Abstract
Abstract: We introduce a new class of continuous distributions called the generalized odd Lindley-G family. Four special models of the new family are provided. Some explicit expressions for the quantile and generating functions, ordinary and incomplete moments, order statistics and Rényi and Shannon entropies are derived. The maximum likelihood method is used for estimating the model parameters. The flexibility of the generated family is illustrated by means of two applications to real data sets.
Key words
generating function; lindley distribution; maximum likelihood; order statistic; T-X family
INTRODUCTION
In many applied sciences such as medicine, engineering and finance, among others, modeling and analyzing lifetime data are crucial. Several lifetime models have been adopted to model different types of survival data. The quality of the procedures used in a statistical analysis depends heavily on the generated family of distributions and considerable effort has been directed to define new statistical models. However, there still remain many important problems involving real data, which do not follow any of the popular statistical models. So, the procedure of expanding a family of distributions by adding new shape parameters is well-known in the statistical literature.
The role of the extra shape parameters is to introduce skewness and to vary tail weights. Further, several models have been constructed by extending some useful lifetime distributions and investigated them with respect to different characteristics. The generalized distributions provide more flexibility to model both monotonic and non-monotonic failure rates even though the baseline failure rate may be monotonic.
A large number of models has been proposed to model lifetime data. Lindley (1958)LINDLEY DV. 1958. Fiducial distributions and Bayes’ theorem. J R Stat Soc Series B 20: 102-107. proposed the Lindley (Li) distribution as a mixture of exponential and gamma distributions to analyze failure time data. The Li distribution is motivated by its ability to model failure time data with increasing, decreasing, unimodal and bathtub shaped hazard rates.
The properties, estimation and inference of the Li distribution are described in the literature as follows. Hussain (2006)HUSSAIN E. 2006. The non-linear functions of order statistics and their properties in selected probability models. Ph.D. thesis. Department of Statistics. University of Karachi, Pakistan. used this distribution for studying stress–strength reliability modeling. Ghitany et al. (2008)GHITANY M, ATIEH B and NADARAJAH S. 2008. Lindley distribution and its application. Math Comp Simul 78: 493-506. provided a comprehensive treatment of its mathematical properties showing that it may provide a better fitting than the exponential distribution.
Many authors developed generalizations of the Li distribution. For example, Sankaran (1970)SANKARAN M. 1970. The discrete Poisson–Lindley distribution. Biometrics 26: 145-149. introduced the discrete Poisson–Li, Zakerzadeh and Dolati (2009)ZAKERZADEH H and DOLATI A. 2009. Generalized Lindley Distribution. J Math Ext 3: 13-25. defined the generalized Li, Zamani and Ismail (2010)ZAMANI H and ISMAIL N. 2010. Negative binomial-Lindley distribution and its application. Journal of Mathematics and Statistics 6: 4-9. proposed the negative binomial-Li, Mahmoudi and Zakerzadeh (2010)MAHMOUDI E and ZAKERZADEH H. 2010. Generalized Poisson–Lindley distribution. Commun Stat - Theory Methods 39: 1785-1798. investigated the generalized Poisson–Li, Nadarajah et al. (2011)NADARAJAH S, BAKOUCH HS and TAHMASBI R. 2011. A generalized Lindley distribution. Sankhya B 73: 331-359. introduced a two-parameter generalized Li as an alternative to the gamma, lognormal, Weibull and exponentiated exponential distributions, Bakouch et al. (2012)BAKOUCH HS, AL-ZAHRANI BM, AL-SHOMRANI AA, MARCHI VAA and LOUZADA F. 2012. An extended Lindley distribution. J Korean Stat Soc 41: 75-85. proposed the extended Li motivated by its ability to model lifetime data with different shapes for the failure rate, Ghitany et al. (2013)GHITANY ME, AL-MUTAIRI DK, BALAKRISHNAN N and AL-ENEZI L. 2013. Power Lindley distribution and associated inference. Comput Stat Data Anal 64: 20-33. pioneered the power Li and Nedjar and Zeghdoudi (2016)NEDJAR S and ZEGHDOUDI H. 2016. Gamma Lindley distribution and its application. J Appl Probab Stat 11: 129-138. studied the gamma Li distribution.
In this paper, based on the T-X family pioneered by Alzaatreh et al. (2013)ALZAATREH A, LEE C and FAMOYE F. 2013. A new method for generating families of distributions. Metron 71: 63-79. and the Li distribution, we construct the generalized odd Lindley-G (GOLi-G for short) family, which extends the OLi-G class (Gomes-Silva et al. 2017)GOMES-SILVA FS, PERCONTINI A, BRITO E, RAMOS MW, VENÂNCIO R and CORDEIRO GM. 2017. The Odd Lindley-G Family of Distributions. Austrian Journal of Statistics 46: 65-87., and provide some of its mathematical properties. In fact, the new generator of distributions is motivated by its ability to model lifetime data with increasing, decreasing, constant, unimodal and bathtub shaped failure rates. Further, the special models of this family are shown to provide better fits than other competitive models generated by other well-known families in the literature.
The cumulative distribution function (cdf) and probability density function (pdf) of the GOLi-G family with two additional shape parameters and are defined from a baseline cdf by
and
respectively, where and is the baseline vector. Henceforth, a random variable with density (2) is denoted by GOLi-G( ). For , we obtain as a special case the OLi-G class.
An interpretation of the GOLi-G family (1) can be given as follows. Let be a random variable describing a stochastic system by the cdf (for ). If the random variable represents the odds ratio, the risk that the system following the lifetime will be not working at time is given by . If we are interested in modeling the randomness of the odds ratio by the Li pdf, (for ), then the cdf of is given by
which is exactly the cdf (1) of the GOLi-G family.
Henceforth, we can omit the dependence on the model parameters. The hazard rate function (hrf) of is given by
The rest of the paper is organized as follows. In Section 2, we present four special models and plots of their pdfs and hazard rate functions (hrfs). In Section 3, we provide a very useful linear representation for the density function of . In Section 4, we derive some of its general mathematical properties including quantile and generating functions, asymptotics, ordinary and incomplete moments, order statistics and entropies. Maximum likelihood estimation of the model parameters is addressed in Section 5. Section 6 is devoted to simulation results to assess the performance of the maximum likelihood estimation of the unknown parameters of the generalized odd Lindley Weibull (GOLiW) distribution. In Section 7, we provide two applications to real data to illustrate the flexibility of the special models of the new family. Finally, we offer some concluding remarks in Section 8.
FOUR SPECIAL GOLi-G MODELS
In this section, we provide four special models of the GOLi-G family. The pdf (2) will be most tractable when the cdf and the pdf have simple analytic expressions.
THE GOLiW DISTRIBUTION
Consider the cdf (for ) of the Weibull distribution with positive parameters and . Then, the pdf of the GOLiW model is given by
For , we obtain the GOLi-exponential (GOLiE) distribution. For , we obtain the GOLi-Rayleigh (GOLiR) distribution. The GOLiW reduces to the OLiW when . We have the OLiE and OLiR when and , respectively. Some possible shapes of the GOLiW density and hazard functions are displayed in Figure 1.

THE GOLi-BURR XII (GOLiBXII) DISTRIBUTION
The cdf (for ) of the Burr XII (BXII) distribution with positive parameters and is . Then, the GOLiBXII density reduces to
For and , we obtain the one-parameter GOLi Lomax (GOLiLx) and one-parameter GOLi log-logistic (GOLiLL) distributions, respectively. The cases and refer to the OLiLx and OLiLL distributions, respectively. Plots of the density and hazard functions of the GOLiBXII distribution are displayed in Figure 2.

The GOLi-Lomax (GOLiLx) distribution
The cdf (for ) of the Lomax (Lx) distribution with positive parameters and is . Then, the GOLiLx pdf becomes
Plots of the density and hazard functions of the GOLiLx distribution are displayed in Figure Figure 3.

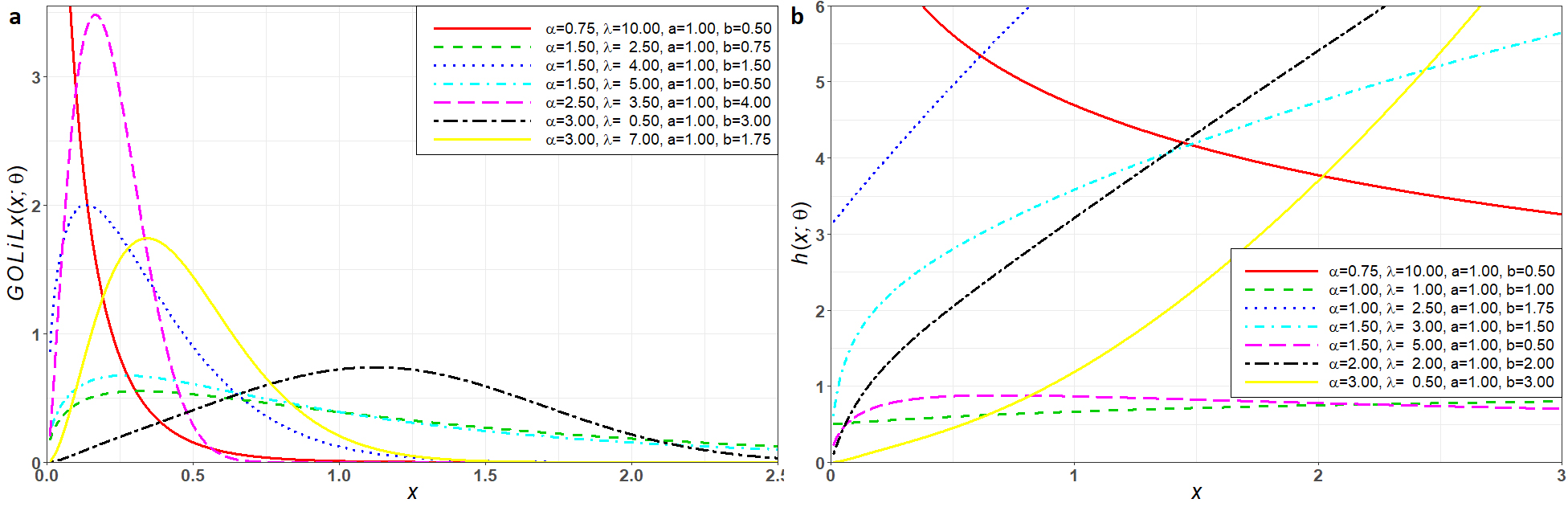
THE GOLi-LOG-LOGISTIC (GOLiLL) DISTRIBUTION
Consider the cdf (for ) of the log-logistic (LL) distribution with positive parameters and . The GOLiLL density is given by
Plots of the density and hazard functions for the GOLiLL distribution for selected parameter values are displayed in Figure 4.

LINEAR REPRESENTATION
In this section, we provide a useful linear representation for the GOLi-G density. It can be expressed as
Using the exponential series, we can write
Consider the power series
Applying this series to the quantity , we obtain
Substituting (6) in equation (4), we can write
Then, the GOLi-G density can be expressed as a linear combination of exponentiated-G (Exp-G) densities
where
and is the Exp-G density with power parameter . Thus, several mathematical properties of the GOLi-G family can be determined from those properties of the Exp-G family. Equation (8) is the main result of this section.
The cdf of the GOLi-G family can also be expressed as a linear combination of Exp-G cdfs. By integrating (8), we have
where is the cdf of the Exp-G family with power parameter .
STRUCTURAL PROPERTIES
In this section, we obtain some structural properties of the GOLi-G family including quantile and generating functions, asymptotics, ordinary and incomplete moments, order statistics and entropies.
QUANTILE FUNCTION
Let be the quantile function (qf) of the parent G. In this section, we provide two algorithms for simulating the GOLi-G model.
The first algorithm is based on generating random data from the Li distribution using the exponential-gamma mixture.
-
Algorithm 1 (Mixture form of the Li distribution)
-
Generate
-
Generate
-
Generate
If , set ;otherwise, set
The second algorithm is based on generating random data by inverting (1).
-
Algorithm 2 (Inverse cdf)
-
Generate
Set (for )
where is the negative branch of the Lambert function. The branches of this function are defined by . It is a two-valued function on the interval . For , the function is denoted and is called the negative branch. For , the function is called the principal branch of the W function. The Lambert function cannot be expressed in terms of elementary functions.
ASYMPTOTICS
Let . Then, the asymptotics of equations (1), (2) and (3) when are given by
The asymptotics of equations (1), (2) and (3) when are given by
GENERATING FUNCTION
Here, we obtain the moment generating function (mgf) of . Henceforth, let denote the random variable having the Exp-G class with power parameter .
We can write from equation (8)
where and is the mgf of . Hence, can be determined from the Exp-G generating function. If has an explicit expression, will also have a closed-form. For some baselines such as the exponential, Lomax, normal, gamma, among others, this is possible.
We define the cumulant generating function (cgf) of by . The saddle–point approximation is of the main applications of the cgf in Statistics and provides highly accurate approximation formulae for the densities of the sum and mean of independent identically distributed (iid) random variables. Let be iid random variables having common GOLi-G cgf . We define and obtain from the (usual nonlinear) equation and let . The density function of is followed from Daniels’ saddle–point approximation as
MOMENTS
The th ordinary moment of , say , follows from (8) as
The central moment of are easily obtained from (10).
The cumulants ( ) of follow recursively from
where , etc. The measures of skewness and kurtosis can be calculated from the ordinary moments using well-known relationships.
The th incomplete moment of , say , can be expressed from (8) as
where can be computed numerically from the baseline qf .
For , we obtain the first incomplete moment from (11). It can be applied to construct Bonferroni and Lorenz curves defined for a given probability by and , respectively, where is given by (10) with and is the qf of at obtained from (9). These curves are very useful in economics, reliability, demography, insurance and medicine.
ORDER STATISTICS
Order statistics make their appearance in many areas of statistical theory and practice. Let be a random sample from the GOLi-G family. The pdf of can be written as
where is the beta function.
Based on equation (1), we can write
After applying the generalized binomial series, we have
Using (2) and (13), we can write
Using the exponential series, we obtain
The Taylor series for defined by
holds, where is the descending factorial.
Applying (14) to gives
Then, the last equation reduces to
Applying the power series (5) to gives
Inserting the last equation in (12), the pdf of can be expressed as
where, as before, is the Exp-G density with power parameter and
Then, the density function of the GOLi-G order statistics is a linear combination of Exp-G densities. Based on equation (15), we note that the mathematical properties of follow from those of . For example, the th moment of is given by
Based upon the moments in equation (16), we can derive explicit expressions for the L-moments of as infinite weighted linear combinations of the means of suitable GOLi-G order statistics.
ENTROPIES
The Rényi entropy of a random variable represents a measure of variation of the uncertainty. The Rényi entropy is given by
Using the pdf (2), we can write
Using the exponential series, we have
Applying the power series (5) to the last term, we have
Then, the Rényi entropy of the GOLi-G family reduces to
where
The Shannon entropy of , say , is given by
First, we define and compute
By using the exponential series, we obtain
Using the binomial expansion, we have
The following proposition is used to determine the Shannon entropy of .Proposition 1. Let be a random variable with pdf given in (2). Then,
MAXIMUM LIKELIHOOD ESTIMATION
Several approaches for parameter estimation were proposed in the literature but the maximum likelihood method is the most commonly employed. The maximum likelihood estimators (MLEs) enjoy desirable properties and can be used to obtain confidence intervals for the model parameters. The normal approximation for these estimators in large samples can be easily handled either analytically or numerically. Here, we consider the estimation of the unknown parameters of the new family from complete samples only by maximum likelihood.
Let be a random sample from the GOLi-G family with parameters α,λ and . Let ( ) be the parameter vector. The log-likelihood function for is given by
Then, the score vector components, , are
and
where and
Setting the nonlinear system of equations and and solving them simultaneously yields the MLE . For doing this, it is usually more convenient to adopt nonlinear optimization methods such as the quasi-Newton algorithm to maximize numerically. For interval estimation of the parameters, we obtain the observed information matrix (for ), which can be evaluated numerically.
Under standard regularity conditions, the distribution of can be approximated by a multivariate normal distribution when to obtain confidence intervals for the parameters. Here, is the total observed information matrix evaluated at . The method of the re-sampling bootstrap can be used for correcting the biases of the MLEs of the model parameters. Good interval estimates may also be obtained using the bootstrap percentile method.
SIMULATION STUDY
In this section, we present some simulation results that investigate the behavior of the MLEs in terms of the sample size . All simulations are performed using the Rprogramming language (R Core Team 2017R CORE TEAM. 2017. R: A language and environment for statistical computing. R Foundation for Statistical Computing.).
The qf of the GOLiW distribution is given by
We generate random samples from this distribution using the last expression for three different sample sizes , and . The true values of the parameters are taken as: and . For each sample size and parameter combination, the average MLEs and the mean square errors (MSEs) are computed. In order to save space, Table I gives only the results for , and are not reported for . It can be verified that the estimates are stable and quite close the true parameter values for all sample sizes. Further, the MSEs decrease when the sample size increases in all cases in agreement with the first-order asymptotic theory.
APPLICATIONS
In this section, we provide two applications to real data to illustrate the flexibility of the GOLiLx, GOLiLL and GOLiBXII distributions presented in Section 2. The goodness-of-fit statistics for these models are compared with other competitive models and the MLEs of the model parameters are determined.
The model selection is carried out using some goodness-of-fit measures including the Akaike information criterion ( ), consistent Akaike information criterion ( ), Hannan-Quinn information criterion ( ), Bayesian information criterion ( ), Anderson-Darling and Cramér-von Mises ( ). The smaller these statistics are, the better the fit.
APPLICATION 1: TIME-TO-FAILURE OF TURBOCHARGER DATA
The first data set consists of 40 times to failures ( h) of turbocharger of one type of engine given in Xu et al. (2003)XU K, XIE M, TANG LC and HO SL. 2003. Application of neural networks in forecasting engine systems reliability. Appl Soft Comput 2: 255-268.. For these data, we shall compare the fit of the GOLiLx and GOLiLL distributions with those of other competitive models, namely: the Kumaraswamy transmuted log-logistic (KwTLL) (Afify et al. 2016AFIFY AZ, CORDEIRO GM, YOUSOF HM, ALZAATREH A and NOFAL ZM. 2016. The Kumaraswamy transmuted-G family of distributions: properties and applications. Journal of Data Science 14: 245-270.), Kumaraswamy log-logistic (KwLL) (de Santana et al. 2012DE SANTANA TVF, ORTEGA EMM, CORDEIRO GM and SILVA GO. 2012. The Kumaraswamy log-logistic distribution. Stat Theory Appl 3: 265-291.), transmuted log-logistic (TLL) (Granzotto and Louzada 2015GRANZOTTO DCT and LOUZADA F. 2015. The transmuted log-logistic distribution: modeling, inference and na application to a polled tabapua race time up to first calving data. Commun Stat - Theory Methods 44: 3387-3402.), McDonald log-logistic (McLL) (Tahir et al. 2014TAHIR MH, MANSOOR M, ZUBAIR M and HAMEDANI G. 2014. McDonald log-logistic distribution with an application to breast cancer data. Journal of Statistical Theory and Applications 13: 65-82.), beta log-logistic (BLL) (Lemonte 2014LEMONTE AJ. 2014. The beta log-logistic distribution. Braz J Probab Stat 28: 313-332.), generalized transmuted log-logistic (GTLL) (Nofal et al. 2017NOFAL ZM, AFIFY AZ, YOUSOF HM and CORDEIRO GM. 2017. The generalized transmuted-G family of distributions. Commun Stat - Theory Methods 46: 4119-4136.) and Li-log-logistic (LiLL) (Cakmakyapan and Ozel 2016CAKMAKYAPAN S and OZEL G. 2016. The Lindley family of distributions: properties and applications. Hacet J Math Stat 46: 1-27.) distributions, whose densities (for ) are given, respectively, by: KwTLL:
KwLL:
TLL:
McLL:
BLL:
GTLL:
LiLL: The parameters of the above densities are all positive real numbers except for the KwTLL, TLL and GTLL models for which the parameter is .
APPLICATION 2: CANCER PATIENTS DATA
The second data set on the remission times (in months) of a random sample of 128 bladder cancer patients (Lee and Wang 2003LEE ET and WANG JW. 2003. Statistical methods for survival data analysis. 3rd ed., Wiley, New York.). For these data, we compare the fit of the GOLiBXII distribution with those of the OLiBXII, Weibull BXII (WBXII) (Afify et al. 2018AFIFY AZ, CORDEIRO GM, ORTEGA EMM, YOUSOF HM and BUTT NS. 2018. The four-parameter Burr XII distributions: properties, regression model and applications. Commun Stat - Theory Methods 47: 2605-2624.), Kumaraswamy exponentiated Burr XII (KwEBXII) (Mead and Afify 2017MEAD ME and AFIFY AZ. 2017. On five-parameter Burr XII distribution: properties and applications. South African Statistical Journal 51: 67-80.), McDonald Weibull (McW) (Cordeiro et al. 2014), beta BXII (BBXII) (Paranaíba et al. 2011PARANAÍBA PF, ORTEGA EMM, CORDEIRO GM and PESCIM RR. 2011. The beta Burr XII distribution with application to lifetime data. Comput Stat Data Anal 55: 1118-1136.), beta exponentiated BXII (BEBXII) (Mead 2014MEAD ME. 2014. The beta exponentiated Burr XII distribution. Journal of Statistics: Advances in Theory and Applications 12: 53-73.), LiBXII (Cakmakyapan and Ozel 2016) and BXII models with densities (for ), respectively, given by:
WBXII:
KwEBXII:
McW:
BBXII:
BEBXII:
LiBXII: All the above parameters are positive real numbers.
Tables II and IV list the values of , , , , and , whereas the MLEs and their corresponding standard errors (in parentheses) of the model parameters are given in Tables III and V.
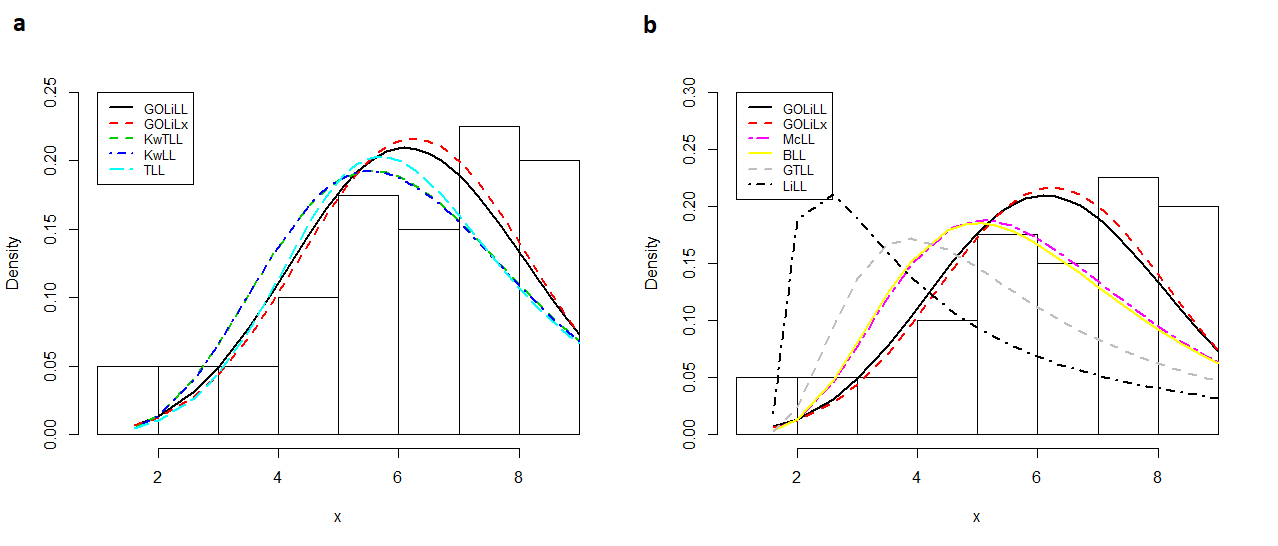
The fitted GOLiLL and GOLiLx pdfs and other fitted pdfs for the time-to-failure data are displayed in Figure 5, whereas the PP-plots of these fitted models are displayed in Figure S7 (Supplementary Material) SUPPLEMENTARY MATERIAL Figure S7 - PP-plots of the GOLiLL and GOLiLx distributions and other competitive distributions. Figure S8 - Histological features of represrntative liver sectioons. . These plots reveal that the GOLiLx and GOLiLL distributions provide the best fits and can be considered very competitive models to other non-nested distributions.

The estimated GOLiLL and GOLiLx pdfs and other estimated pdfs for time-to-failure data. (a) The estimated GOLiLL, GOLiLx, KwTLL, KwLL and TLL densities. (b) The estimated GOLiLL, GOLiLx, McLL, BLL, GTLL and LiLL densities.
The plots of the fitted GOLiBXII pdf and other fitted pdfs defined before, for the cancer data, are displayed in Figure 6. The PP-plots of the fitted models are given in Figure S8. These plots reveal that the GOLiBXII distribution provides the best fits and it can be considered a very competitive model to other distributions with positive support.

The estimated GOLiBXII pdf and other estimated pdfs for cancer data. (a) The estimated GOLiBXII, WBXII, KwEBXII, McW and LiBXII densities. (b) The estimated GOLiBXII, BBXII, OLiBXII, BEBXII and BXII densities.
CONCLUSIONS
In this paper, we propose a new family of distributions with two extra positive parameters called the generalized odd Lindley-G family. The new family extends several widely known distributions and four of its special models are discussed. We demonstrate that its density function is a linear combination of exponentiated-G densities. We obtain some mathematical properties of the new family, which include quantile and generating functions, asymptotics, ordinary and incomplete moments, order statistics and entropies. The model parameters are estimated by the methods of maximum likelihood. Simulation results are reported for this method. Two real examples are used for illustration, where the new family does fit well both data sets.
REFERENCES
- AFIFY AZ, CORDEIRO GM, ORTEGA EMM, YOUSOF HM and BUTT NS. 2018. The four-parameter Burr XII distributions: properties, regression model and applications. Commun Stat - Theory Methods 47: 2605-2624.
- AFIFY AZ, CORDEIRO GM, YOUSOF HM, ALZAATREH A and NOFAL ZM. 2016. The Kumaraswamy transmuted-G family of distributions: properties and applications. Journal of Data Science 14: 245-270.
- ALZAATREH A, LEE C and FAMOYE F. 2013. A new method for generating families of distributions. Metron 71: 63-79.
- BAKOUCH HS, AL-ZAHRANI BM, AL-SHOMRANI AA, MARCHI VAA and LOUZADA F. 2012. An extended Lindley distribution. J Korean Stat Soc 41: 75-85.
- CAKMAKYAPAN S and OZEL G. 2016. The Lindley family of distributions: properties and applications. Hacet J Math Stat 46: 1-27.
- DE SANTANA TVF, ORTEGA EMM, CORDEIRO GM and SILVA GO. 2012. The Kumaraswamy log-logistic distribution. Stat Theory Appl 3: 265-291.
- GHITANY ME, AL-MUTAIRI DK, BALAKRISHNAN N and AL-ENEZI L. 2013. Power Lindley distribution and associated inference. Comput Stat Data Anal 64: 20-33.
- GHITANY M, ATIEH B and NADARAJAH S. 2008. Lindley distribution and its application. Math Comp Simul 78: 493-506.
- GOMES-SILVA FS, PERCONTINI A, BRITO E, RAMOS MW, VENÂNCIO R and CORDEIRO GM. 2017. The Odd Lindley-G Family of Distributions. Austrian Journal of Statistics 46: 65-87.
- GRANZOTTO DCT and LOUZADA F. 2015. The transmuted log-logistic distribution: modeling, inference and na application to a polled tabapua race time up to first calving data. Commun Stat - Theory Methods 44: 3387-3402.
- HUSSAIN E. 2006. The non-linear functions of order statistics and their properties in selected probability models. Ph.D. thesis. Department of Statistics. University of Karachi, Pakistan.
- LEE ET and WANG JW. 2003. Statistical methods for survival data analysis. 3rd ed., Wiley, New York.
- LEMONTE AJ. 2014. The beta log-logistic distribution. Braz J Probab Stat 28: 313-332.
- LINDLEY DV. 1958. Fiducial distributions and Bayes’ theorem. J R Stat Soc Series B 20: 102-107.
- MAHMOUDI E and ZAKERZADEH H. 2010. Generalized Poisson–Lindley distribution. Commun Stat - Theory Methods 39: 1785-1798.
- MEAD ME. 2014. The beta exponentiated Burr XII distribution. Journal of Statistics: Advances in Theory and Applications 12: 53-73.
- MEAD ME and AFIFY AZ. 2017. On five-parameter Burr XII distribution: properties and applications. South African Statistical Journal 51: 67-80.
- NADARAJAH S, BAKOUCH HS and TAHMASBI R. 2011. A generalized Lindley distribution. Sankhya B 73: 331-359.
- NEDJAR S and ZEGHDOUDI H. 2016. Gamma Lindley distribution and its application. J Appl Probab Stat 11: 129-138.
- NOFAL ZM, AFIFY AZ, YOUSOF HM and CORDEIRO GM. 2017. The generalized transmuted-G family of distributions. Commun Stat - Theory Methods 46: 4119-4136.
- PARANAÍBA PF, ORTEGA EMM, CORDEIRO GM and PESCIM RR. 2011. The beta Burr XII distribution with application to lifetime data. Comput Stat Data Anal 55: 1118-1136.
- R CORE TEAM. 2017. R: A language and environment for statistical computing. R Foundation for Statistical Computing.
- SANKARAN M. 1970. The discrete Poisson–Lindley distribution. Biometrics 26: 145-149.
- TAHIR MH, MANSOOR M, ZUBAIR M and HAMEDANI G. 2014. McDonald log-logistic distribution with an application to breast cancer data. Journal of Statistical Theory and Applications 13: 65-82.
- XU K, XIE M, TANG LC and HO SL. 2003. Application of neural networks in forecasting engine systems reliability. Appl Soft Comput 2: 255-268.
- ZAKERZADEH H and DOLATI A. 2009. Generalized Lindley Distribution. J Math Ext 3: 13-25.
- ZAMANI H and ISMAIL N. 2010. Negative binomial-Lindley distribution and its application. Journal of Mathematics and Statistics 6: 4-9.
Publication Dates
-
Publication in this collection
12 Aug 2019 -
Date of issue
2019
History
-
Received
12 Jan 2018 -
Accepted
13 Nov 2018