de especificação; µ é a média do processo e σ é o desvio-padrão do processo.
Se o processo estiver centrado no valor nominal de especificação, Cp = Cpk. Então, caso Cp seja diferente de Cpk, sabe-se que o processo está descentrado, isto é, que a média não coincide com o valor nominal das especificações. As interpretações do índice Cpk podem ser feitas pela regra mostrada para o índice Cp, já que a análise da capacidade do processo é feita usando-se estes dois índices em conjunto.
2.3 Índice Cpm e Cpmk
São alternativos aos índices anteriores e consideram, além da variação do processo, a distância de sua média em relação ao valor nominal da especificação.
O índice Cpm é dado pela expressão da Equação (3).

em que: LSE é o limite superior de especificação; LIE é o limite inferior de especificação; µ é a média do processo; σ é o desvio-padrão do processo; e T é o valor nominal da especificação.
Pela definição do índice Cpm, um aumento na variabilidade do processo faz com que o denominador do índice aumente e consequentemente o valor do índice diminuirá. Além disso, um distanciamento maior do processo em relação ao valor nominal também poderá provocar um aumento no denominador do índice, tornando-o menor.
Uma vantagem do índice Cpm em relação ao índice Cp é que ele fornece uma boa idéia da capacidade do processo, tanto para os processos que se apresentam próximos ao valor nominal quanto para os que se apresentam mais afastados dele. Além disso, segundo Chan et al. (1988), se o processo segue uma distribuição normal e a média do processo está centrada no valor nominal de especificação, o índice Cpm apresenta distribuição semelhante à do índice Cp, mas seu estimador é mais eficiente e apresenta viés menor que , estimador de Cp.
Como o índice Cpm considera em seu numerador apenas a variabilidade permitida ao processo, a literatura sugere ainda outro índice, o Cpmk, que refina mais a análise, já que considera a menor distância entre a média do processo em relação aos limites de especificação em seu numerador. Seu cálculo é dado pela Equação (4).

em que: LSE é o limite superior de especificação; LIE é o limite inferior de especificação; µ é a média do processo; σ é o desvio-padrão do processo e T é o valor nominal da especificação.
2.4 Formulação única dos índices
Vännman (1995) construiu uma fórmula única da qual podem ser derivados os índices de capacidade. Os quatro índices apresentados (Cp, Cpk, Cpm, Cpmk) poderiam ser vistos como seus casos especiais. A fórmula de Vännman é definida conforme a Equação (5).

em que: µ é a média do processo; σ é o desvio-padrão do processo;  é a metade do comprimento do intervalo de especificação;
é a metade do comprimento do intervalo de especificação;  é o ponto médio entre os limites de especificação; T é o valor nominal e u, v
é o ponto médio entre os limites de especificação; T é o valor nominal e u, v  0.
0.
Substituindo-se u e v por combinações de 0 e 1 na Equação (5), chega-se aos índices de capacidade já apresentados: Cp(0,0) = Cp; Cp(1,0) = Cpk; Cp(0,1) = Cpm; Cp(1,1) = Cpmk. Além de poderem ser derivados de uma fórmula única, estes índices se relacionam conforme as Equações (6) e (7).


Além disto, para processos com limites de especificação simétricos em relação ao valor nominal e com média do processo sobre esse valor nominal, os índices Cpk, Cpm e Cpmk tornam-se iguais ao índice Cp.
Em um estudo realizado por Pearn e Chen (1997), foi estabelecido um ranking entre os quatro índices. O rankeamento considera a sensibilidade de captar a distância entre a média do processo e o valor nominal de especificação. Os autores concluíram que o índice mais sensível é o Cpmk, sendo seguido pelo Cpm, Cpk e Cp, respectivamente.
3 Capacidade do processo não-normal
Muitas indústrias, pelo desconhecimento dos métodos de análise da capacidade de processos não-normais, assumem que seu processo fornece dados que são normalmente distribuídos e fazem uso de um ou mais índices citados anteriormente para analisar a capacidade de produção de itens conformes. Porém essa prática pode gerar interpretações errôneas sobre a capacidade do processo, já que os índices Cp, Cpk, Cpm e Cpmk supõem normalidade da característica de qualidade em estudo.
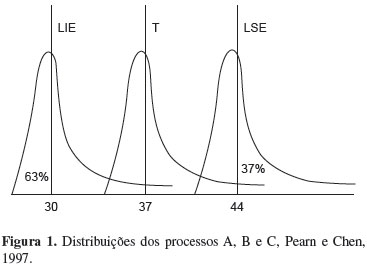
Para exemplificar que tipo de interpretação errônea pode ser provocada pelo uso desses índices básicos em distribuições não-normais, Pearn e Chen (1997) consideram três processos A, B e C, todos com distribuição qui-quadrado com 2 graus de liberdade. Na figura 1, são mostradas as distribuições dos três processos e suas relações com os limites de especificação, sendo que o processo A apresenta média igual a 30, o processo B, média igual a 37, e o processo C apresenta média igual a 44. Todos os processos apresentam desvio-padrão igual a 2.
Observando-se a Figura 1, nota-se que o processo A apresenta média igual ao LIE, a média do processo B é igual ao valor nominal de especificação e que o processo C tem média igual ao LSE. A partir destas informações, tem-se que o processo B está centrado no valor nominal e que os processos A e C apresentam-se igualmente, porém opostamente, distantes do valor nominal. Calculando-se os quatro índices de capacidade, supondo-se normalidade destes processos, verifica-se, conforme a Tabela 2, que eles não permitem estimar um percentual correto de itens não-conformes, já que esse percentual para o processo A é de 63% e para C é de 37%, mas os índices dos processos A e C não apresentaram diferenças entre si, conforme os índices citados.
Interessante também comparar o comportamento do processo B, supondo-se diferentes distribuições com o Cp = 1,17. Se este processo apresenta distribuição normal com média 37 e desvio-padrão condizente com o referido Cp, não se encontrariam produtos fora das especificações, o que não ocorre com a distribuição Χ2 com 2 graus de liberdade, em que o percentual de itens fora da especificação no limite superior é estimado em 3,18%.
Somerville e Montgomery (1996-1997) fizeram um estudo para verificar os efeitos da falta de normalidade dos dados no cálculo do número de itens não-conformes produzidos por um processo em quatro famílias de distribuições não-normais: t-Student, gamma, lognormal e Weibull. Neste estudo, diversos valores de Cpk foram usados para estimar o número de itens não-conformes, em partes por milhão (PPM), considerando-se que o processo seguia uma distribuição normal. Com isso, verificaram que pequenos afastamentos de uma curva em relação à normal produziam sérios erros de estimação do número de não-conformes. As tabelas 3 e 4 resumem alguns resultados obtidos pelo estudo.
De uma forma geral, observa-se na tabela 3 que, para os parâmetros estudados, quanto maior a capacidade do processo, menor é o erro absoluto cometido na estimação do número de não-conformes. Em relação à variação dos parâmetros, tem-se que: a) no caso da distribuição t-Student, este erro se tornava menor quanto maior o número de graus de liberdade, pois a distribuição se aproximava da distribuição normal; b) para a distribuição gamma, fixado o parâmetro β, quanto maior o valor de α , mais simétrica a distribuição se torna, o que diminui o erro na estimação do número de não-conformes, supondo normalidade; c) a distribuição lognormal, diferentemente das demais, tem a assimetria aumentada quanto maior o valor do parâmetro β , com isso, maior se torna o erro na estimação do número de não-conformes; d) na distribuição Weibull, para β = 1, quanto maior o valor de α , mais próxima ela se torna da distribuição normal, porém quando α > 3, a área sob a cauda na distribuição Weibull é menor que a cauda da distribuição normal.
Para se ter o mesmo número de não-conformes obtido na estimação de cada uma das quatro distribuições apresentadas, Somerville e Montgomery (1996-1997) calcularam o valor equivalente de Cpk da distribuição normal para estes números de não-conformes. Os valores obtidos, que são apresentados na tabela 4, mostram que sob suposição de normalidade, a capacidade do processo é superestimada para estas quatro distribuições, com exceção da distribuição Weibull, que apresenta área sob a cauda menor que a da distribuição normal quando o parâmetro α = 3, para processos capazes.
Com essas distribuições não-normais, Somerville e Montgomery (1996-1997) exemplificaram como a suposição de normalidade, quando não atendida, pode produzir estimativas erradas do número de itens não-conformes. Como o não atendimento da suposição de normalidade dos dados pode levar a conclusões errôneas sobre o processo, é necessário buscar por alternativas que utilizem as distribuições adequadas. As já divulgadas transformações de Box-Cox ou de Johnson, em que dados que não são normalmente distribuídos são convertidos em dados que apresentam distribuição normal, têm sido utilizadas, pois são práticas e fáceis de aplicar. Porém este trabalho aborda métodos alternativos para a análise da capacidade do processo. São três os métodos: Clements (1989), Pearn e Chen (1997) e Chen e Ding (2001).
O primeiro deles, proposto por Clements (1989), se baseia em medidas de percentil para obter os índices de capacidade C'p e C'pk. A partir desse método de Clements, Pearn e Kotz, Pearn e Chen apud Pearn e Chen (1997) propuseram uma generalização da formulação única apresentada na Equação (5) para que se pudessem obter quatro índices com interpretações semelhantes aos dos índices para dados normais.
O segundo método, proposto por Pearn e Chen (1997), também faz uso dos percentis para o cálculo dos índices, diferindo apenas quanto aos índices C'pk e C'pmk, pois no cálculo do denominador destes índices, é considerada a metade da distância entre os percentis da distribuição, enquanto no primeiro método se tem a distância entre a mediana e o percentil, superior ou inferior.
O terceiro método foi proposto por Chen e Ding (2001) e considera em seu cálculo a variabilidade do processo, a distância entre a média do processo e o valor nominal e a proporção de itens não-conformes, obtendo o índice Spmk. Este índice proposto por este terceiro método consegue refletir exatamente o número de não-conformes do processo, sendo superior aos outros dois métodos anteriores (CHEN; DING, 2001).
3.1 Método 1- Índices propostos por Clements
Em 1989, Clements propôs um método simples de cálculo dos índices Cp e Cpk para qualquer tipo de distribuição dos dados de interesse, usando a família de curvas de Pearson. Essa família de curvas foi publicada em 1893, pelo matemático Karl Pearson, e inclui diversas distribuições, sendo elas a normal, a lognormal, a t-student, a F, a beta e a gamma.
Segundo o autor, seu método de cálculo dos índices apresenta algumas vantagens, como por exemplo, a redução de seus índices aos índices Cp e Cpk quando a distribuição dos dados é normal, a possibilidade de estimar o percentual de itens não-conformes para uma grande variedade de distribuições e, ainda, poder ser aplicado em qualquer família de curvas de probabilidade.
O índice Cp de Clements é definido pela Equação (8):

em que: LSE é o limite superior de especificação, LIE é o limite inferior de especificação e Fα é o percentil na posição α-ésima do processo.
Mas como o índice C'p considera apenas a dispersão do processo e não leva em conta a sua posição em relação aos limites de especificação, ele pode levar a uma interpretação errada da capacidade do processo. Considerando-se também a posição do processo, tem-se o índice C'pk de Clements, que é definido como o mínimo de dois índices, C'pI e C'pS, definidos pelas Equações (9) e (10):


em que: M é a mediana do processo, LSE é o limite superior de especificação, LIE é o limite inferior de especificação e Fα é o percentil α-ésimo do processo.
Para garantir que CpI e CpS venham a medir a relação de cada metade da distribuição, tanto inferior como superior, com as respectivas especificações, utiliza-se a mediana como medida de tendência central.
Quando a distribuição dos dados é normal, a distância entre a mediana e cada um dos limites de especificação é igual a 3σ . Com isso, o índice C'p de Clements se reduz ao índice Cp tradicional, mostrado na Equação (1). Nesta situação, o índice C'pk de Clements também se reduz ao índice Cpk tradicional da Equação (2).
Posteriormente Pearn e Kotz (1992) e Pearn e Chen (1995) apud Pearn e Chen (1997), baseados neste método de Clements, propuseram uma generalização da formulação única mostrada na Equação (5), da qual se obteriam quatro índices para dados com distribuição não-normal. Essa generalização é dada pela Equação (11):

em que: LSE e LIE são os limites superior e inferior de especificação, respectivamente; Fα é o α-ésimo percentil do processo, M é a mediana, T é o valor nominal do processo e u, v > 0.
Substituindo-se (u,v) pelas diversas combinações de 0 e 1, obtêm-se os quatro índices equivalentes aos índices para distribuições normais, que podem ser interpretados da mesma forma, porém atendendo a qualquer distribuição, não se restringindo apenas à normal. Esses índices são mostrados na Tabela 5 (Equações 8, 12, 13, 14).
3.2 Método 2- Índices propostos por Pearn e Chen
Fazendo uso da formulação única apresentada na Equação (5), Pearn e Chen (1997) propuseram uma generalização, chamada de CNp(u,v), que atende a casos em que a suposição de normalidade não seja verificada. Essa generalização é dada pela Equação (12):

em que: Fα é o α-ésimo percentil, M é a mediana da distribuição, é a metade do comprimento do intervalo de especificação, é o ponto médio entre os limites de especificação, T é o valor nominal e u, v > 0.
Para desenvolver essa generalização, Pearn e Chen substituíram o desvio-padrão σ de Cp(u,v) por  em CNp(u,v), pois assim é mantida a idéia de medir a variabilidade inerente ao processo, mas não se restringindo à distribuição normal. Outra substituição feita foi da média µ em Cp (u,v) pela mediana M em CNp (u,v), já que a mediana é uma medida mais robusta para tendência central que a média quando existe uma distribuição assimétrica, especialmente se essa distribuição tiver caudas longas.
em CNp(u,v), pois assim é mantida a idéia de medir a variabilidade inerente ao processo, mas não se restringindo à distribuição normal. Outra substituição feita foi da média µ em Cp (u,v) pela mediana M em CNp (u,v), já que a mediana é uma medida mais robusta para tendência central que a média quando existe uma distribuição assimétrica, especialmente se essa distribuição tiver caudas longas.
Da mesma forma que no primeiro método, substituindo (u,v) pelas diversas combinações de 0 e 1, obtêm-se os quatro índices equivalentes aos índices para distribuição normal, que também podem ser interpretados da mesma forma, porém atendendo a qualquer distribuição, não se restringindo apenas à normal. Note-se que CNp = C'p e que CNpk = C'pk. Os índices CNp (u,v) são apresentados na Tabela 6 (Equações 8, 13, 16, 17).
Assim como nos índices para distribuição normal, pode ser estabelecida uma relação entre os índices: CNpm = CNp{1 + [(µ-T)/σ"]2}-1/2 e CNpmk = CNpk{1 + [(µ-T)/σ"]2}-1/2, em que σ" = (F99,865 - F0,135)/6. Também existe um ranking (PEARN; CHEN, 1997), para os quatro índices propostos, segundo sua sensibilidade em captar a distância entre a mediana do processo e o valor nominal, do mais sensível ao menos, tem-se: CNpmk, CNpm, CNpk e CNp.
Quando as especificações são simétricas em relação ao valor nominal, CNpk = (1-k)CNp e CNpmk = (1-k)CNpm, em que k = |M - T|/d e . Se o processo com distribuição não-normal está centrado no valor nominal, isto é, M = T, CNp = CNpk = CNpm = CNpmk = d/3σ". Mais ainda, se a distribuição dos dados for normal, têm-se M = m e s" = s, e, então, vale ressaltar que as generalizações CNp (u,v) reduzir-se-ão aos quatro índices básicos Cp (u,v), obtendo-se CNp = Cp, CNpk = Cpk, CNpm = Cpm e CNpmk = Cpmk.
3.3 Método 3 - índice proposto por Chen e Ding
O terceiro método se refere à proposta de Chen e Ding (2001). Os autores propuseram um índice denominado Spmk, que atende a qualquer distribuição de dados, e considera em seu cálculo a variabilidade do processo, a distância da média do processo em relação ao valor nominal e a proporção de não-conformes. Esse índice é dado pela Equação (13):

em que: F(x) é a função de distribuição acumulada do processo, µ é a média do processo, σ é o desvio padrão do processo, T é o valor nominal de especificação, LIE é o limite inferior de especificação e LSE é o limite superior de especificação.
Segundo Chen e Ding (2001), a construção deste índice vem da seguinte propriedade dos índices apresentada pela Equação (19):

em que: K é o índice de capacidade obtido pela expressão
, µ, σ e T são, respectivamente, a média, o desvio-padrão e o valor alvo do processo.
Segundo Chen (2000), em qualquer distribuição de probabilidade, a expressão  é uma boa aproximação para o valor de Cpk na Equação (19), sendo que
é uma boa aproximação para o valor de Cpk na Equação (19), sendo que denota a função acumulada da distribuição normal padrão.
denota a função acumulada da distribuição normal padrão.
A proporção de não-conformes P pode ser estimada a partir de Spmk é dada pela Equação (20):

e não difere da proporção real de não-conformes (CHEN; DING, 2001).
Para mostrar a superioridade de seu índice em relação ao índice CNpmk, descrito na Equação (19), Chen e Ding (2001) aplicaram o índice Spmk em seis processos não-normais: (i) Χ23 + 7; (ii) Χ23 + 14,8; (iii) Χ23 + 22,6; (iv) Gamma (6,3); (v) Gamma (1,12); e (vi) uniforme (17; 25,8). Para cada um destes processos, foi obtido a P(X < 10,0) + P(X > 25,6), sendo o limite inferior de especificação igual a 10 e o superior igual a 25,6, para este exemplo. Em seguida, os autores calcularam o percentual de erro na estimação da proporção de itens não-conformes gerados pelo uso do índice CNpmk, de Pearn e Chen (1997) e como resultado obtiveram percentuais de erro razoáveis, sendo o menor deles 28,7 e o maior, 106,2. Com isso, evidenciaram que o índice CNpmk não fornecia estimativas corretas da proporção de não-conformes, enquanto o índice Spmk o fornecia. Quanto à interpretação do índice Spmk, é a mesma dos demais índices; por exemplo, se o valor do índice obtido foi Spmk = 0, 4092, interpreta-se que o processo não é capaz.
4 Estudos comparativos dos métodos de capacidade não-normal apresentados
Primeiramente será apresentado um caso prático para a comparação entre os índices de capacidade para processos não-normais, que inclui um estudo que foi realizado por Pearn e Chen (1997). A seguir será apresentado um estudo que consiste na aplicação dos três métodos de análise de capacidade do processo não-normal apresentados anteriormente, em um banco de dados real, obtido de uma metalúrgica da Grande Porto Alegre. Todos os resultados são obtidos a partir do software livre R versão 2.2.
4.1 Estudo comparativo entre os métodos de análise de capacidade do processo não-normal
Neste estudo, é mostrado um estudo comparativo entre os métodos 1 e 2 de capacidade do processo não-normal. Os dois métodos que serão comparados fazem uso dos percentis para o cálculo dos índices, porém enquanto os índices de Clements (1989) consideram em seu denominador a distância entre a mediana e o percentil, superior ou inferior, para o cálculo dos índices C'pk e C'pmk, os índices de Pearn e Chen (1997) fazem uso da metade da distância entre os percentis da distribuição no cálculo do denominador dos índices CNpk e CNpmk.
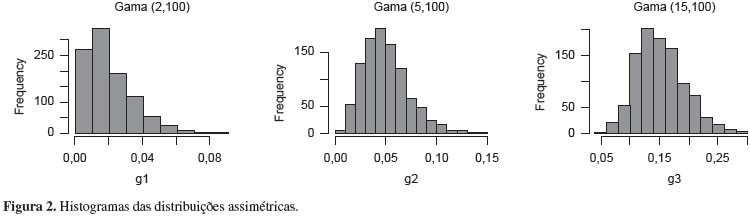
Devido a essa diferença entre os métodos, quanto mais assimétrica for a distribuição dos dados, mais diferentes serão os denominadores desses índices e, por consequência, mais diferentes serão os resultados obtidos da análise de capacidade do processo desses dois métodos. Para exemplificar essa diferença entre os dois métodos, são geradas três distribuições assimétricas: Gamma (2,100), Gamma (5,100) e Gamma (15,100), cada uma com 1000 repetições, cujos histogramas são mostrados na Figura 2, e algumas estatísticas descritivas necessárias para o estudo estão na Tabela 7.
Calculando a "distância relativa" da mediana em relação ao valor nominal para as distribuições simuladas, tem-se a Equação (21):

em que: X é a variável de interesse que foi medida, T é o valor nominal de especificação e M é a mediana do processo.
As medidas mostradas na Tabela 8 foram obtidas da Equação (21), com esses resultados e observando os histogramas da Figura 2, tem-se que o processo representado pela distribuição Gamma (2,100) é o pior deles, pois este processo é o que está centrado em um valor mais distante do seu valor nominal, e que o representado pela distribuição Gamma (15,100) é o melhor deles, já que a mediana e o valor nominal encontram-se mais próximos que nos outros dois processos simulados.
Para comparar os índices propostos por Clements (1989) e os índices propostos por Pearn e Chen (1997), foi admitido que cada um dos três processos possui limites de especificação superior e inferior coincidentes com os valores de máximos e de mínimos do processo, respectivamente, e valor nominal igual a  Os índices obtidos para cada uma das três distribuições são mostrados na Tabela 9.
Os índices obtidos para cada uma das três distribuições são mostrados na Tabela 9.
De um modo geral, observa-se que todos os índices da Tabela 9, com exceção do índice C'p e seu equivalente CNp, calculados para distribuições não-normais, conseguem quantificar bem a relação de capacidade dos processos. O processo representado pela distribuição Gama (15,100), que é o melhor dentre os três, possui capacidade maior em todos os índices, enquanto o processo representado pela distribuição Gamma (2,100) possui menor capacidade dentre os processos quanto aos índices calculados.
Comparando-se os índices C'pk e seu equivalente CNpk, e os índices C'pmk e seu equivalente CNpmk, que são os que diferem de um método para o outro, tem-se que, para todas as três distribuições, os valores dos índices C'pk e de seu equivalente CNpk apresentam, além das diferenças numéricas, diferenças de interpretações quanto à capacidade do processo. Enquanto C'pk avalia todos os três processos como potencialmente capazes, o índice CNpk informa que os processos não são potencialmente capazes com valores de índices abaixo de 1. Quanto aos índices C'pmk e CNpmk, também se notam valores mais altos para o primeiro índice que para o segundo nos três processos simulados.
Como os processos são assimétricos e não estão centrados (segundo a mediana) no valor nominal, tem-se que os índices propostos por Pearn e Chen (1997) conseguem quantificar melhor a capacidade do processo em relação aos índices propostos por Clements (1989), que considerou, por exemplo, o processo representado pela distribuição Gama (2,100) como potencialmente capaz segundo o índice C'pk quando se nota, apenas olhando para o histograma do processo, que grande parte dos itens produzidos encontra-se abaixo do valor nominal.
Para reforçar ainda mais que os índices propostos por Pearn e Chen (1997) são melhores que os índices propostos por Clements (1998), os próprios Pearn e Chen (1997) fizeram um estudo comparativo entre seus índices e os propostos por Clements (1998), calculando-os para diversos valores de mediana, com F99,865 e F0,135 fixos e com LIE = T - d, em que:  . Alguns desses valores foram reproduzidos na Tabela 10, e se nota que os índices de Pearn e Chen (1997) alcançam valor máximo quando a mediana é igual ao valor nominal e que os índices de Clements (1989) alcançam valor máximo quando o processo é assimétrico, com a mediana assumindo valor inferior ao valor nominal. Como a maioria dos processos produtivos tem por objetivo produzir itens em torno do valor nominal, os índices de Pearn e Chen (1997) conseguem quantificar melhor a capacidade do processo.
. Alguns desses valores foram reproduzidos na Tabela 10, e se nota que os índices de Pearn e Chen (1997) alcançam valor máximo quando a mediana é igual ao valor nominal e que os índices de Clements (1989) alcançam valor máximo quando o processo é assimétrico, com a mediana assumindo valor inferior ao valor nominal. Como a maioria dos processos produtivos tem por objetivo produzir itens em torno do valor nominal, os índices de Pearn e Chen (1997) conseguem quantificar melhor a capacidade do processo.
4.2 Aplicação dos métodos de análise de capacidade do processo não-normal
Neste estudo, são aplicados os três métodos de análise de capacidade do processo não-normal em dados coletados em uma metalúrgica da Grande Porto Alegre. Esses dados se referem à primeira medição de dureza de um processo produtivo de braços de direção para caminhões feitos em aço. Os valores são medidos por um equipamento chamado durômetro e são coletados após o processo de têmpera. A escala de medida é chamada escala brinell de dureza. O limite superior de especificação (LSE) desta primeira medição é de 595 brinell, o limite inferior de especificação (LIE) é de 415 brinell e o valor nominal (T) é igual a 505 brinell. Peças com valores de dureza fora dos limites de especificação voltam para uma etapa inicial do processo para que sejam retrabalhadas e peças dentro dos limites de especificação são enviadas para a etapa de revenimento, da qual seguem para mais uma etapa de medição. As peças dentro dos limites de especificação desta etapa final de medição são, então, liberadas para o cliente.
Para se conhecer melhor a etapa do processo produtivo utilizada neste estudo, são mostradas na Tabela 11 algumas estatísticas descritivas da medição de dureza.
Antes da aplicação dos três métodos de análise da capacidade do processo não-normal, é necessário verificar se os dados não apresentam distribuição normal. Para tanto, foram aplicados os testes de Shapiro-Wilk e Kolmogorov-Smirnov de normalidade nos dados. Por ambos os testes, a suposição de normalidade dos dados é rejeitada. Para o teste de Shapiro-Wilk, a estatística W obtida foi igual a 0,9535, com p-value = 7,37 x 10-13 e, com o teste de Kolmogorov-Smirnov, a rejeição da normalidade dos dados foi confirmada pelo valor da estatística D = 0,1046, com p-value = 3,717 x 10-6. Visualmente pode-se observar a não-normalidade dos dados através dos gráficos mostrados nas Figuras 3(a) e 3(b).
Observa-se na Tabela 12 que apesar dos índices tradicionais, utilizados para analisar a capacidade do processo com distribuição normal, captarem a falta de capacidade do processo, estes subestimaram a capacidade do processo, pois seus valores foram, em sua maioria, inferiores aos índices que tratam dados que apresentam distribuições não-normais, tanto através de capacidade potencial como dos índices de capacidade nominal. Cabe ressaltar que, em situações práticas, geralmente apenas um índice é adotado para a avaliação da capacidade de um processo e, dentre os métodos apresentados neste trabalho, a melhor escolha seria a do método 2 para a avaliação do processo, conforme mostrado anteriormente.
5 Considerações Finais
Quando a suposição de normalidade da variável de interesse não é atendida, a aplicação dos métodos de análise de capacidade de processos normais não é adequada, pois a estimação do percentual (ou PPM) de itens fora das especificações certamente não contempla a realidade, sendo necessária a aplicação de algum método de análise de capacidade de processo não-normal. Os erros obtidos com a suposição de normalidade para dados não-normais foram apresentados pelo estudo de Somerville e Montgomery (1996-97). Estes autores, ao estudarem as distribuições t, gamma, lognormal e Weibull quando estas têm um comportamento muito próximo da distribuição normal, verificaram diferenças nas estimativas do percentual (ou PPM) de itens fora das especificações, entre outras estatísticas.
Na comparação dos índices de capacidade não-normais feitas entre os índices propostos, os índices de Pearn e Chen (1997) indicam que estes são melhores que os propostos por Clements (1989), pois os índices CNpk e CNpmk consideram em seus cálculos a assimetria do processo. Além disto, no estudo de Pearn e Chen (1997) os índices alcançam valor máximo, para limites fixos, quando a mediana coincide com o valor nominal de especificação. Por outro lado, os índices de Clements (1989) apresentaram, no mesmo estudo, valor máximo quando a distribuição era nitidamente assimétrica, com mediana menor que o valor nominal.
Quanto ao estudo aplicado no processo de medição de dureza, cujas análises foram realizadas através do software livre R, com os valores dos índices obtidos ao se utilizarem os índices tradicionais para dados que apresentam distribuição não-normal, se conclui que estes tendem a subestimar a capacidade do processo. Neste caso aplicado, a capacidade do processo foi totalmente insatisfatória, tanto quando os índices tradicionais foram aplicados como quando o foram os índices adequados para tal situação.
Recebido em 17/5/2007
Aceito em 2/3/2009
- CHAN, L. K.; CHENG, S. W., SPIRING, F. A. A new measure of process capability: Cpm. Journal of Quality Technology, v. 20, n. 3, p. 162-75, 1988.
- CHEN, J. P. Re-evaluating the process capability indices for non-normal distributions. International Journal of Production Research, v. 38 n. 6, p. 1311-1324, 2000.
- CHEN, J. P.; DING, C. G. A new process capability index for non-normal distributions. The International Journal of Quality & Reliability Management, v. 18 n. 6-7, p. 762-770, 2001.
- CLEMENTS, J. A. Process capability calculations for non-normal distributions. Quality Progress, v. 22 n. 9, p. 95-100, 1989.
- DELERYD, M. The effect of Skewness on estimates of some process capability indices. International Journal of Applied Quality Management, v. 2, n. 2, p. 153-186, 1999.
- KANE, V. E. Process capability indices. Journal of Quality Technology, v. 18, n. 1, p. 41-52, 1986.
- MONTGOMERY, D. C. Introduction to statistical quality control 3 ed. New York: John Wiley & Sons, 1997.
- PEARN, W. L.; CHEN, K. S. Capability indices for non-normal distributions with an application in electrolytic capacitor manufacturing. Microelectronics Reliability, v. 37 n. 12, p. 1853-1858, 1997.
- SOMERVILLE, S. E.; MONTGOMERY, D. C. Process capability indices and non-normal distributions. Quality Engineering, v. 9, n. 2, p. 305-316, 1996-1997.
- VÄNNMAN, K. A unified approach to capability indices. Statistica Sinica, v. 5, n. 2, p. 805-820, 1995.
Datas de Publicação
-
Publicação nesta coleção
15 Abr 2009 -
Data do Fascículo
Mar 2009
Histórico
-
Aceito
02 Mar 2009 -
Recebido
17 Maio 2007