
Abstract
The production of penicillin G by Penicillium chrysogenum IFO 8644 was simulated employing a feedforward neural network with three layers. The neural network training procedure used an algorithm combining two procedures: random search and backpropagation. The results of this approach were very promising, and it was observed that the neural network was able to accurately describe the nonlinear behavior of the process. Besides, the results showed that this technique can be successfully applied to control process algorithms due to its long processing time and its flexibility in the incorporation of new data
Bioprocess; neural networks; modelling
A SIMULATION OF THE PENICILLIN G PRODUCTION BIOPROCESS APPLYING NEURAL NETWORKS
A.J.G. da Cruz, C.O. Hokka * * To whom correspondence should be addressed. and R.C. Giordano
Departamento de Engenharia Química - Universidade Federal de São Carlos - Caixa Postal 676
Via Washington Luiz, km 235 - 13565-905 São Carlos, SP - Brazil
Fone: 55 16 274-8264 - Fax: 55 16 274-8266
e-mail: hokka@power.ufscar.br
(Received:June 11, 1997; Accepted: October 30, 1997)
Abstract - The production of penicillin G by Penicillium chrysogenum IFO 8644 was simulated employing a feedforward neural network with three layers. The neural network training procedure used an algorithm combining two procedures: random search and backpropagation. The results of this approach were very promising, and it was observed that the neural network was able to accurately describe the nonlinear behavior of the process. Besides, the results showed that this technique can be successfully applied to control process algorithms due to its long processing time and its flexibility in the incorporation of new data.
Keywords: Bioprocess, neural networks, modelling.
INTRODUCTION
The penicillin G production bioprocess is carried out with strains of Penicillium chrysogenum, a strictly aerobic fungus, usually in stirred and aerated semibatch reactors. One aspect that deserves special attention is the oxygen mass transfer resistance, that imposes high impeller rotations in order to maintain productivity at satisfactory levels when the hyphae grow and the apparent viscosity in the liquid phase increases. The phenomenological modelling for this process was developed by Cruz et al. (1995) and is based on many simplifying assumptions and leads to the problem of optimization of a large number of parameters. As a consequence of the strongly nonlinear characteristics of this process, many different alternative approaches have been proposed to overcome this problem, including the neural network approach.
The first work on neural networks by McCullogh and Pitts dates back to the 1940s (Widrow and Lehr, 1990). Many others researchers have studied this subject and many different neuron models have been proposed. The motivation to study this subject comes from the fact that the human brain is much better than digital computers. Thus, as a trial, brain working principles are put into use in the design of practical systems. A good overview of this subject was written by Widrow and Lehr (1990).
Rumelhart et al. (1986) published their landmark books on parallel distributed processing, establishing the feedforward layered network and the backpropagation algorithm as the major paradigm in the field and arousing new interest in this approach. Since then many different algorithms such as the random search procedure proposed by Di Massimo et al. (1992) and the combined algorithm (Cruz, 1996) which uses the two procedures mentioned above, have been proposed for neural network training.
Di Massimo et al. (1992) investigated the development of biosensors, using neural networks to estimate cell and penicillin concentration for on-line application to an industrial fermentation.
In this work we explore the use and the viability of this technique to infer off-line assay information using available on-line information.
A feedforward neural network was developed to simulate this process, employing a phenomenological model (Cruz et al., 1995) to generate the data base and the combined algorithm (Cruz, 1996) in the neural network training.
THEORETICAL BASIS
Data Base
The phenomenological model used to develop the data base was described by Cruz et al. (1995) and takes into account the agitation speed effect on process productivity. The data simulated and the initial conditions are listed in Table 1 for the strain P. chrysogenum IFO 8644.
In the experimental runs employed to fit the phenomenological model, air flow rate (Qair) was measured using a flowmeter, dissolved oxygen concentration (CL) by a galvanic probe, mass concentration (Cx) by dry matter, substrate concentration (Cs) by the enzymatic GOD-PAP method following acid hydrolysis and product concentration by an agar diffusion bioassay, as described by Fonseca et al. (1992).
Aiming to give a realistic aspect to the data base, a noise was simulated in the data obtained from the phenomenological model. Standard deviations equal to 10 % for Cx, Cs, CL, Cp and Qair, and 2% for agitation speed (N) were accepted. The values were obtained employing equation (1):
(1)
where y is the "experimental" variable; s is the standard deviation; x is the random number, between 0 and 1, generated by the RAN1 function (Press et al., 1986), (corresponding to the probability of error, e y, occurrence; and the e y(x) variable from the GASDEV function (Press et al., 1986), which calculates the inverse normal distribution for a predefined variance.
Neural Network
A feedforward neural network with three layers (one input, one hidden and one output) was employed. The hidden layer had seven neurons (Figure 1). The output layer estimated the cellular, substrate and product concentrations.
The aim of this algorithm is to infer variables not measured on-line. Therefore, the input vector includes the substrate and product concentration with a six hour delay (enough time for its experimental measurement). The values of the variables measured on-line, such as air flow rate, agitation speed and oxygen concentration, are taken as the actual values.
The combined algorithm was used to train the neural network. Equation 2 describes the objective function employed in the algorithm. The cross-validation criterion (Pollard et al., 1992) was used to determine the number of presentations during the training phase, using the complete data base to calculate the objective function (equation 3) where 200 presentations were made.
(2)
y output value in the neural network
d desired value, from the data base
n number of sets from the data base employed in the training phase
m output numbers of the neural network
(3)
s total number of sets from the data base
Figure 1: Neural network architecture employed to simulate the penicillin G bioprocess production (where p is the present time p-6 is the time six hour before). The hidden layer had seven neurons.
RESULTS AND DISCUSSION
The initial conditions employed in the simulation with the neural network are shown in Table 2.
Figure 2 shows the simulation of a data set obtained directly from the phenomenological model without noise. A good fit was observed for a data set not employed in the training data base. Figure 3 illustrates the cross-validation criterion used to define the optimum number of presentations during the training phase. As can be observed, using this criterion, 200 presentations should be the proper number to avoid overfitting, which is evident by observing the results obtained for more than 300 presentations. This technique is used to control the amount of noise that is learned by the neural network, by limiting the number of presentations in the training phase.
Figure 4 exhibits the results from run 2, which includes an artificial noise generated according to the methodology described above. Mention should be made here that the conditions in this data set were not used for the network training.
We can see that the neural network captured the process dynamics satisfactorily.
Figure 5 illustrates the results obtained for the data set outside the cellular concentration limits (Table 2).
Variance between the phenomenological model and the" experimental" data (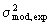 ), and variance between" experimental and neural network data (
), and variance between" experimental and neural network data (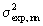 ) for run 2 cellular concentration were calculated by equation 4. As a consequence of the methodology employed here, one can interpret the phenomenological model results as the output of a perfect filter. So, it is expected that if the neural network acts as a high performance filter, is of the same order of magnitude as . In the case of much less than , overfitting shall occur. In the opposite form, poor fitting takes place. Table 3 shows the values obtained. These results illustrate the networks capability of filtrating, under certain limitations, occasional experimental errors.
) for run 2 cellular concentration were calculated by equation 4. As a consequence of the methodology employed here, one can interpret the phenomenological model results as the output of a perfect filter. So, it is expected that if the neural network acts as a high performance filter, is of the same order of magnitude as . In the case of much less than , overfitting shall occur. In the opposite form, poor fitting takes place. Table 3 shows the values obtained. These results illustrate the networks capability of filtrating, under certain limitations, occasional experimental errors.
(4)
where n is the number of variables.

Figure 2: Neural network results for the data set without noise.
Figure 3: Cross-validation approach (Pollard et al., 1992) employing the noise data base.
Figure 4: Simulation employing neural network with data set not included in the data base (interpolation) - run 2: (- ) prediction with phenomenological model; (--) prediction with neural network.
Figure 5: Simulation using neural networks with data set outside the data base (extrapolation).
CONCLUSION
The results showed that the neural network was able to learn the dynamic behavior of this process and perform inter and extrapolations of the data base. The cross-validation criterion was shown to be efficient in the determination of the number of presentations in the neural network training phase, overcoming the overfitting problems which appear when a data base with noise or experimental data are used.
The good results obtained with this approach suggest that it can be a valuable tool to be used in other applications, such as the fault detection, optimization and control of penicillin production.
ACKNOWLEDGMENTS
A. J. G. Cruz acknowledges the financial support received from CNPq in the form of a scholarship.
NOMENCLATURE
CL Dissolved oxygen concentration, g/L
Cp Product concentration, g/L
Cs Substrate concentration, g/L
Cx Microorganism concentration, g/L
d Desired value obtained from data base
m Output number in the neural network
n Number of data sets employed in the training phase
N Agitation speed, rpm
Qair Air flow rate, L/min
s Standard deviation or total number of data sets
y Experimental variable or neural output value
e y Variable from the GASDEV function
REFERENCES
Cruz, A.J.G.; Giordano, R.C. and Hokka, C.O., Fed-batch Penicillin Bioreactor Modeling: Effect of Shear Forces on Process Kinetics. Brazilian Journal of Chemical Engineering, 12(4):218-227 (1995).
Cruz, A.J.G., Modelagem Fenomenológica e Simulação por Redes Neuronais do Bioprocesso de Produção da Penicilina G. Masters thesis, Universidade Federal de São Carlos (1996).
Di Massimo, C.; Montague, G.A; Willis, M.J.; Tham, M.T. and Morris, A.J., Towards Improved Penicillin Fermentation Via Artificial Neural Networks. Computers & Chemical Engineering, 16(4):283-291 (1992).
Fonseca, V.V.; Suazo, C.A.T. and Hokka, C.O., Influência da Agitação na Produção de Penicilina-G em Reator Convencional. Anais do 9o Congresso Brasileiro de Engenharia Química (IX COBEQ), Salvador, Bahia, 2, 442-448 (1992).
Pollard, J.F.; Broussard, M.R.; Garrison, D.B. and San, K.Y., Process Identification Using Neural Networks. Computers & Chemical Engineering, 16(4):253-270 (1992).
Press, W.H.; Flannery, B.P.; Teukolsky, S.A. and Vetterling, W.T., Numerical Recipes: The Art of Scientific Computing. Cambridge University Press, Cambridge (1986).
Rumelhart, D.E.; McClelland, J.L. and the PDP Research Group., Parallel Distributed Processing: Explorations in the Microstructure of Cognition. vol. I, cap. 8, MIT, Cambridge, Mass. (1986).
Widrow, B. and Lehr, M.A., 30 Years of Adaptive Neural Networks: Perceptron, Madaline, and Backpropagation. Proceedings of the IEEE, 78(9):1415-1442 (1990).
- Cruz, A.J.G.; Giordano, R.C. and Hokka, C.O., Fed-batch Penicillin Bioreactor Modeling: Effect of Shear Forces on Process Kinetics. Brazilian Journal of Chemical Engineering, 12(4):218-227 (1995).
- Cruz, A.J.G., Modelagem Fenomenológica e Simulaçăo por Redes Neuronais do Bioprocesso de Produçăo da Penicilina G. Masters thesis, Universidade Federal de Săo Carlos (1996).
- Fonseca, V.V.; Suazo, C.A.T. and Hokka, C.O., Influęncia da Agitaçăo na Produçăo de Penicilina-G em Reator Convencional. Anais do 9o Congresso Brasileiro de Engenharia Química (IX COBEQ), Salvador, Bahia, 2, 442-448 (1992).
- Press, W.H.; Flannery, B.P.; Teukolsky, S.A. and Vetterling, W.T., Numerical Recipes: The Art of Scientific Computing. Cambridge University Press, Cambridge (1986).
- Rumelhart, D.E.; McClelland, J.L. and the PDP Research Group., Parallel Distributed Processing: Explorations in the Microstructure of Cognition. vol. I, cap. 8, MIT, Cambridge, Mass. (1986).
- Widrow, B. and Lehr, M.A., 30 Years of Adaptive Neural Networks: Perceptron, Madaline, and Backpropagation. Proceedings of the IEEE, 78(9):1415-1442 (1990).
Publication Dates
-
Publication in this collection
06 Oct 1998 -
Date of issue
Dec 1997
History
-
Accepted
30 Oct 1997 -
Received
11 June 1997






 (g/L)
(g/L) (g/L)
(g/L)