Abstracts
Western music is predominantly based on the equal temperament with a constant semitone frequency ratio of 21/12. Although this temperament has been in use since the nineteenth century and in spite of its high degree of symmetry, various musicians have repeatedly expressed their discomfort with the harmonicity of certain intervals. Recently it was suggested that this problem can be overcome by introducing a modified temperament with a constant but slightly increased frequency ratio. In this paper we confirm this conjecture quantitatively. Using entropy as a measure for harmonicity, we show numerically that the harmonic optimum is in fact obtained for frequency ratios slightly larger than 21/12. This suggests that the equal temperament should be replaced by a harmonized stretched temperament as a new standard.
Keywords:
music theory; equal temperament; stretched octaves; entropy-based tuning
A música ocidental é predominantemente baseada no temperamento igual, com uma razão constante 21/12 das frequências de semitom. Embora esse temperamento tenha sido usado desde o século dezenove, e apesar de seu alto grau de simetria, vários músicos têm repetidamente manifestado o seu desconforto com a harmonicidade de certos intervalos. Recentemente, foi sugerido que este problema pode ser superado através da introdução de um temperamento modificado, com uma razão de frequências constante, mas ligeiramente maior. Neste trabalho confirmamos qualitativamente esta conjectura. Usando a entropia como uma medida para a harmonicidade, mostramos numericamente que o harmônico ótimo é de fato obtido para razões de frequências ligeiramente maiores do que 21/12. Isto sugere que o temperamento igual deve ser substituído por um temperamento harmonicamente estendido, que se transformaria em novo padrão.
Palavras-chave:
teoria musica; temperamento igual; oitavas estendidas; afinação baseada na entropia
1. Introduction
Musical intervals between two tones are perceived as harmonic if the corresponding frequencies are related by simple fractional ratios [1[1] see e.g.: E. Prout, Harmony: Its Theory and Practice (Augener & Co., London, 1903).]. For example, the perfect fifth and the perfect fourth corresponds to the frequency ratios ƒ1 but also involves a large number higher partials (overtones) at integer multiple frequencies ƒn = nƒ1. Our sense of hearing is capable to detect matching partials, signaling us the impression of consonance and harmony. In other words, perceiving a perfect fifth as consonant does not mean that our ears like the numerical value Fig. 1). and , it rather reflects the circumstance that the third partial of the lower tone coincides with the second of the upper (see
and , it rather reflects the circumstance that the third partial of the lower tone coincides with the second of the upper (see  . Our ability to Our ability to hear and identify such fractional frequency ratios is related to the fact that the natural spectrum of musical sounds consists not only of the fundamental frequency
. Our ability to Our ability to hear and identify such fractional frequency ratios is related to the fact that the natural spectrum of musical sounds consists not only of the fundamental frequency
A musical scale is a periodic system of notes ordered by increasing fundamental frequency. The Western chromatic scale, on which we will focus in the present work, consists of twelve semitones per octave. As a musical scale is constructed in repeating patterns of intervals, it is always exponentially organized in the frequencies. For example, in the chromatic scale the frequency doubles from octave to octave. Aiming for a harmonic perception, musical scales are tuned in such a way that the fundamental frequencies capture or at least approximate simple fractional frequency ratios. However, in setting up such a tuning scheme one is immediately confronted with the problem that the exponential structure of the scale and the linear organization of the partials are incommensurable.
Harmonicity of a trichord. Playing a C-Major trichord (C-E-G-C) one generates four series of partials which are shown above the keyboard at the corresponding positions. Note that neighboring partials have a constant frequency difference while neighboring keys on the keyboard are characterized by a constant frequency ratio. This explains why the distance between the partials decreases as we go to the right, demonstrating the mathematical incommensurability of the exponential scale and the linear partial series. The trichord is perceived as harmonic because various partials match, as indicated by the arrows. The large green arrows stand for perfect matching due to pure octaves. In the standard equal temperament, on which this figure is based, there are also various approximate coincidences, as marked by the smaller gray arrows.
The probably most natural example of such a tuning system is the just intonation, where all intervals are built on simple fractional ratios with respect to a certain reference key. Music played in this reference key sounds very harmonic if not even sterile, but when played in a different key the same piece can be terribly out of tune. With the increasing complexity of music, however, frequent key changes became more important. Historically this led to the fascinating development of so-called temperaments[2[2] J.M. Barbour, Tuning and Temperament: A Historical Survey (Michigan State College Press, East Lansing, 1951).], i.e. tuning systems seeking for a reasonable compromise between harmonicity and invariance under transposition, attempting to reconcile the exponential structure of the scale with the linear organization of the partials. This development culminated in the so-called equal temperament (ET) with a constant semitone ratio of 21/12. This temperament is perfectly invariant under key changes, but except for the octave all intervals are out of perfect tune. The ET is the standard temperament of Western music and has been in use since the beginning of the 19th century.
Despite the high degree of symmetry, some musicians continue to express their concern about certain intervals in the ET which exhibit unpleasant beats. This discontent may have contributed to the revival of historical temperaments, accompanied by a subculture of newly invented unequal temperaments, but with all these approaches the main achievement of the ET, namely its beautiful key invariance, is lost.
Is it possible to improve the chromatic ET without destroying its symmetry under key changes? As we will see in the present work, this is indeed possible. To understand the basic idea let us recall that the standard ET is determined by three conditions, namely, (i) its exponential structure of constant semitone intervals, (ii) twelve semitones per octave, and (iii) the obvious condition that the frequency should double on each octave. This means that the octave, the simplest and most fundamental of all intervals, is the only pure one in the ET, producing a static sound without any beats. But why? As we are ready to tolerate beats for any other interval, why not for octaves? By allowing the octave to exhibit beats, would it be possible to arrive at a more balanced temperament? In the past few decades there have been several proposals to study stretched equal temperaments. In these temperaments the semitone frequency ratio is still constant but slightly larger than 21/12. To my knowledge the first example of this kind was the StopperTM tuning scheme introduced by B. Stopper in 1988, which favors a pure duodecime consisting of 19 semitones instead of the octave [3[3] B. Stopper (1988) [http://www.piano-stopper.de/html/onlypure_tuning.html].
http://www.piano-stopper.de/html/onlypur...
]. In 1995 a similar suggestion based on a perfect fifth was put forward by S. Cordier and K. Gillessen [4[4] S. Cordier, Equal Temperament with Perfect Fifths, paper presented at the International Symposium on Musical Acoustics, Dourdan, France (1995).
[5] K. Gillessen, J. Acoust. Soc. Am. 105, 3123 (1998).-6[6] K. Gillessen, Galpin Soc. J. 53, 312 (2000). [http://www.jstor.org/stable/842330].
http://www.jstor.org/stable/842330...
], who argued that in practice such temperaments would be already in use. More recently A. Capurso suggested what is known as the circular harmonic system (c.ha.sTM) [7[7] A. Capurso, Quaderni di Ricerca in Didattica 19, 58 (2009).,8[8] N. Chirano, Harmonious proportions in a pianoforte - The C.Ha.S.™ temperament, available at http://www.pdf-archive.com/2013/04/10/chas-prof-chiriano-english/preview/page/1/.
http://www.pdf-archive.com/2013/04/10/ch...
], where all intervals exhibit beats. All these proposed chromatic temperaments belong to the same family in so far as they are perfectly equal, differing only in their semi-tone frequency ratio. However, while Stopper and Cordier simply replace the constraint of one pure interval by another, the c.ha.s temperament is based on a more complex reasoning and seeks for an optimal balance in a regime where none of the intervals is pure. Which of these temperaments establishes the best harmonic compromise? In this paper we would like to address this question quantitatively. To this end we apply the concept of entropy as a measure for the harmonicity of a temperament. In statistical physics and information theory, entropy is known to quantify the degree of disorder in a data set. In Ref. [10[10] H. Hinrichsen, Revista Brasileira de Ensino de Física 34, 2301 (2012), reprinted in: Europiano 2012/4.] we observed that the entropy of pure (harmonic) intervals is locally minimal since the entropy decreases when higher partials overlap. This suggests that the entropy of overlaid power spectra can be used as a measure of harmonicity. Very recently we were able to demonstrate that this concept can even be used for piano tuning [11[11] C. Wick and H. Hinrichsen, Entropy-Piano-Tuner, open-source software [http://piano-tuner.org].
http://piano-tuner.org...
]. Therefore, the obvious question would be what entropy can tell us about different stretched equal temperaments.
In order to address this question, we generate artificial harmonic power spectra for various temperaments and compute the corresponding entropy numerically. As we will see below, our results confirm that the standard equal temperament has to be replaced by a stretched one and also suggests a range for the possible optimum.
It is very important to realize that stretched temperaments must not be confused with the concept of "stretched tuning" in the context of piano tuning which is a completely different story. In pianos, the stiffness of strings causes a deformation of the harmonic spectrum, known as inharmonicity, which is compensated in the tuning process by imposing a stretched tuning curve. Contrarily, in the present work we discuss an intrinsic stretch of the temperament itself on the basis of perfectly harmonic sounds (iH=0).
The paper is organized as follows. In the next section various definitions and notations are introduced. The third section discusses the existing stretched ETs in more detail. After reviewing the concept of entropy in Sect. 4, the model for generating harmonic power spectra is introduced in Sect. 5. Finally, the numerical results are presented in Sect. 6, followed by a simple visual interpretation of the results.
2. Definitions and notations
2.1. Power spectra
Tones generated by musical instruments are composed of many Fourier components, called partials. The partials are enumerated by an index n = 1, 2,... with associated frequencies ƒn in ascending order, where the lowest frequency ƒ1 is referred to as the fundamental frequency of the tone.
The power spectral density of a tone is defined as P (ƒ)= |ψ̃(ƒ)|2, where ψ̃(ƒ) is the Fourier transform of the sound wave ψ(t). In the power spectrum the partials appear as peaks whose area Pn is the power of the nth partial. The total power is then given by

Typically the power of the nth peak Pn varies with increasing n and eventually goes to zero so that the number of partials contributing to the sound is essentially finite [12[12] D.M. Koenig and D.D. Fandrich, Spectral Analysis of Musical Sounds with Emphasis on the Piano (Oxford University Press, Oxford, 2015).].
As in the Heisenberg energy-time uncertainty relation, the width of the peaks is inversely proportional to the temporal duration of the sound. In the limit of an infinitely long-lasting tone one obtains an idealized spectrum with infinitely sharp peaks of the form
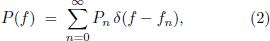
where δ denotes the Dirac delta function.
2.2. Harmonic spectra and pure intervals
A tone is called perfectly harmonic if the frequencies of the partials are exactly given by integer multiples of the fundamental frequency:

This means that perfectly harmonic sound are exactly periodic in the fundamental frequency ƒ1, causing a clean and static sound.
The linear law (3) holds only for ideal oscillators such as infinitely flexible strings. Realistic oscillators in musical instruments such as piano strings are of course not perfectly harmonic. In the present work, however, we will neglect this instrument-dependent imperfectness, restricting ourselves to the ideal case of perfectly harmonic spectra of the form (3).
An interval between two fundamental frequencies ƒ1 and ƒ1, is called pure if some of the corresponding higher partials coincide, meaning that there exist integers n, m ∈ ℕ such that ƒn= ƒ'm. In the case of ideal harmonic oscillators the fundamental frequencies of a pure interval are therefore related by a rational number:

Since these coincidences appear periodically in frequency space, the perception of harmonicity is particularly intense if n and m are small. Examples are the pure octave (2:1), the perfect fifth (3:2), and the perfect fourth (4:3).
2.3. Temperaments
Let us consider a chromatic scale of K semitones with the fundamental frequencies ƒ1(k) enumerated by k =1 ...K. The set of all frequencies ƒ1(k) with respect to a reference tone (usually A4 = 440 Hz) isreferred to as the temperament of the musical scale.
A temperament is called equal if the frequency ratios of all intervals are invariant under transposition (translational shifts along the keyboard), i.e.,
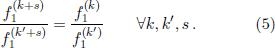
Obviously this requires all semitone intervals
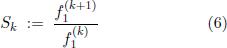
to be constant.
The standard twelve-tone equal temperament (ET), which was originally invented in ancient China [13[13] G. Jinsiong Cho, The Discovery of Musical Equal Temperament in China and Europe in the Sixteenth Century (Edwin Mellen Press, Lewiston, 2003).] and rediscovered in Europe in the 18th century, is determined by two additional conditions. Firstly the octave is divided into twelve semitones. Secondly the octave, the most fundamental of all intervals, is postulated to be pure (beatless), as described by the frequency ratio 2:1. These two conditions unambiguously imply that the constant semitone frequency ratio is given by S = 21/12. Defining a reference tone with the index kref, for example A4 with the frequency ƒref = ƒ1(kref) = 440 Hz, the standard ET is therefore defined by
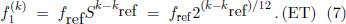
2.4. Pitches
Since intervals are defined by frequency ratios rather than differences, they give rise to a multiplicative structure in the frequency space. It is therefore meaningful and convenient to consider the logarithm of the frequencies, mapping it to an additive structure. In music theory this is done by defining the so-called pitch
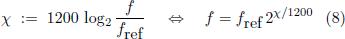
with respect to a given reference frequency ƒref, where log2 z = ln z/ ln2 denotes the logarithm to base 2. With this definition it is possible to translate frequency ratios into pitch differences. In music theory such pitch differences are usually measured in cents (¢), defined as 1/100 of a semitone in the standard ET. Therefore, in terms of pitch variablesthe ET is simply given as
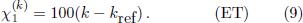
With pitches it is possible to specify interval sizes conveniently in cents. For example, the perfect fifth has a size of 1200 log2 ≈ 701.955¢, which is slightly larger than the fifth in the standard ET with a size of exactly 700¢.
When going from frequencies to pitches, the power spectral density P(ƒ) has to be recast as a spectral density P (χ) in terms of the pitch variable by means of the transformation
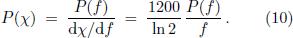
If we apply this transformation to the idealized peaked spectrum in Eq. (2) we find that formally the same expression holds for the pitch variables aswell, namely
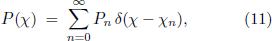
3. Stretched equal temperaments
In what follows we consider equal chromatic temperaments of the form

where the semitone ratio S is constant but slightly different from 21/12, meaning that the semitone interval size deviates marginally from 100¢. This deviation, measured in units of cents, will be denoted by ∈, i.e., we consider equal temperaments with the semitone pitch difference
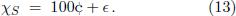
The corresponding frequencies and pitches of these modified temperaments are given by
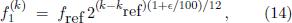
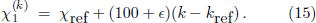
Here ∈ is a free parameter which quantifies the stretch or quench of the temperament relative to the standard ET. As we will see, the stretch parameter ∈ is of the order of a few hundredths cents. Therefore, as a convenient notation for what follows, we shall denote by ETx a stretched equal temperament with a semitone stretch of ∈ = 0 is just the standard equal temperament while ET50 would denote a stretched equal temperament with ∈ = 0.05¢ or 50 millicents. Since stretch differences of less than a millicent would not be audible, the resolution in terms of millicents is more than sufficient.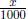 ¢. For example, ET
¢. For example, ET
The class of stretched 12-tone ETs comprises several special cases, as will be discussed in the following.
3.1. Special cases
The StopperTM equal temperament [3[3] B. Stopper (1988) [http://www.piano-stopper.de/html/onlypure_tuning.html].
http://www.piano-stopper.de/html/onlypur...
] replaces the constraint of pure octaves by pure duodecimes, meaning that S19 = 3. This corresponds to taking
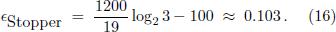
The stretch of the Cordier equal temperament [4[4] S. Cordier, Equal Temperament with Perfect Fifths, paper presented at the International Symposium on Musical Acoustics, Dourdan, France (1995).], which postulates perfect fifths, is even higher, namely
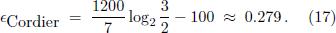
Finally, in the c.ha.sTM equal temperament the semitone ratio is defined by the implicit equation [7[7] A. Capurso, Quaderni di Ricerca in Didattica 19, 58 (2009).,8[8] N. Chirano, Harmonious proportions in a pianoforte - The C.Ha.S.™ temperament, available at http://www.pdf-archive.com/2013/04/10/chas-prof-chiriano-english/preview/page/1/.
http://www.pdf-archive.com/2013/04/10/ch...
]
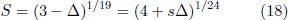
with two construction-specific parameters s and Δ, where the special case of c.ha.s corresponds to setting s = 1. Solving this equation one obtains Δ ≈ 0.0213, corresponding to the stretch parameter
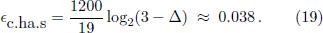
All these temperaments, which are summarized in Table 1, are strictly equal in the sense that the semitone frequency ratio is constant. They belong to a whole continuum of possible stretched twelve-tone equal temperaments labeled by the parameter ∈.
4. Entropy as a harmonicity measure
4.1. Entropy detecting overlapping peaks
In statistical physics and information theory, the differential entropy of a normalized probability density p(χ) is defined as
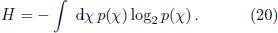
The entropy quantifies the information in units of bits that is required to specify a randomly chosen value of x according to the distribution p(x) in a given resolution. Thus the enropy of a strongly peaked distribution is low while a broad distribution has a high entropy. This can be demonstrated nicely in the example of a Gaussian distribution
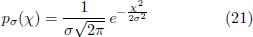
for which the entropy
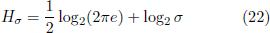
increases logarithmically with the standard deviation σ. But the entropy is not only able to quantify the peakedness of a distribution and its associated information content, even more important in the present context is its ability to detect overlapping peaks. As an example let us consider the sum of two normalized Gaussian peaks of width σ which are separated by the distance Δχ:
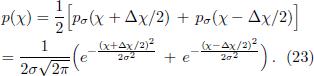
If the two peaks are sufficiently separated like in the upper left panel of Fig. 2, it is clear that the entropy will be independent of their distance Δχ. But as soon as the peaks begin to overlap the entropy decreases and becomes minimal for perfect coincidence Δχ = 0, as shown in the right panel of the figure. It is this property that allows entropy to detect overlapping partials as a signature of consonance and harmony.
Example illustrating how entropy responds to overlapping spectral peaks. The left figure shows a superposition of two peaks with a standard deviation of one cent. If the two peaks do not overlap the corresponding entropy is independent of their distance. However, as soon as the peaks begin to overlap the entropy decreases (see right panel) and becomes minimal for perfect coincidence. This property allows entropy to be used as a measure for the proximity of spectral lines in the power spectrum of sound waves.
4.2. Entropy applied to acoustic power spectra
As already outlined in the introduction, an interval is perceived as harmonic if the corresponding partials of the constituting tones coincide partially. Therefore, interpreting the normalized power spectrum as a probability density, it is plausible that the entropy will attain a local minimum for an optimal compromise of overlapping partials. More specifically, in order to compute the entropy we first have to determine the total power
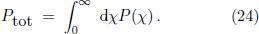
Defining the normalized power spectrum p(χ) = 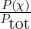 , the entropy associated with the sound wave is then given by
, the entropy associated with the sound wave is then given by
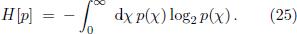
As one can see, in this approach the influence of the partials is automatically weighted by their power. Therefore, the entropy does not only detect overlapping partials but even assigns to them a different weight according to their intensity.
In the following section we are going to define a certain model for the composition of the power spectrum based on a given temperament. This model is then used to compute the entropy as a function of the parameter ∈. The goal is to find the value of ∈ for which the entropy becomes minimal, indicating the best compromise of overlapping partials and therewith the most harmonic temperament.
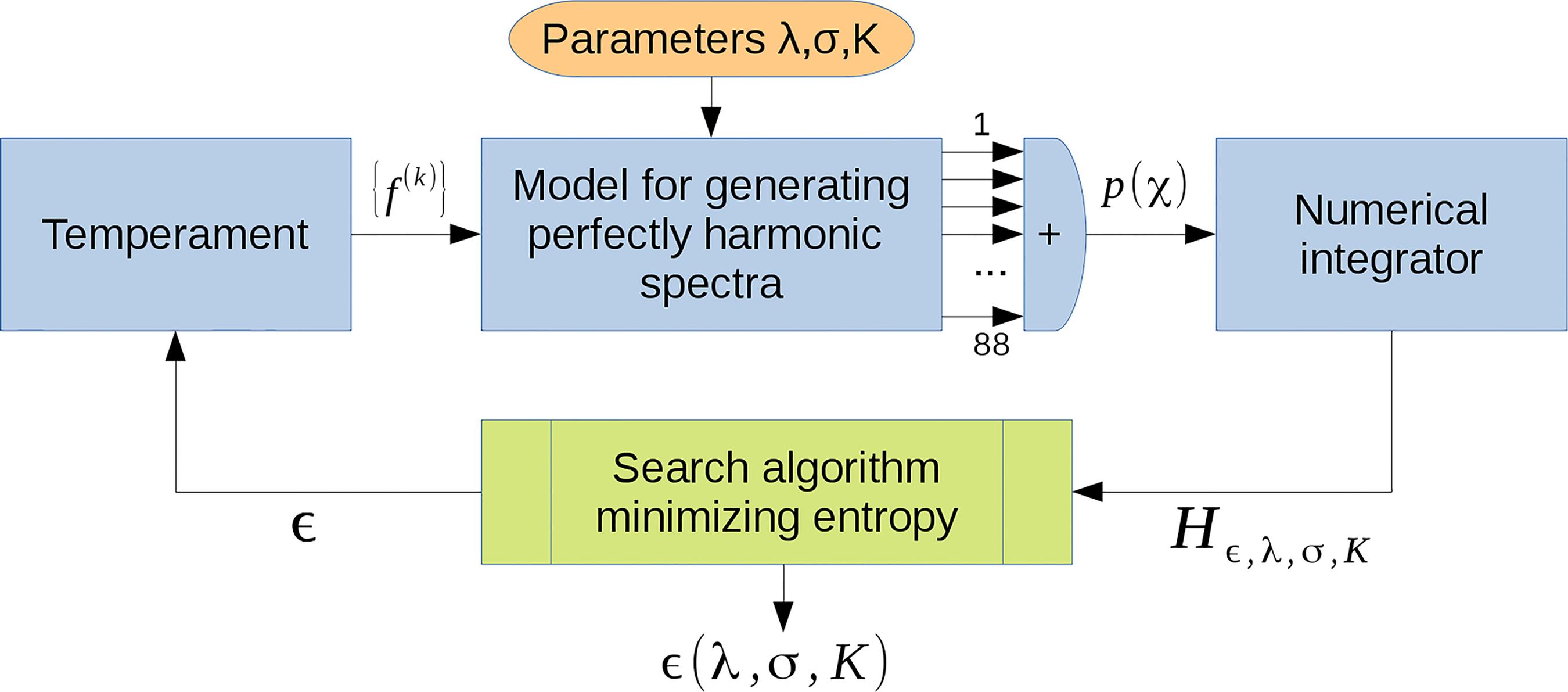
5. Definition of the model
In the analysis to be presented below we consider an artificial superposition of perfectly harmonic tones. In order to apply the concept of entropy, we need to make two assumptions:
-
We have to make a reasonable assumption about the power of the partials Pn(k). These coefficients determine the texture of a harmonic sound. In realistic situations the power can be distributed over dozens of partials and the coefficients may even vary with time [12[12] D.M. Koenig and D.D. Fandrich, Spectral Analysis of Musical Sounds with Emphasis on the Piano (Oxford University Press, Oxford, 2015).]. However, in order to keep the analysis as simple as possible we shall assume an exponential decrease of the form
where λ is a free parameter. This parameter controls the brilliance (overtone richness) of the sound waves. Roughly speaking λ can be interpreted as the index of the partial where the center of the cumulative power distribution is located.
-
The Dirac δ-peaks in Eq. (2) are infinitely focused, meaning that they never overlap. Thus, in order to apply the entropy criterion, we have to give them a finite width. To this end we convolve the spectrum with a normal distribution of constant width σ, obtaining the spectrum
The standard deviation σ in cents enters as another free parameter which expresses to what extent our sense of hearing is willing to tolerate deviations from pure intervals. Since the standard ET comes with deviations from pure tuning ranging from 2 to 16 cents, it is reasonable to choose σ as a constant in the same range.
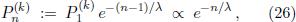
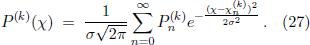
Finally we have to decide which of the tones we would like to compare. In order to avoid any preference the simplest choice is to compare all tones simultaneously, a concept which also turned out to be useful in the context of entropy-based tuning [10[10] H. Hinrichsen, Revista Brasileira de Ensino de Física 34, 2301 (2012), reprinted in: Europiano 2012/4.]. This means that we simply add up the power spectra of all K tones, as sketched in Fig. 3. The resulting power spectrum reads
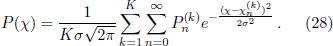
Artificially generated power spectra used in the present paper. The black lines represent perfectly harmonic power spectra of K = 88 tones (four of which are shown) with partials whose power decreases exponentially as e-n/4. The sum of all K tones is shown at the bottom in red color. This sum spectrum, which may be thought of as hearing all tones simultaneously, is used to compute the entropy.
Inserting Eq. (26) as well as the pitches of the har monics in the ∈-stretched temperament
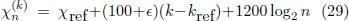
and dividing by the total power (24) we arrive at the normalized power spectrum
of which we will compute the entropy
This entropy depends on four parameters, namely, the stretch parameter ∈, the number of tones K, the overtone richness parameter λ, and the width of the spectral peaks σ. Note that kref and χref cancel out in the normalization so that the entropy does not depend on the overall pitch and the chosen reference key.
6. Numerical results
The integral (30)-(31) is not exactly solvable and thus it can only be calculated numerically. Moreover, the integrand is highly oscillatory so that ordinary integrators of algebraic computer systems are prone to fail. Therefore, we compute the integral by an ordinary Simpson integration in C++, discretizing the pitch χ in bins of 1/1000 cents.
For a first survey we consider a particular example which is shown in Fig. 4. In this example we chose K = 88 tones and the decay parameter λ = 10. The left panel shows the entropy as a function of ∈ for σ =0.5¢ which is much smaller than the tolerance of human hearing. In this case the entropy is minimal for ∈ = 0, which is just the standard ET. This result is plausible since for ∈ = 0 the octaves lock in and the entropy measure is so rigid that it does not like to depart from this point. However, as we increase the tolerance, e.g. by taking the realistic value σ =5¢ as in the right panel, we find as expected that the entropy changes less, but most strikingly there is a new minimum appearing at a non-vanishing value of ∈. This means that the corresponding stretched temperament should be more harmonic than the standard ET. The minimum is located at ∈ ≈ 0.05¢, somewhat larger than the value ∈ =0.038¢ predicted by the c.ha.s but significantly lower than the valuessuggested by Stopper and Cordier.
Entropy of the generalized temperament as a function of the parameter ∈ in units of millicents (K = 88 and λ = 10. For very small values of σ (left panel) the entropy is minimal in the standard equal temperament (ET), while for larger values of σ (right panel) the minimum (harmonic temperament, HT) is clearly found at a value ∈ > 0. The value is slightly larger than the one predicted in Ref. [7[7] A. Capurso, Quaderni di Ricerca in Didattica 19, 58 (2009).] (dashed line) but it is of the same order of magnitude.
 ¢) for
¢) for
As we have made various additional assumptions in our model expressed in terms of the parameters σ and λ, we have to analyze the robustness of this result. To this end we carried out a systematic scan over the whole range of λ and σ. For given values of these parameters we search for the value of ∈ where the entropy H becomes minimal, as sketched in Fig. 5. The result of this scan (see Fig. 6) can be interpreted as follows:
Systematic scan over the (λ, σ) parameter space for a scale with K = 88 tones. Both figures show the optimal value of parameter ∈, where the entropy becomes minimal, in units of millicents (mct). As can be seen, an extended plateau emerges where ∈ is rather insensitive to the parameters, indicating a high degree of robustness.
-
Parameter λ controlling the overtone richness: For λ = 0 (plain sine waves without higher partials) temperaments have no meaning. For small λ< 1 only the fundamental and the second partial contribute. For this reason octaves lock in so that the standard ET is favored. However, as λ increases so that more and more partials contribute, the minimum suddenly jumps to a highvalue of E ≈ 0.06¢. From here on the entropymethod clearly prefers a stretched temperament. This value is pretty stable until for very large λ > 6 one observes a gradual decrease, whereso many partials begin to contribute that themethod becomes unstable.
-
Parameter sigma controlling the peak width: For σ = 0 the method does not tolerate anybeats, hence the standard temperament with pure octaves provides a local minimum. As shown before, the situation changes suddenly when σ exceeds a threshold of about 2¢. Moreover, the figure shows that the optimal value of ∈ is quite stable as we increase σ even further. In other words, increasing our tolerance for pitch deviations does not lead to significantly different solutions for the optimal temperament.
The extended plateau shows that the two ad-hoc parameters, the spectral brilliance expressed by λ and the human pitch mismatch tolerance expressed by σ, have only little influence on ∈, suggesting that the result is stable and robust. On the plateau the optimal value of ∈ ranges roughly between 0.040¢ and 0.065¢.
Finally we studied the influence of the parameter K, the total number of semitones in the scale (not shown here). Taking K = 49 we basically find the same structure although the level of the plateau is somewhat lower, ranging approximately from 0.035¢ to 0.055¢, now including c.ha.s as a special case.
7. Visual interpretation
The results obtained in the previous section can be understood quite easily by visual inspection of the spectral sum. To this end we zoom the power spectrum in a small corridor around 880 Hz, corresponding to the tone A5 (highlighted as a small green rectangle in Fig. 3). In the left panel of Fig. 7 we demonstrate how the spectral lines around A5 depend on the stretch parameter ∈. Our observations can be summarized as follows:
Understanding the effect of stretching visually. Left panel: Variation of the spectral sum (31) near the fundamental frequency of A5 for various values of the stretch parameter ∈ (see legend). Upper right panel: Same data shown for spectral peaks with the standard deviation σ = 2.
-
In case of the equal temperament (red line at the bottom) the sound of A5 consists of five peaks. The peak at 880 Hz is the strongest one because it is made up of six contributions coming from A0,A1,...,A5 by means of pure octaves. Moreover, we observe four adjacent peaks on the right side which are generated by different interval combinations on the chromatic scale. Remarkably, these peaks are arranged in a totally asymmetric way, i.e., they are found exclusively on the right side of the fundamental peak.
-
Choosing a small value ∈ > 0 the octave symmetry is broken, lifting the degeneracy of the peaks. Increasing ∈ we finally arrive at a point of maximal symmetry at ∈ ≈ 0.05¢. At this point one has small peaks which are arranged symmetrically around 880 Hz.
-
Increasing the stretch parameter even further another interval is becoming pure, leading again to asymmetrically distributed degenerated peaks. This is just the Stopper temperament, favoring pure duodecimes.
The figure gives also an intuitive understanding why the stretched temperament for ∈ ≈ 0.05¢ is more harmonic and why the entropy is able to detect the harmonic optimum. This is demonstrated in the upper right panel, where the same data is shown for a broader peaks with the width σ = 2. As can be seen by bare eye, the green curve in the middle is the most symmetric and most focused one, making it plausible why entropy becomes minimal at this point.
8. Hearing the difference
Within a single octave the tiny stretch differences discussed in the present paper are so small that they are probably not audible. However, the situation is different for composite sounds extending over several octaves. Here the dependence on ∈ can be heard in the balance of beat frequencies of the partials.
As a simple example let us consider a particular chord based on C3, combined with two fifths C4- G4-C5-G5. In the standard ET the partials at C4 and C5 match perfectly without any beats while G4 and G5 differ slightly from the corresponding partials in the harmonic series of C3, exhibit 0.44 and 0.89 beats per second. In the stretched case these beat frequencies are reduced on the expense of the octave which starts to beat by itself. In the optimal range of c.ha.s and ET50 all these beats are balanced and well below 0.5 Hz. However, increasing ∈ even further the situation becomes again worse, as summarized in Table 2.
9. Conclusions
Using entropy as a measure of harmonicity we have provided numerical evidence that the standard equal temperament with semitone frequency ratio 21/12 does not represent the harmonic optimum, the optimum is rather obtained for a slightly larger frequency ratio. In such a stretched equal temperament the octave is no longer beatless but by tolerating slightly tempered octaves the beats of other intervals can be reduced, leading all in all to a more harmonic and balanced temperament. The proposed harmonized temperament (HT) is defined by
with a free parameter ∈ (see Eqs. (14)-(15)). De pending on the number of tones in the scale and the richness of partials the method of entropy minimization predicts values in the range
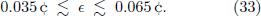
According to this result, the temperaments proposed by Stopper and Cordier can be ruled out as long as we restrict ourselves to perfectly harmonic sounds. The c.ha.sTM temperament (∈ =0.038 ¢), however, is consistent with the entropy method, indicating that c.ha.s is capturing the right idea, namely, to embrace all intervals as part of a whole and to look for the optimal order of beats. However, choosing the most plausible parameters the predicted optimal value for ∈ tends to be somewhat larger, roughly centered around

and it would be interesting to study where this discrepancy comes from. Let us again remind the reader that the predicted stretch ∈ has nothing to do with stretched tuning curves in the context of piano tuning. This would be an additional effect on top of the present one caused by the physical inharmonicity of piano strings. Contrarily, in the present study the semitone stretch ∈ is a property of the equal temperament itself, assuming perfectly harmonic spectra of partials. Nevertheless we expect our findings to be also relevant for piano tuning if inharmonicity is taken into account as an additional effect.
In conclusion our results call for replacing the equal temperament by a stretched equal temperament of the form (32) as a new standard for musical instruments with fixed frequencies.
An important open question would be the appropriate choice of the parameter ∈ for such a new standard. Would it be sufficient to choose a fixed value as a reasonable compromise for all purposes? Or do we have to keep ∈ as a free parameter varying in the range (33), chosen as a matter of taste? Careful empirical studies are needed in order to find out how much this parameter influences the perception of the temperament.
Acknowledgments
I am deeply grateful to Alfredo Capurso (Messina, Italy), creator of c.ha.s™ and renowned expert for tuning and temperaments, for his helpful comments and for carefully reading the manuscript before submission. I would also like to thank Isaac Oleg (Paris, France), who is internationally known as an innovative piano technician, for interesting discussions and for having me made aware of the problem addressed in this paper. Without both of them the present work would not exist.
Appendix
References
-
[1]see e.g.: E. Prout, Harmony: Its Theory and Practice (Augener & Co., London, 1903).
-
[2]J.M. Barbour, Tuning and Temperament: A Historical Survey (Michigan State College Press, East Lansing, 1951).
-
[3]B. Stopper (1988) [http://www.piano-stopper.de/html/onlypure_tuning.html].
» http://www.piano-stopper.de/html/onlypure_tuning.html -
[4]S. Cordier, Equal Temperament with Perfect Fifths, paper presented at the International Symposium on Musical Acoustics, Dourdan, France (1995).
-
[5]K. Gillessen, J. Acoust. Soc. Am. 105, 3123 (1998).
-
[6]K. Gillessen, Galpin Soc. J. 53, 312 (2000). [http://www.jstor.org/stable/842330].
» http://www.jstor.org/stable/842330 -
[7]A. Capurso, Quaderni di Ricerca in Didattica 19, 58 (2009).
-
[8]N. Chirano, Harmonious proportions in a pianoforte - The C.Ha.S.™ temperament, available at http://www.pdf-archive.com/2013/04/10/chas-prof-chiriano-english/preview/page/1/
» http://www.pdf-archive.com/2013/04/10/chas-prof-chiriano-english/preview/page/1/ -
[9]S. Hendry, Inharmonicity of Piano Strings, Master thesis, Univ. Edinburgh (2008), available at http://www.simonhendry.co.uk/wp/wp-content/uploads/2012/08/inharmonicity.pdf
» http://www.simonhendry.co.uk/wp/wp-content/uploads/2012/08/inharmonicity.pdf -
[10]H. Hinrichsen, Revista Brasileira de Ensino de Física 34, 2301 (2012), reprinted in: Europiano 2012/4.
-
[11]C. Wick and H. Hinrichsen, Entropy-Piano-Tuner, open-source software [http://piano-tuner.org].
» http://piano-tuner.org -
[12]D.M. Koenig and D.D. Fandrich, Spectral Analysis of Musical Sounds with Emphasis on the Piano (Oxford University Press, Oxford, 2015).
-
[13]G. Jinsiong Cho, The Discovery of Musical Equal Temperament in China and Europe in the Sixteenth Century (Edwin Mellen Press, Lewiston, 2003).
Publication Dates
-
Publication in this collection
Mar 2016
History
-
Received
25 Aug 2015 -
Accepted
30 Aug 2015