
Abstracts
In biologic experiments, in which growth curves are adjusted to sample data, treatments applied to the experimental material can affect the parameter estimates. In these cases the interest is to compare the growth functions, in order to distinguish treatments. Three methods that verify the equality of parameters in nonlinear regression models were compared: (i) developed by Carvalho in 1996, performing ANOVA on estimates of parameters of individual fits; (ii) suggested by Regazzi in 2003, using the likelihood ratio method; and (iii) constructing a pooled variance from individual variances. The parametric tests, F and Tukey, were employed when the parameter estimators were near to present the properties of linear model estimators, that is, unbiasedness, normal distribution and minimum variance. The first and second methods presented similar results, but the third method is simpler in calculations and uses all information contained in the original data.
logistic model; treatments comparison
Em experimentos biológicos, em que curvas assintóticas de crescimento são ajustadas a resultados amostrais, o padrão de crescimento pode ser afetado por tratamentos aplicados ao material experimental. Nesses casos há interesse em comparar as diferentes funções de crescimento, com o objetivo de diferenciar os tratamentos. Compararam-se três métodos de verificação de igualdade de parâmetros em modelos de regressão não-linear: (i) desenvolvido por Carvalho em 1996, o qual realiza análises de variância com estimativas dos parâmetros resultantes de ajustamentos do modelo em cada unidade experimental; (ii) sugerido por Regazzi em 2003, utilizando o método da razão da máxima verossimilhança; e (iii) construindo uma variância conjunta a partir das variâncias individuais das estimativas dos parâmetros obtidas nos ajustamentos do modelo. Os testes F e Tukey foram empregados quando foi possível considerar os estimadores dos parâmetros com propriedades próximas às dos estimadores de modelos lineares, isto é, não-tendenciosidade, distribuição normal e variância mínima. Os dois primeiros métodos apresentaram resultados semelhantes quanto à discriminação dos tratamentos; o terceiro método diferiu dos anteriores, mas tem a vantagem de apresentar simplicidade nos cálculos, além de utilizar toda a informação contida nos dados originais.
modelo logístico; comparação de tratamentos
STATISTICS
Methods to verify parameter equality in nonlinear regression models
Métodos de verificação de igualdade de parâmetros em modelos de regressão não-linear
Lídia Raquel de Carvalho; Sheila Zambello de Pinho* * Corresponding author < sheila@ibb.unesp.br> ; Martha Maria Mischan
UNESP/IB - Depto. de Bioestatística, C.P. 510 18618-970 Botucatu, SP - Brasil
ABSTRACT
In biologic experiments, in which growth curves are adjusted to sample data, treatments applied to the experimental material can affect the parameter estimates. In these cases the interest is to compare the growth functions, in order to distinguish treatments. Three methods that verify the equality of parameters in nonlinear regression models were compared: (i) developed by Carvalho in 1996, performing ANOVA on estimates of parameters of individual fits; (ii) suggested by Regazzi in 2003, using the likelihood ratio method; and (iii) constructing a pooled variance from individual variances. The parametric tests, F and Tukey, were employed when the parameter estimators were near to present the properties of linear model estimators, that is, unbiasedness, normal distribution and minimum variance. The first and second methods presented similar results, but the third method is simpler in calculations and uses all information contained in the original data.
Key words: logistic model, treatments comparison
RESUMO
Em experimentos biológicos, em que curvas assintóticas de crescimento são ajustadas a resultados amostrais, o padrão de crescimento pode ser afetado por tratamentos aplicados ao material experimental. Nesses casos há interesse em comparar as diferentes funções de crescimento, com o objetivo de diferenciar os tratamentos. Compararam-se três métodos de verificação de igualdade de parâmetros em modelos de regressão não-linear: (i) desenvolvido por Carvalho em 1996, o qual realiza análises de variância com estimativas dos parâmetros resultantes de ajustamentos do modelo em cada unidade experimental; (ii) sugerido por Regazzi em 2003, utilizando o método da razão da máxima verossimilhança; e (iii) construindo uma variância conjunta a partir das variâncias individuais das estimativas dos parâmetros obtidas nos ajustamentos do modelo. Os testes F e Tukey foram empregados quando foi possível considerar os estimadores dos parâmetros com propriedades próximas às dos estimadores de modelos lineares, isto é, não-tendenciosidade, distribuição normal e variância mínima. Os dois primeiros métodos apresentaram resultados semelhantes quanto à discriminação dos tratamentos; o terceiro método diferiu dos anteriores, mas tem a vantagem de apresentar simplicidade nos cálculos, além de utilizar toda a informação contida nos dados originais.
Palavras-chave: modelo logístico, comparação de tratamentos
Introduction
In biologic studies growth curves have many important applications and the description and comparison among them by regression models is an efficient quantitative method. Linear and nonlinear functions have been adjusted to data in many studies involving experiments comprising several treatments. In these cases the objective is to verify differences among treatments according to the adjusted curves.
To make these comparisons parametric methods have been employed in which growth curves are adjusted to each experimental unit to obtain parameter estimates and conduct an analysis of variance. In relation to nonlinear regression models, Carvalho (1996) worked with logistic and Gompertz functions, Whyte and Woollons (1990) with Gompertz, Santos et al. (1999) used the Weibull model and comparing two groups utilizing t-test; with respect to linear models, among others, there is the work of Meredith and Stehman (1991), adjusting polynomial models and comparing treatments. Treatment comparisons may be made through the Tukey-test, as in Carvalho (1996), or t-test as in Santos et al. (1999), or using a regression analysis for treatments as levels of a quantitative factor (Meredith and Stehman, 1991).
The objective of the present study was to compare some methods that verify if a certain parameter of a nonlinear regression presents constant values in two or more treatments.
Material and Methods
Fresh weight Phaseolus vulgaris L. cv. Carioca SH seed data (y), from an experiment described in Carvalho (1996), were used to illustrate the methods here employed. The beans were imbibed in mannitol solutions with eight different osmotic potentials: po = {0, 3, 6, 9, 12, 15, 18, 21 bar}; these potentials were the treatments to be compared. The experiment had two replicates and ten time points of observation: x = {0, 1, 2, 3, 4, 5, 7, 9, 12, 15 hours}, totalizing 160 observations.
The logistic regression model: y = α [1-β exp(-γ x)]_1, with α, β and γ as parameters, was adjusted to the data of each treatment. In order to compare the effects of a treatment on the parameter estimates, three methods described below were employed.
Method 1 (m1): Carvalho (1996) presented a method for comparison of logistic and Gompertz parameters using parametric tests. As described in Bates and Watts (1988) an important requirement to establish confidence intervals and regions of parameters in nonlinear models, using linear approximation, is that the expected surface in the parametric space should be flat so that the tangent plane would give a precise approximation. There are nonlinear relative curvature measures (C) that can be utilized to indicate if the linear approximate in a particular case is adequate. Curvatures are considered little when their measures are smaller than the circle 95% confidence, that is, if C ≤ 1 /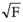 or if C ≤ 1, where F = F(P, N - P; 0.05), with P = number of parameters of the model and N = number of data pairs. An expected surface with radius 1/C is considered, and the deviation of the surface from the tangent plane at a distance from the tangent point is determined. This deviation is expressed as a percentage of the confidence radius of the circle, and is 100
or if C ≤ 1, where F = F(P, N - P; 0.05), with P = number of parameters of the model and N = number of data pairs. An expected surface with radius 1/C is considered, and the deviation of the surface from the tangent plane at a distance from the tangent point is determined. This deviation is expressed as a percentage of the confidence radius of the circle, and is 100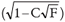 /C. If C ≤ 1 / = 0.1, then the deviation from the surface is 5%, if C ≤ 1 / = 0.2, the deviation is 10%, and if C ≤ 1 / = 0.3, is 15%. Consequently, the analysis is adequate if the curvature C is ≤ 0.3.
/C. If C ≤ 1 / = 0.1, then the deviation from the surface is 5%, if C ≤ 1 / = 0.2, the deviation is 10%, and if C ≤ 1 / = 0.3, is 15%. Consequently, the analysis is adequate if the curvature C is ≤ 0.3.
In the present study the logistic function was adjusted to each experimental unit, and the Bates and Watts curvature measures, that is, the intrinsic nonlinearity and the parameter-effect nonlinearity, were calculated. When the measures were below 0.3, and the basic assumptions of the analysis of variance were satisfied, each model parameter was analyzed; afterwards the differences between treatments were verified by the Tukey method. Because the logistic was adjusted to each experimental unit there were 16 fitted functions, each with ten pairs {x,y} and, therefore, seven degrees of freedom (df) for the mean square error. The analysis of variance of the resulting estimated parameters had therefore 16 values classified as eight treatments and two replicates; here there were eight df for the mean square error.
Method 2 (m2): Regazzi (1993) considered the adjustment of H polynomial regression equations of degree k, employing orthogonal polynomials techniques. He presented, in detail, a method to test the following hypotheses: (a) H0: the H equations are identical; (b) H0: the H equations have a common regression constant; (c) H0: the H equations have one or more equal regression coefficients. This author concluded by the generality of the method, and that it can be used in polynomial models of any degree, orthogonal or not, and also in multiple regression models. Regazzi (2003) considered the adjustment of g nonlinear regression equations (g groups), with the objective to present an adequate methodology to test the following hypotheses, employing the likelihood ratio test: (a) H0: the g equations are identical, that is, a common equation can be used as an estimate of the g considered equations; and (b) H0: a determined subset of parameters is equal.
The following models were adjusted: Ω = unrestricted model, where the three parameters are adjusted to each treatment; w1 = restricted model, where the α parameter is common to all treatments; this model is verified by the hypothesis H0(1); w2 = restricted model, where the β parameter is common to all treatments; this model is verified by the hypothesis H0(2); w3 = restricted model, where the γ parameter is common to all treatments; this model is verified by the hypothesis H0(3); w4 = restricted model, where the α and γ parameters are common to all treatments; this model is verified by the hypothesis H0(4); w5 = restricted model, where the β and γ parameters are common to all treatments; this model is verified by the hypothesis H0(5); w6 = restricted model, with all parameters common to all treatments; this model is verified by the hypothesis H0(6). These hypotheses are mathematically described in Table 2.
Method 3 (m3): The nonlinear regression model was adjusted to each treatment and the parameter estimates θi, i = 1,..., P, P = 3, their asymptotic variances and their direct measures of skewness of Hougaard (1985), g1i, were obtained. With ten time points and two replicates there were 20 pairs {x,y}, therefore with 17 df for the mean square error. As a result of the logistic fitting there were eight estimated parameters and corresponding estimated variances. The comparison between two α-estimates L = 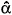 i - j , i, j = 1,...,8, i ≠ j, is then considered.
i - j , i, j = 1,...,8, i ≠ j, is then considered.
A description of the Hougaard method to obtain these measures of skewness can be found in Ratkowsky (1989); this author classified the measures as follows: if |g1i|< 0.1, the estimator 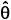 i of parameter θi has a very close-to-linear behavior; if 0.1 < |g1i| < 0.25, the estimator is reasonably close-to-linear; if |g1i| ≥ 0.25, the skewness is very apparent; and if |g1i| >1 this indicates a considerable nonlinear behavior. This terminology, `close-to-linear', according to Ratkowsky (1989), refers to nonlinear regression models with estimators near to present the properties of linear models estimators, that is, unbiasedness, normal distribution and minimum variance. Consequently, considering the adjustments with low Hougaard measures, the parameter estimates were compared through the Tukey test, using the estimates of their variances.
i of parameter θi has a very close-to-linear behavior; if 0.1 < |g1i| < 0.25, the estimator is reasonably close-to-linear; if |g1i| ≥ 0.25, the skewness is very apparent; and if |g1i| >1 this indicates a considerable nonlinear behavior. This terminology, `close-to-linear', according to Ratkowsky (1989), refers to nonlinear regression models with estimators near to present the properties of linear models estimators, that is, unbiasedness, normal distribution and minimum variance. Consequently, considering the adjustments with low Hougaard measures, the parameter estimates were compared through the Tukey test, using the estimates of their variances.
Results and Discussion
Method 1 - The measures of intrinsic nonlinearity and parameter effect were all smaller than 0.3, consequently the logistic model was considered with low departures from linearity. The analysis of variance on a-estimates presented a treatment mean square of 0.00836, a mean square error of 0.000113, and the F-value was 73.96 (p < 0.001). The Tukey test was used to compare treatment effects on α-estimates, with the value of 0.0421 as a test criterion (q = 5.596).
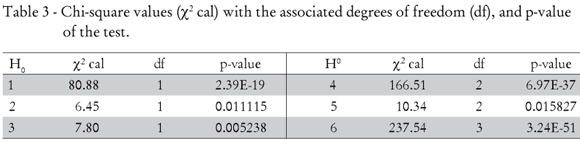
Method 2 - The results of the adjusted models are presented in Tables 1 to 3 .
Method 3 - The logistic model adjusted to each treatment data resulted in the estimates of the α parameter presented in Table 4. The g1 values are all near 0.1, therefore the models were considered as close-to-linear models. The eight variance estimates of α-estimates may be considered homogeneous in accordance to the Bartlett test, with χ2 = 2.75, 7 df, then an average variance was calculated, s2 = 0.000297, with 136 df. This estimated variance can be used in tests, as Tukey test to compare different α-estimates; the calculated Tukey minimum significant difference was 0.0750 (q = 4.352). See Table 5 that includes also the results of the other two methods.
The conclusions about differences among treatment effects were the same for methods 1 and 2. The different conclusions between methods 1 and 3 may be attributed to different errors used as a base for the tests. With method 1 a regression analysis was performed on each experimental unit, then a data set of ten values was used, with seven df in error; from these analyses, 16 estimates of α-parameter are obtained, that were submitted to the analysis of variance with eight treatments and two replications, and an error degree of freedom of 8 is obtained. These α-estimates, however, have already a variance with seven df for method 1 and 20-3 = 17 df for method 3, because the latter uses a data set with 20 pairs to perform a single regression per treatment. This additional information is used by method 3 in order to obtain the average variance with 136 df.
The estimated average variance employed by method 3 is also a base to verify the significance of a simple linear regression model relating the α-estimates and the potential (treatment) values; this is more appropriate than the Tukey test before performed, because the treatments are quantitative level factors. The estimated regression equation is =2.02640.00869*po, with po = potential values, a 5% significant model, with determination coefficient R2 = 0.976. Figure 1 represents the regression model.
Conclusions
Method 1 (Carvalho, 1996) and method 2 (Regazzi, 2003) presented similar results; however method 3 had less significant differences. Nevertheless, method 3 is simpler in calculations and uses all information contained in the original data.
Acknowledgements
To the program "CAPES Pró-Equipamentos nº 1, 01/2007" by the equipments provided.
Received September 02, 2008
Accepted October 05, 2009
- Bates, D.M.; Watts, D.G. 1988. Nonlinear regression analysis and its applications. John Wiley, New York, NY, USA. 365p.
- Carvalho, L.R. Métodos para comparação de curvas de crescimento. 1996. Dr. Thesis. UNESP/FCA, Botucatu, SP. Brazil. (In Portuguese, with Summary in English).
- Hougaard, P. 1985. The Appropriateness of the asymptotic distribution in a nonlinear regression model in relation to curvature. Journal of the Royal Statistical Society, Serie B 47: 103-114.
- Meredith, M.P.; Stehman, S.V. 1991. Repeated measures experiments in forestry: focus on analysis of response curves. Canadian Journal of Forest Research 21: 957-965
- Ratkowsky, D.A. 1989. Handbook of Nonlinear Regression Models. Marcel Dekker, New York, NY, USA. 241p.
- Regazzi, A.J. 1993. Teste para verificar a identidade de modelos de regressão e a igualdade de alguns parâmetros num modelo polinomial ortogonal. Revista Ceres 40: 176-195.
- Regazzi, A.J. 2003. Teste para verificar a igualdade de parâmetros e a identidade de modelos de regressão não-linear. In: Reunião da RBRAS 48. Lavras, MG, Brazil.
- Santos, S.A.; Souza, G.S.; Oliveira, M.R.; Sereno, J.R.B. 1999. Using nonlinear models to describe height growth curves in Pantaneiro horses. Pesquisa Agropecuária Brasileira 34: 1133-1138.
- Whyte, A.G.D.; Woollons, R.C. 1990. Modeling stand growth of radiata pine thinned to varying densities. Canadian Journal of Forest Research 20: 1069-1076.
Publication Dates
-
Publication in this collection
26 Apr 2010 -
Date of issue
Apr 2010
History
-
Accepted
05 Oct 2009 -
Received
02 Sept 2008





