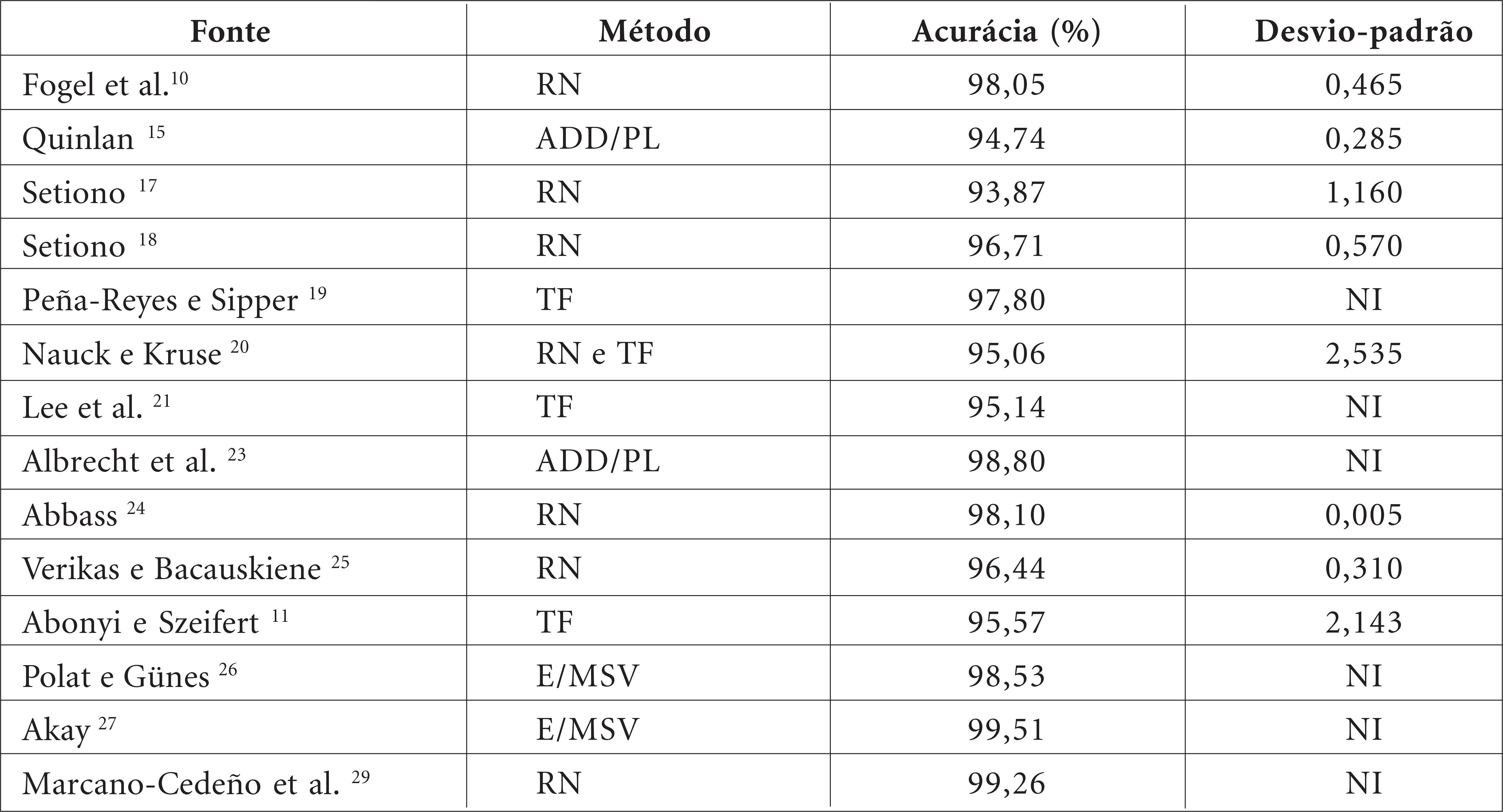
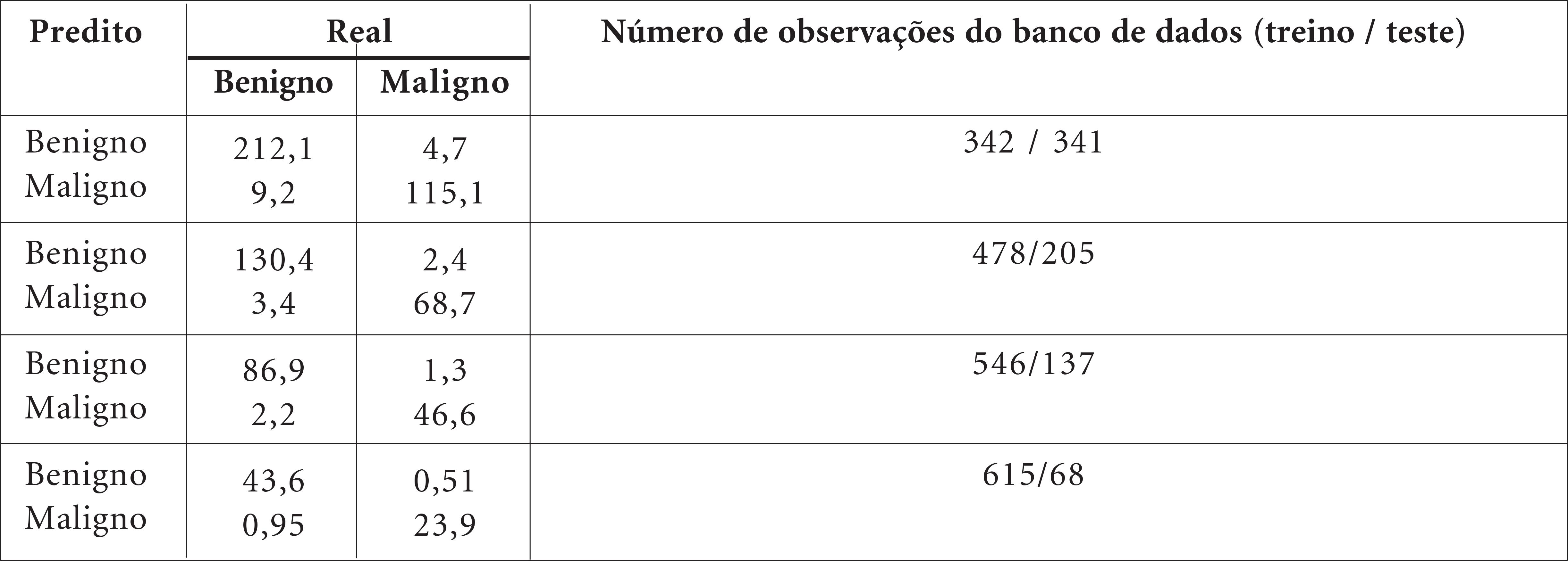
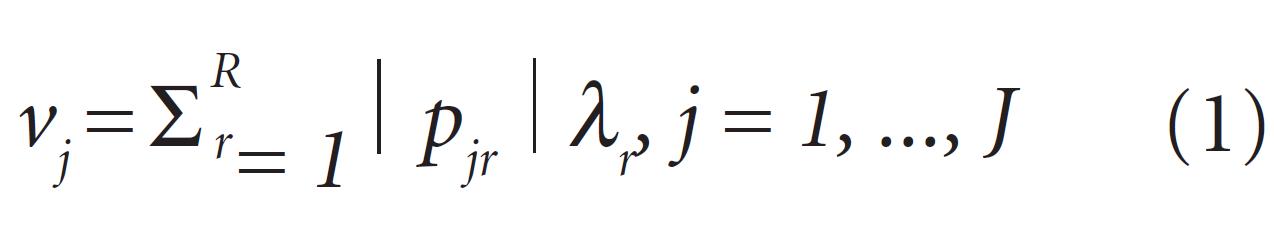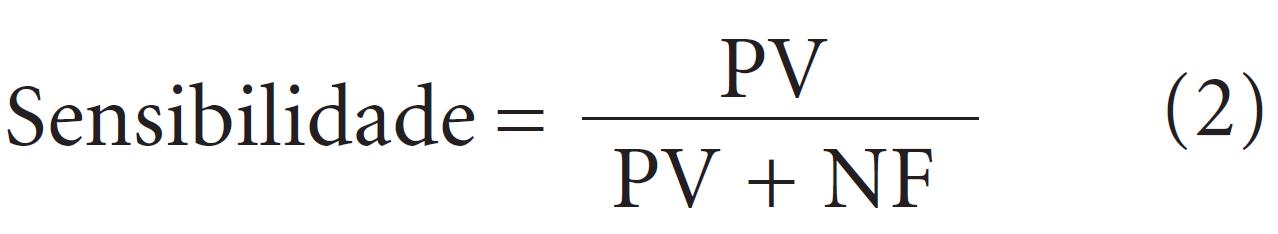In the majority of countries, breast cancer among women is highly prevalent. If diagnosed in the early stages, there is a high probability of a cure. Several statistical-based approaches have been developed to assist in early breast cancer detection. This paper presents a method for selection of variables for the classification of cases into two classes, benign or malignant, based on cytopathological analysis of breast cell samples of patients. The variables are ranked according to a new index of importance of variables that combines the weighting importance of Principal Component Analysis and the explained variance based on each retained component. Observations from the test sample are categorized into two classes using the k-Nearest Neighbor algorithm and Discriminant Analysis, followed by elimination of the variable with the index of lowest importance. The subset with the highest accuracy is used to classify observations in the test sample. When applied to the Wisconsin Breast Cancer Database, the proposed method led to average of 97.77% in classification accuracy while retaining an average of 5.8 variables.
Selection of variables; Breast cancer identification; K-nearest neighbor algorithm (KNN); Discriminant analysis