Abstract
The protein of Myc modulator 1 (Mm-1) has been reported to repress the transcriptional activity of the proto-oncogene c-Myc in humans. Moreover, it was shown to be the subunit 5 of human prefoldin (PFD). So far, this gene and its homologs have been isolated and sequenced in many organisms, such as mammals and fish, but has not been sequenced for any amphibian or reptile. In order to better understand the function and evolution of Mm-1, we isolated a full-length Mm-1 cDNA (BgMm-1, GenBank accession no. EF211947) from Bufo gargarizans (Cantor, 1842) using RACE (rapid amplification of cDNA ends) methods. Mm-1 in B. gargarizans is 755 bp long, comprising an open reading frame (ORF) of 459 bp encoding 152 amino acids. The amino acid sequence had a prefoldin α-like domain, partially including a typical putative leucine zipper motif. BgMm-1 showed high similarity to its homolog of Mus musculus Linnaeus, 1758 (82%) and Homo sapiens Linnaeus, 1758 MM-1 isoform a (81%) at the amino acid level. The protein secondary structure modeled with the SWISS MODEL server revealed that there were two α-helices and four b-strands in BgMm-1 as its human orthologue, and both proteins belonged to the a class of PFD family. The phylogenetic relationships of Mm-1s from lower archaea to high mammals was consistent with the evolution of species, meanwhile the cluster result was consistent with the multiple alignment and the sequence identity analysis. RT-PCR (reverse transcriptase-polymerase chain reaction) analysis demonstrated that BgMm-1 expressed widely in ten tissues of adult toad. These results can be helpful for the further investigation on the evolution of Mm-1.
PFD family; protein secondary structure
GENETICS
Molecular cloning and analysis of Myc modulator 1 (Mm-1) from Bufo gargarizans (Amphibia: Anura)
Ning Wang; Rui Jia; Jing J. Wang; Liu W. Nie1 1 Corresponding author. E-mail: lwnie@mail.ahnu.edu.cn
The Provincial Key Laboratory of the Conservation and Exploitation Research of Biological Resources in Anhui, College of Life Sciences, Anhui Normal University. Wuhu, 241000, Anhui, China
ABSTRACT
The protein of Myc modulator 1 (Mm-1) has been reported to repress the transcriptional activity of the proto-oncogene c-Myc in humans. Moreover, it was shown to be the subunit 5 of human prefoldin (PFD). So far, this gene and its homologs have been isolated and sequenced in many organisms, such as mammals and fish, but has not been sequenced for any amphibian or reptile. In order to better understand the function and evolution of Mm-1, we isolated a full-length Mm-1 cDNA (BgMm-1, GenBank accession no. EF211947) from Bufo gargarizans (Cantor, 1842) using RACE (rapid amplification of cDNA ends) methods. Mm-1 in B. gargarizans is 755 bp long, comprising an open reading frame (ORF) of 459 bp encoding 152 amino acids. The amino acid sequence had a prefoldin α-like domain, partially including a typical putative leucine zipper motif. BgMm-1 showed high similarity to its homolog of Mus musculus Linnaeus, 1758 (82%) and Homo sapiens Linnaeus, 1758 MM-1 isoform a (81%) at the amino acid level. The protein secondary structure modeled with the SWISS MODEL server revealed that there were two α-helices and four b-strands in BgMm-1 as its human orthologue, and both proteins belonged to the a class of PFD family. The phylogenetic relationships of Mm-1s from lower archaea to high mammals was consistent with the evolution of species, meanwhile the cluster result was consistent with the multiple alignment and the sequence identity analysis. RT-PCR (reverse transcriptase-polymerase chain reaction) analysis demonstrated that BgMm-1 expressed widely in ten tissues of adult toad. These results can be helpful for the further investigation on the evolution of Mm-1.
Key words: PFD family; protein secondary structure.
Mm-1, a novel c-Myc-binding protein, was first isolated using the yeast two-hybrid screening of a human Hela cell cDNA library (MORI et al. 1998). Mm-1 mRNA expresses in a variety of adult mouse tissues, with especially high expression levels in the brain and testis. It has been reported to repress the E-box-dependent transcriptional activity of c-Myc by recruiting histone deacetylase (HDAC) complex via TIF1 β/KAP1 (transcriptional intermediary factor 1 β/KRAB domain-associated protein 1) (FUJIOKA et al. 2001, SATOU et al. 2001). FUJIOKA et al. (2001) confirmed that Mm-1 was a candidate for a tumor suppressor in leukemia/lymphoma and tongue cancer that controls the transcriptional activity of c-Myc.
C-Myc is a member of Myc oncogene family, which includes three known members: cell-myc (c-Myc), human-myc (N-Myc) and myc-related-gene (L-Myc) (ALT et al. 1986, DEPINHO et al. 1987, CHEN 2000). The protein products of these three oncogenes are transcription factors that play a role in cell proliferation, apoptosis and in the development of human tumors (ZAJAC-KAYE 2001). Among them, c-Myc activates or represses the expression of genes that are thought to play roles in cell cycle progression, apoptosis induction, or metabolism, and misregulation of genes by c-Myc leads to cell transformation or tumorigenesis (SATOU et al. 2001). It is thought to be one of the most frequently activated oncogenes and is estimated to be involved in 20% of all human cancers (DANG et al. 2006). Therefore, the study of Mm-1 can provide a new path for therapy of cancer.
Mm-1 can alternatively termed prefoldin 5 (prefoldin subunit 5ÿPfd5) or Gim5 (genes involved in microtubule biogenesis protein 5 ÿin human (INAZU et al. 2005, VAINBERG et al. 1998, MARTIN-BENITO et al. 2007). It was reported that Pfd5/Gim5 functions well in the correct folding of newly synthesized polypeptides in eukaryotic cells. During this process, it is one of the subunits of PFD, which is a heterohexameric protein that binds and stabilizes newly synthesized polypeptides and transfer them to CCT (chaperonin containing TCP-1) for the final correct folding and/or assembly (MARTIN-BENITO et al. 2002, HANSEN et al. 1999).
Amphibians have evolved a large diversity of morphological changes that are different from aquatic vertebrates, including the tetrapod limb. They are a transitional group from aquatic to terrestrial lifestyle during vertebrate evolution. Therefore, they play a key role in the analysis of the evolution of genes that function well in different animals (MANNAERT et al. 2006). In this study, we isolated and analyzed the sequence, protein secondary structure and expression pattern of Mm-1 from Bufo gargarizans (Cantor, 1842). Combining with Mm-1s/Pfd5s/Gim5s in other species we also discussed its phylogeny, with the expectation of providing more information for further research.
MATERIAL AND METHODS
A male and a female of B. gargarizans (also termed Chinese large toad) were obtained from the Wuhu city in Anhui province, China. Tissues from toad muscle, stomach, brain, kidney, spleen, lung, liver, pancreas, testis, and ovary were removed, frozen immediately and stored at -80ºC.
Total RNA was extracted from toad testis with TRIzol (Invitrogen) according to the manufacturer's instructions. The full-length BgMm-1 cDNA testis-derived was obtained with GeneRacer kit (Invitrogen). Single-stranded cDNA was prepared with SuperScriptTM III reverse transcriptase, following the operating instruction. To amplify a conservative fragment of BgMm-1 cDNA, a pair of degenerate primers was designed based on the conserved amino acid sequences that have been found in the alignment of mammal and fish Mm-1s (mF: 5'-CTG(A/C)A(A/G/T)GTCGT(G/C/T)CA(A/G)(A/G)CCAA(A/G/C)(T/C)-3' and mR:5'-NTGTGCC(A/G)GCCTG(C/A/T)GCCG(C/T)-3'). PCR reaction was carried out in a 25 µl reaction mixture containing 16 µl ddH2O, 100 ng of cDNA, 1.5 mM Mg2+, 200 µM of each dNTP, 0.2 µM of each primer and 1 unit of Taq DNA polymerase (MBI Fermentas, Lithuania). The cycling conditions were three minutes at 95ºC, 30 cycles of 40 s at 94ºC, 40 s at 64ºC, 1 min 20 s at 72ºC and finally a 10 min elongation at 72ºC. The sequence information of the cDNA fragment was used to design gene-specific primers for 5' or 3' RACE, (5'-GSP: 5'-GCTCATCATTT CTACCACGGCTTGCT-3'; 3'-GSP: 5'-GTAGATAAGACTGCGGAT GATGCC-3'). The temperature conditions for 5'- and 3'-RACE were as follows: five cycles of denaturation at 94ºC for 1 min 30 s, and 25 cycles of denaturation at 94ºC for 30 s and annealing at 67ºC for 2 min. The amplified PCR products were isolated from 1.5% agarose/TBE gels, cloned into pCR®4-TOPO® vector (Invitrogen, USA) and sequenced at Shanghai Invitrogen Biotechnology Co. Ltd. (Shanghai, China).
The searches for nucleotide and protein sequence similarities were conducted with basic local alignment search tool (BLAST). The identity matrixes of the nucleotide and amino acid sequences were made with BioEdit sequence alignment editor. The deduced amino acid sequence was analyzed with the Editseq program and the protein domain features of BgMm-1 were determined by using Predict Protein sever and SWISS MODEL server. The modeling of the predicted protein secondary structure was carried out with SWISS MODEL server.
Multiple alignment of Mm-1s was performed using CLUSTAL X1.8 program. Aligned amino acid sequences were used to construct a phylogenetic tree by the neighbor-joining method using MEGA V3.0 program. Bootstrap analysis with 1000 replicates was used to assess the strength of the nodes in the tree.
Total RNA samples were isolated from eleven tissues of adult B. gargarizans, such as muscle, heart, brain, kidney, spleen, testis, ovary, lung, liver, pancreas and stomach, with TRIzol (Invitrogen) according to the manufacturer's instructions. Single-stranded cDNA were synthesized from 5 µg of total RNA by reverse transcription with M-MLV RTase (TaKaRa, Dalian, China), primed with Oligo(dT)18, and used as template for PCR. A pair of primers (mmF: 5'-AGTATGTAGAGGCGAAGGA-3' and mmR: 5'-ATTTCTACCACGGCTTGCT-3') was designed and synthesized based on the sequence of BgMm-1. The cycling conditions were 3 min at 95ºC, 30 cycles of 40 s at 94ºC, 40 s at 55ºC, 1 min 20 s at 72ºC and finally with a 10 min elongation at 72ºC.
In the positive control assay, a pair of primers specific to elongation factor 1α (EF1 α) (H1: 5'-TCCACCACCACCGGC CACCT-3', H2: 5'-CTCCCACACCAGCAGCAACAAT-3') were synthesized. The cycling conditions were 2 min at 95ºC, followed first by 5 cycles of 30 s at 94ºC, 40 s at 48ºC and 2 min at 72ºC, then by 30 cycles of 30 s at 94ºC, 40 s at 52ºC and 2 min at 72ºC with a final 10 min elongation at 72ºC. The PCR products were detected on 1.5% agarose gels.
RESULTS AND DISCUSSION
The cDNA sequence of BgMm-1
The obtained full length cDNA was named as BgMm-1 (Mm-1 of B. gargarizans) and has been submitted to GenBank (accession number: EF211947). BLAST search showed its homology at amino acids level with orthologues of Mus musculus Linnaeus, 1758 and Homo sapiens Linnaeus, 1758 MM-1 isoform a by 81% and 80% respectively. The cDNA nucleotide and deduced amino acid sequence of BgMm-1 are shown in figure 1. It is 755 bp long, and is composed by an ORF of 459 bp encoding a putative protein of 152 amino acids, a 5'untranslational region (UTR) of 14 bp and a 3'-UTR (including a polyA tail) of 282 bp. There was a conserved prefoldin α-like domain at amino acid position 22-145, suggesting that BgMm-1 participates in polypeptide folding. A putative leucine zipper motif was found at amino acid position 15-36, with a leucine residue every seven amino acids and with the motif being found partially into the conserved domain. It has been indicated that a protein with a leucine zipper motif was a transacting factor that can regulate the transcription of several genes in eukaryotic cells (WANG et al. 1998). The leucine zipper motif can mediate dimerization of a number of different proteins, including a class of DNA-binding proteins (KONSTANTINOV et al. 1994). It can be predicted that BgMm-1 may be involved in some regulation process.
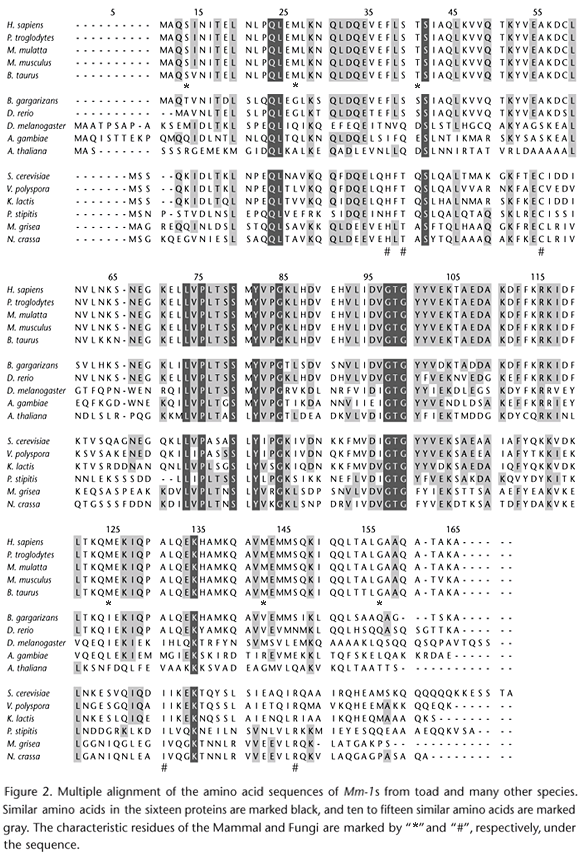
Multiple alignment of Mm-1s and the sequence identity analysis
Species and sequence accession numbers of Mm-1/Pfd5/Gim5 of 15 different organisms (Mammal, Fish, Insect, Plant, Fungi, and Archaea) used in the multiple alignment and sequence identity analysis were included in table I.
According to the alignment (Fig. 2), the amino acid sequences of Mm-1s/Pfd5s/Gim5s kept high identity in its core region, but changed considerably at the N and C terminals between classes during their evolution. This might suggest that the core region is key for the conservative function of the correct protein folding or c-Myc transcriptional activity repression. The amino acid sequences shared higher identity intraclass than interclass. For example, mammal were highly similar to one another, especially for H. sapiens, Pan troglodytes Blumenbach, 1775 and Macaca mulatta Zimmermann, 1780, whose sequences were completely identical. Similarly, the sequences of the three yeasts, Saccharomyces cerevisiae Hansen, 1883, Vanderwaltozyma polyspora Kurtzman, 2003 and Kluyveromyces lactis, Boidin, Abadie, J.L. Jacob & Pignal, 1971 were also very similar. These may lay the gene foundation for the close relationships of these species. Some classes even had their characteristic residues, such as fungi and mammals, marking the process of evolution. Generally speaking, all those properties made up the conservation and diversity of Mm-1s.
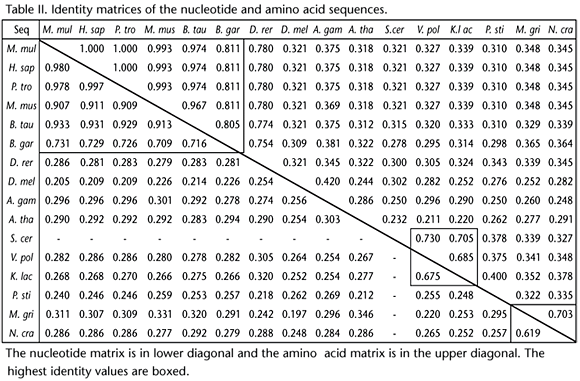
The identity matrixes of the nucleotide and amino acid sequences shown in table II revealed that: (1) the 5 mammalian gene sequences were highly similar with each other (the first boxÿnucleotideÿ0.907-0.997; amino acid, 0.967-1.0), revealing their absolutely close genetic relationship; (2) B. gargarizans Mm-1ÿisolated in this researchÿshared high homology with the mammalian orthologues (the first box, nucleotide, 0.709-0.731; amino acid, 0.805-0.811); (3) Danio rerio Hamilton, 1822 was quite distant from the mammalian orthologues; (4) the nucleotide sequence of S. cerevisiae was absent from the table. However, based on the amino acid homology (the second box, 0.730, 0.705) it can be found that S. cerevisiae was closely related to V. polyspora and K. lactis. The identity value nucleotide (0.675) and amino acid (0.685) suggested high similarity of V. polyspora and K. lactis. Above all, these three yeasts had relatively closer relationship than that with other fungi; (5) the higher fungi M agnaporthe grisea (T.T. Hebert) M.E. Barr, 1977was closely related with Neurospora crassa Shear & B.O. Dodge, 1927 for the high identity of both the nucleotide and amino acid sequences (the last box, 0.619, 0.703). All these results were consistent with the multiple sequence alignment.
Protein secondary structure
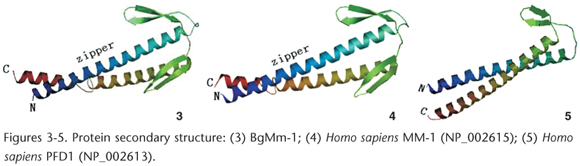
Pfd5/Gim5 is one of the subunits of PFD, which is a heterohexameric protein that has undergone an evolutionary change in subunit composition, from two PFDα and four PFDβ subunits in archaea to six different subunits (two α-like and four β-like subunits) in eukaryotes (MARTIN-BENITO et al. 2007). In animal cell, PFD is a heterohexameric protein composed by six subunits PFD1-6 (LEROUX et al. 1999). In yeast, the homology of PFD, the cognate complex, consists of six different subunits (Gim1-6) (SIEGERS et al. 1999ÿOKOCHI et al. 2004, LEROUX et al. 1999). However, in Archaea the counterpart gene GimC is made up of two α and four β subunits. (LEROUX et al. 1999). All the PFDs (or Gims) in the PFD family, were classified into two classes, that is, α class: eucaryotic Gim5 (Pfd5), Gim2 (Pfd3) and archaebacterial Gima; β class: eucaryotic Gim1 (Pfd6), Gim3 (Pfd4), Gim4 (Pfd2), Gim6 (Pfd1) and archaebacterial Gimb (LEROUX et al. 1999).
In this study, a leucine zipper was present in the secondary structure of BgMm-1, as revealed by the amino acid sequence analysis, together with two α-helices and four β-strands (Fig. 3). And the secondary structure of BgMm-1 was identical to that of H. sapiens MM-1 (Fig. 4), but different from H. sapiens PFD1, which consisted of two a-helices and two β-strands (Fig. 5). According to the schematic representation of Gim subunits in LEROUX et al. (1999), BgMm-1 and H. sapiens MM-1 belonging to the a class of PFD family and H. sapiens PFD1 belonging to the β class.
Phylogenetic analysis
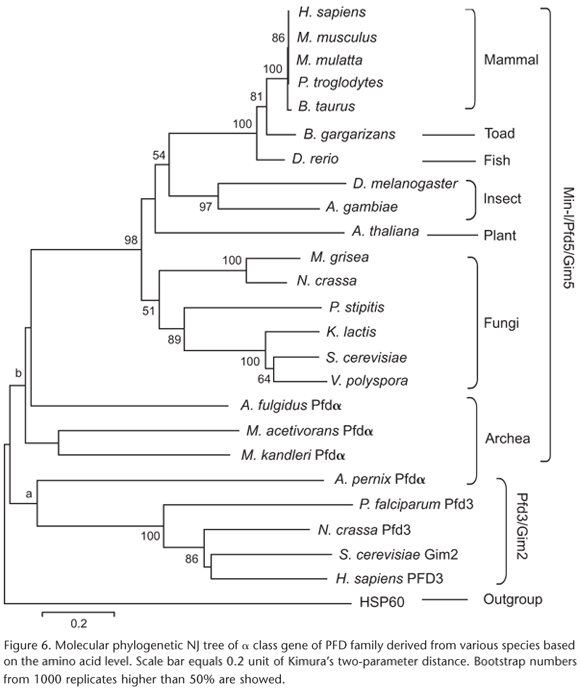
In order to analyze the phylogeny of Mm-1 and the evolution relationship between Mm-1 and other genes in α class of PFD family, several Gim2/Pfd3 and Pfdα sequences were used in the construction of the NJ phylogenetic tree. The human heat shock protein HSP60, another kind of chaperone, served as the outgroup (Fig. 6). Sequences applied in the phylogenetic tree were listed in table I.
There were two large branches, "a"-Mm-1/Pfd5/Gim5 and "b"-Pfd3/Gim2 in the NJ tree. Interestingly, the archaebacteria Pfdα were divided into two clades, with Aeropyrum pernix Sako et al., 1996 Pfdα classified into clade of "a" (Gim2) and others in clade of "b" (Gim5). According to the classification of PFD family in LEROUX et al. (1999), all the sequences used in the phylogenetic tree were members of α class of PFD family. And archaebacteria seemed to be very simple, with only one representative gene in this class. Combing with the cluster result, it can be presumed that archaebacterial Pfdα were the ancestor of the eukaryotic orthologues, and then some genes like A. pernix Pfdα evolved into eukaryotic Pfd3/Gim2 and others like Archaeoglobus fulgidus Stetter, 1988 Pfdα evolved into eukaryotic Mm-1/Pfd5/Gim5 during evolution process.
As for group of Gim5, archaebacteria, the lowest prokaryote were at the base and fungi were clustered into two clades, with yeasts (S. cerevisiae, V. polyspora, K. lactis, and Pichia stipitis Pignal, 1967) beneath higher fungi such as N. crassa and M. grisea; plant was above fungi and beneath invertebrate insects; the higher vertebrates clustered together, and the amphibian B. gargarizans was placed between fishes and mammals. All mammals clustered into a single clade, as in the case of the three yeasts: S. cerevisiae, V. polyspora and K. lactis. The cluster relationships were consistent with result of the sequence alignment (Fig. 2) and the identity matrices (Tab. II) discussed above. From the tree it can be found that Mm-1 was firstly emerged as Pfdα in archaebacteria, and then evolved in two paths when eukaryotes appeared, one was in the fungi path and another was in the animal and plant path. Although the different evolutional path, the gene still kept conservation and the phylogenetic relationships of Mm-1 was consistent with the evolution of species.
Expression analysis
The expression of BgMm-1 was analyzed with RT-PCR method. The BgMm-1 specific fragments (277bp) were detected in muscle, stomach, brain, kidney, heart spleen, lung, liver, pancreas, testis, and ovary, such as the positive control gene EF1a (300bp) (Fig. 7). Meanwhile, similar wide expression was reported on mouse Mm-1, as indicated in the introduction, and the human counterpart gene, which expresses in several human tissues such as fetal heart, T cells (Jurkat cell line), B-Cell, placenta, endothelial, brain, ovary (tumor), fetal spleen, fetal lungs and retina The Human Skeletal Muscle transcriptional profile, Unigene entry Hs.80686 (Jul, 9th, y99). Thus, BgMm-1 may undertake similar functions as the orthologue in mouse and human that mentioned above.
In conclusion, we cloned a full length cDNA sequence of Mm-1 from B. gargarizans and showed that this gene was identical to the human counterpart in the gene sequence and protein secondary structure. We analyzed the genetic relationship of Mm-1s in some different species, the phylogeny of the a class of PFD family, as well as gene sequence and gene expression pattern of BgMm-1. These results will be beneficial to the function investigation about BgMm-1. More experiments will be needed to verify whether BgMm-1 repress the transcriptional activity of c-Myc. Currently, a lot of biomedical studies are focusing on cancer and tumor repressor. Our work in toads may provide molecular data for further research.
ACKNOWLEDGEMENTS
This research was supported by National Natural Science Foundation of China (30770296), the Natural and Science Key Project of Anhui Educational Department (KJ2007A022), the Ph.D. Programs Foundation of Ministry of Education of China (200803700001) and the Key Laboratory of Biotic Environment and Ecology Safety in Anhui Province (2008).
LITERATURE CITED
Submitted: 30.X.2008; Accepted: 09.IV.2009.
Editorial responsibility: Marcio R. Pie
- ALT F.W.; R.A. DEPINHO; K. ZIMMERMAN; E. LEGOUY; K. HATTON; P. FERRIER; A. TESFAYE; G.D. YANCOPOULOS & P. NISEN. 1986. The human myc-gene family. Cold Spring Harbor Symposium on Quantitative Biology 51: 931-941.
- CHEN, L. 2000. Proto-oncogene c-myc and leukaemia. Journal of Fujian Medical University 34 (2): 202-204.
- DANG, C.V.; K.A. O'DONNELL; K.I. ZELLER; T. NGUYEN; R.C. OSTHUS & F. LI. 2006. The c-Myc target gene network. Seminars in Cancer Biology 16 (4): 253-264.
- DEPINHO, R.A.; L. MITSOCK; K. HATTON; P. FERRIER; K. ZIMMERMAN; E. LEGOUY; A. TESFAYE; R. COLLUM; G.YANCOPOULOS; P. NISEN; R. KRIZ & F. ALT. 1987. Myc family of cellular oncogenes. Journal of Cellular Biochemistry 33 (4): 257-266.
- FUJIOKA, Y.; T. TAIRA; Y. MAEDA; S. TANAKA; H. NISHIHARA; S.M. IGUCHIARIGA; K. NAGASHIMA & H. ARIGA. 2001. MM-1, a c-Myc-binding protein, is a candidate for a tumor suppressor in leukemia/lymphoma and tongue cancer. Journal of Biological Chemistry 76 (48): 45137-45144.
- HANSEN, W.J.; N.J. COWAN & W.J. WELCH. 1999. Prefoldin-nascent chain complexes in the folding of cytoskeletal proteins. The Journal of Cell Biology 145 (2): 265-277.
- INAZU, T.; Z. MYINT; A. KUROIWA; Y. MATSUDA & T. NOGUCHI. 2005. Molecular cloning, expression and chromosomal localization of mouse MM-1 Molecular Biology Reports 32 (4): 273-279.
- KONSTANTINOV, Y.M. & I.M. MØLLER. 1994. A leucine motif in the amino acid sequence of subunit 9 of the mitochondrial ATPase, and other hydrophobic membrane proteins, that is highly conserved by editing. FEBS Letters 354 (3): 245-247.
- LEROUX, R.M.; M. FANDRICH; D. KLUNKER; K. SIEGERS; N.A. LUPAS; M.C. DOBSON & F.U. HARTL. 1999. MtGimC, a novel archaeal chaperone related to the eukaryotic chaperonin cofactor GimC/prefoldin. The EMBO Journal 18 (23): 6730-6743.
- MANNAERT, A.; K. ROELANTS; F. BOSSUYT & L. LEYNS. 2006. A PCR survey for posterior Hox genes in amphibians. Molecular Phylogenetics and Evolution 38 (2): 449-458.
- MARTIN-BENITO, J.; J. BOSKOVIC; G.P. PUERTAS; L.J. CARRASCOSA; T.C. SIMONS; A.S. LEWIS; F. BARTOLINI; J.N. COWAN & M.J. VALPUESTA. 2002. Structure of eukaryotic prefoldin and of its complexes with unfolded actin and the cytosolic chaperonon CCT. The EMBO Journal 21 (23): 6377-6386.
- MARTIN-BENITO, J.; J. GOMEZ-REINO; C.P. STIRLING; F.V. LUNDIN & P. GOMEZPUERTAS. 2007. Divergent substrate-binding mechanisms reveal an evolutionary specialization of eukaryotic prefoldin compared to its archaeal counterpart. Cell 15 (1): 101-110.
- MORI, K.; Y. MAEDA; H. KITAURA; T. TAIRA; S.M. IGUCHI-ARIGA & H. ARIGA. 1998. MM-1, a Novel c-Myc-associating Protein That Represses Transcriptional Activity of c-Myc. Journal of Biological Chemistry 273 (45): 29794-29800.
- OKOCHI, M.; H. MATSUZAKI; T. NOMURA; N. ISHII & M. YOHDA. 2004. Molecular characterization of the group II chaperonin from the hyperthermophilic archaeum Pyrococcus horikoshii OT3. Extremophiles 9 (2): 127-134.
- SATOU, A.; T. TAIRA; S.M.M. IGUCHI-ARIGA & H. ARIGA. 2001. A novel transrepression pathway of c-Myc. Recruitment of a transcriptional corepressor complex to c-Myc by MM-1, a c-Myc-binding protein. Journal of Biological Chemistry 276 (49): 46562-46567.
- SIEGERS, K.; T. WALDMANN; M. LEROUX; K. GREIN; A. SHEVCHENKO; E. SCHIEBEL & F.U. HARTL. 1999. Compartmentation of protein folding in vivo: sequestration of non-native polypeptide by the chaperonin-GimC system. The EMBO Journal 18 (1): 75-84.
- VAINBERG, I.E.; S.A. LEWIS; H. ROMMELAERE; C. AMPE; J. VANDEKERCKHOVE; H.L. KLEIN & N.J. COWAN. 1998. Prefoldin, a chaperone that delivers unfolded proteins to cytosolic chaperonin. Cell 93 (5): 863-873.
- WANG, K.R.; S.B. XUE & H.T. LIU. 1998. Cell biology. Beijing: Publisher of Beijing Normal University 361-366.
- ZAJAC-KAYE, M. 2001. Myc oncogene: a key component in cell cycle regulation and its implication for lung cancer. Lung Cancer 34: S43-S46.
Publication Dates
-
Publication in this collection
25 Mar 2010 -
Date of issue
Feb 2010
History
-
Accepted
09 Apr 2009 -
Received
30 Oct 2008