Abstract:
In this paper we present the first results of the application of computational methods, inspired by the ideas in McMahon & McMahon (2005), to a dataset collected from languages of every branch of the Tupian family (including all living non-Tupí-Guaraní languages) in order to produce a classification of the family based on lexical distance. We used both a Swadesh list (with historically stabler terms) and a list of animal and plant names for results comparison. In addition, we also selected more (HiHi) and less (LoLo) stable terms from the Swadesh list to form sublists for indepedent treatment. We compared the resulting NeighborNet networks and neighbor-joining cladograms and drew conclusions about their significance for the current understanding of the classification of Tupian languages. One important result is the lack of support for the currently discussed idea of an Eastern-Western division within Tupí.
Keywords:
Tupian family; Distance-based methods; Historical linguistics; Internal classification; Lexical sublists.
Resumo:
Neste trabalho, apresentamos os primeiros resultados da aplicação de métodos comparativos computacionais, inspirados nas ideias de McMahon & McMahon (2005), a um conjunto de dados de línguas de todos os ramos da família Tupí (incluindo-se todas as línguas não-Tupí-Guaraní ainda vivas), com o intuito de produzir uma classificação da família com base em distância lexical. Usamos uma lista de Swadesh (composta por termos historicamente mais estáveis) e uma lista de nomes de plantas e animais para comparação de resultados. Além disso, também selecionamos os termos mais (HiHi) e menos (LoLo) estáveis da lista de Swadesh para formar sublistas para tratamento independente. Comparamos as redes NeighborNet e os cladogramas neighbor-joining resultantes, derivando conclusões sobre o seu impacto na compreensão atual da classificação das línguas Tupí. Um importante resultado é a falta de apoio para a ideia, atualmente em discussão, da existência de uma divisão leste-oeste dentro da família.
Palavras-chave:
Família Tupí; Métodos de distância; Linguística histórica; Classificação interna; Sublistas lexicais.
INTRODUCTION
The Tupian family is one of the largest linguistic groups of South America, composed of about 40-45 languages that are traditionally classified into ten branches: Arikém, Awetí, Jurúna, Mawé, Mondé, Mundurukú, Puruborá, Ramaráma, Tuparí, and Tupí-Guaraní. Five of these branches (Arikém, Ramaráma, Puruborá, Mawé, and Awetí) are composed each of a single living language today. On the other extreme, Tupí-Guaraní is the largest and most widespread group, with 22 living languages and around 40 dialectal variants that are spoken in an extensive geographical area covering a large part of Brazil and adjacent regions in Argentina, Paraguay, Peru, Bolivia, and French Guiana (Moore; Galucio; Gabas Jr., 2008MOORE, Denny; GALUCIO, Ana Vilacy; GABAS JÚNIOR, Nilson. O desafio de documentar e preservar as línguas amazônicas. Scientific American Brasil, p. 36-43. 2008. (Amazônia - A Floresta e o Futuro). Edição especial 3.). The Jurúna and Mundurukú branches have two languages each, which are very closely related in both cases. Thus, besides Tupí-Guaraní, the Mondé (three languages and several dialects) and Tuparí (five languages) are the only two branches still maintaining a greater internal diversity.
The internal classification of the Tupian language family that has emerged in recent years is presented schematically in Figure 1. The depicted tree departs from the ten branches previously assigned to the family (Rodrigues, 1984/85; Rodrigues; Cabral, 2012). It shows the results of more recent studies that propose intermediary stages in the derivation from Proto-Tupí and the internal classification of the branches, according to the application of the Comparative Method and the analysis of reoccurring sound change patterns (Drude, 2006DRUDE, Sebastian. On the position of the Awetí language in the Tupí family. In: DIETRICH, Wolf; SYMEONIDIS, Haralambos (Ed.). Guaraní y "Mawetí-Tupí-Guaraní": Estudios históricos y descriptivos sobre una familialingüística de América del Sur. Berlim: LIT Verlag, 2006. p. 47-68.; Fargetti; Rodrigues, 2008FARGETTI, Cristina M.; RODRIGUES, Carmen L. Consoantes do xipaya e do juruna: uma comparação em busca do proto-sistema. Alfa, v. 52, n. 2, p. 535-563, 2008.; Gabas Júnior, 2000; Galucio; Gabas Júnior, 2002GALUCIO, Ana Vilacy; GABAS JÚNIOR, Nilson. Evidências de agrupamento genético Karo-Puruborá, tronco Tupi. In: XVII Encontro Nacional da ANPOLL: boletim informativo, 2002, Gramado: ANPOLL. v. 31. p. 163.; Galucio; Nogueira, 2012; Meira; Drude (this volume); Moore, 2005MOORE, Denny. Classificação interna da família lingüistica Mondé. Estudos Linguísticos, v. 34, p. 515-520. 2005.; Moore; Galucio, 1994; Picanço, 2005PICANÇO, Gessiane. Mundurukú: phonetics, phonology, synchorny, diachrony. Ph.D. dissertation, University of British Columbia, Canada, 2005., 2010; Rodrigues, 2005, 2007; Storto; Baldi, 1994STORTO, Luciana; BALDI, Philip. The Proto-Arikém vowel shift. In: INTERNATIONAL CONGRESS OF THE LINGUISTIC SOCIETY OF AMERICA. 1994. Annals... 1994. p. 1-13.). A large part of these studies reflect the results of the ongoing Tupí Comparative Project at the Museu Paraense Emilio Goeldi, in cooperation with Tupian specialists from various institutions, since 19981 1 The permanent members of the initial Tupí Comparative Project are Ana Vilacy Galucio for the Puruborá and Tuparí branches; Carmen Rodrigues for the Jurúna branch; Denny Moore for the Mondé branch; Gessiane Picanço for the Mundurukú branch; Luciana Storto for the Arikém branch; Nilson Gabas Jr. for the Ramaráma branch; Sebastian Drude for the Awetí branch; and Sérgio Meira for the Mawé and Tupí-Guaraní branches. Other members that have collaborated with specific languages include Didier Demolin and Fernanda Nogueira for Wayoró, and Mariana Lacerda for Suruí of Rondônia. .

Five of the ten Tupian branches (Arikém, Mondé, Ramaráma, Puruborá, and Tuparí) are spoken exclusively in the area corresponding to the current state of Rondônia (Brazil), in a region that has been proposed as the original homeland of the Tupian languages and peoples due to the great time depth of Tupian ethnolinguistic diversity there (Métraux, 1928MÉTRAUX, Alfred. La civilisation matérielle des tribus Tupi-Guarani. Paris: Paul Geuthner, 1928.; Rodrigues, 1964RODRIGUES, Aryon D. A classificação do tronco lingüístico Tupí., Revista de Antropologia v. 12, p. 99-104. 1964.; see also Wichmann; Müller; Velupillai., 2010WICHMANN, Søren; MÜLLER, André; VELUPILLAI, Viveka. Homelands of the world's language families: A quantitative approach., Diachronica v. 27, n. 2, p. 247-276. 2010., p. 258)3 3 Wichmann et al. (2010) place the Tupian hypothetical homeland at 8°S, 62°W, which also corresponds to the same general area that has been previously proposed by other scholars (Métraux, 1928; Rodrigues, 1964). . The other five branches are spread across different regions4 4 The unit formed by Mawé, Awetí, and the Tupí-Guaraní branchs has been proposed as a single higher sub-branch, as shown in Figure 1 (Corrêa da Silva, 2007, 2010; Dietrich, 1990, Drude, 2006; Rodrigues, 1984/85; Rodrigues; Cabral, 2002; Rodrigues; Dietrich, 1997; Walker et al., 2012): the Mawé-Awetí-Tupí-Guaraní or “Mawetí-Guaraní” branch, a shortened form already used in Drude (2006), Meira (2006), and further in the present work. . Tupí-Guaraní is spoken in many parts of Brazil and some of its adjacent countries, while the other four are limited to distinct areas in Brazil: Awetí in the Parque Indígena do Xingu (State of Mato Grosso), Mawé in the lower Tapajós and Madeira rivers (Amazonas state), Jurúna (Jurúna branch) in the Parque Indígena do Xingu, Xipáya (Jurúna branch), traditionally spoken along the Xingu River, persists in the city of Altamira in the State of Pará, and Mundurukú in the middle Tapajós and Madeira rivers (in the states of Pará and Amazonas). Kuruáya, the second language in the Mundurukú branch, traditionally localized in the region of the Xingu River, was spoken in recent years in the city of Altamira by only three remaining elders, who have since passed away.
This paper presents the result of a first collaborative lexicostatistical and phylogenetic analysis applied to the entire Tupian family. The current trend in computational phylogenetics favors the so-called (Bayesian) character-based evolutionary methods (Dunn, 2015DUNN, Michael. Language phylogenies. In: BOWERN, Claire; EVANS, Bethwyn (Ed.) Routledge handbook of historical linguistics. London, New York: Routledge, 2015. p.190-211.), which have been highly successful in the investigation of linguistic relatedness (cf. Gray; Atkinson, 2003GRAY, Russell D.; ATKINSON, Quentin. Language-tree divergence times support the Anatolian theory of Indo-European origins. Nature, v. 426, p. 435-439. 2003. Available at: <doi.org/10.1038/nature02029>. Acessed on: Aug. 22, 2015.
https://doi.org/doi.org/10.1038/nature02...
; Gray; Drummond; Greenhill, 2009; Walker; Ribeiro, 2011WALKER, Robert S.; RIBEIRO, Lincoln A. Bayesian phylogeography of the Arawak expansion in lowland South America. Proceedings of the Royal Society, v. 278, n. 1718, p. 2562-2567. 2011.; Birchall; Dunn; Greenhill, to appear). This study follows an earlier distance-based methodology as outlined in McMahon, A.; McMahon, R. (2005) with some modifications. While distance-based methods have been gradually replaced with character-based ones in computational historical linguistics, given that statistical methods are relatively new to the field of Amazonian languages, it seemed interesting to us to start with one of the most familiar assumptions, namely that lexical distance between basic vocabulary items among related languages is an accurate approximation of phylogenetic relations. In subsequent papers, we will apply character-based methods in the hope that a comparison of their results with those of the distance-based methods and with the results of ongoing traditional historical-comparative studies on Tupian languages would not only shed more light onto and produce further insights into the history and classification of the Tupian family, but also provide further material for the (currently ongoing) discussion and comparison of the phylogenetic methods themselves.
We report here the first results and conclusions from the application of this methodology to data from all of the 17 currently spoken languages (plus two additional dialects) that constitute the nine Tupian branches outside of Tupí-Guaraní, including first-hand data for Akuntsú, Kuruáya, Puruborá and Salamãy, plus four Tupí-Guaranian languages. These results include (a) a classification of the whole family, (b) specific classifications of the more diverse branches (Tuparí, Mondé, Mawetí-Guaraní), and (c) conclusions on the differences observed with different (sub)sets of words (Tupí-HiHi vs. Tupí-LoLo sublists, animal and plant names vs. Swadesh list) are used as the input for our statistical analyses. In addition to contributing to ongoing discussions on the classification and history of Tupian languages, our results also suggest that the use of semantically-based sets of words is a strategy worth investigating, which we intend to do in future work.
DATA AND METHODS
This study followed the methodology outlined in McMahon. A.; McMahon, R. (2005), with a few modifications discussed below. First, a sample of 23 Tupí languages was chosen, consisting of four Tupí-Guaraní languages and 19 varieties from the other Tupian branches: the 17 existing non-Tupí-Guaraní languages, plus three dialects of the same language (Zoró, Aruá and Gavião are mutually intelligible). In the cases of Akuntsú, Kuruáya, Puruborá and Salamãy, first-hand unpublished data was used (see the Appendix APPENDIX 1: SWADESH'S 100-WORD LIST The meaning, with its number in the list, is given in boldface capitals. The specific words, retranscribed from their original sources with IPA symbols (note that acute and grave accents mark tone, not stress, and that long vowels are represented by sequences of identical vowels: aa, oo, etc.; a dot, used only when necessary, marks a syllable boundary), are presented under the meaning, in italics, preceded by a two-letter abbreviation indicating the source language. Initial hyphens (indicating that the word takes a prefix) are copied from the original sources. Words assumed to be cognate (fully or partially) are listed sequentially, separated by commas, forming a cognate set; the end of a cognate set is indicated by two vertical strokes (||). If for a given meaning a language has variants or synonyms, they are indicated after the language abbreviation, separated by commas; if a word has conditioned alternants, these are separated by a tilde (~). A segment enclosed in parenthesis is not always pronounced. For each meaning, cognate sets are presented in order of decreasing size. Missing words are marked by question marks after the language abbreviation, at the end, after all cognate sets. Given the incipent stage of knowledge about Proto-Tupí and its historical development, our cognacy judgments in this paper are preliminary, based on our experience with the languages and with our current hypotheses about their sound changes; some of them will probably change in the future. Methodologically, we decided to err on the side of inclusiveness: if only part of a word is cognate (p.ex., Portuguese nós and the first syllable of Spanish nosotros, both meaning 'we'), we still counted it as a full cognate. Language abbreviations: Ak = Akuntsú, Ar = Aruá, Aw = Awetí, Gv = Gavião, Ju = Jurúna, Ka = Káro, Kt = Karitiána, Ku = Kuruáya, Ma = Makuráp, Me = Mekéns, Mu = Mundurukú, Mw = Mawé, Pg = Paraguayan Guaraní, Pt = Parintintín, Pu = Puruborá, Sa = Salamãy, Su = Suruí, Ta = Tapirapé, Tu = Tuparí, Uk = Urubú-Ka'apór, Wa = Wayoró, Xi = Xipáya, Zo = Zoró ). The Tupí-Guaraní branch was represented by only four languages (Urubú-Ka'apór, Paraguayan Guaraní, Tapirapé, and Parintintín) because, even though the internal classification of this branch has not reached consensus among specialists (cf. Mello, 2000MELLO, Augusto A. S. Estudo histórico da família lingüística Tupí-Guaraní: aspectos fonológicos e lexicais. Ph.D. dissertation, Universidade Federal de Santa Catarina, Florianópolis, 2000., 2002; Rodrigues; Cabral, 2002RODRIGUES, A. D.; CABRAL, A. S. A. C. Revendo a classificação interna da família Tupí-Guaraní. In: CABRAL, A. S. A. C.; RODRIGUES, A. D. (Eds.). Línguas indígenas brasileiras: Fonologia, gramática e história. Atas do I Encontro Internacional do Grupo de Trabalho sobre Línguas Indígenas da ANPOLL., Belém: EDUFPA 2002. p. 327-338.; Schleicher, 1998SCHLEICHER, Charles Owen. Comparative and internal reconstruction of the Tupi-Guarani language family. Ph.D. dissertation, University of Wisconsin, Madison, 1998.), it is a well-established branch. The Tupí-Guaraní, languages are so closely related to each other to the point that one may wonder whether many of them are languages or actually dialects of each other. Thus, even if there is a possibility on the contrary, we assumed that Tupí-Guaraní languages would not significantly influence the classification of other, much less closely related, Tupian languages5 5 In addition, there already is a more in-depth study of Tupí-Guaraní interrelations with phylogenetic (Bayesian) methods (Michael et al., to appear). .
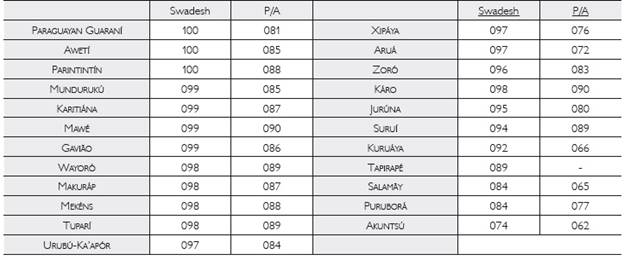
A list of 100 diagnostic meanings, considered to be more stable over time and less subject to cultural influences (the Swadesh list, as given in McMahon, A.; McMahon, R. (2005), originally proposed in Swadesh (1955), with a few minor adaptations; e.g., since there usually are two first person plural pronouns, Swadesh's third item, we, was changed to we-Inclusive), was compiled for these languages from the available sources for the Tupí-Guaraní languages (Almeida et al., 1983ALMEIDA, Antônio; JESUS, Irmãzinhas de; PAULA, Luíz Gouvêa de. A língua Tapirapé. Rio de Janeiro: Xerox do Brasil. 1983.; Betts, 1981BETTS, La Vera D. Dicionário Parintintin-Português, Português-Parintintin. Cuiabá: Sociedade Internacional de Linguística. 1981.; Cadogan, 1992CADOGAN, León. Diccionario Mbya-Guarani - Castellano. Asunción: Fundación "León Cadogan", 1992. (Biblioteca Paraguaya de Antropología, 17).; Dooley, 1998DOOLEY, Robert A. Léxico Guaraní, dialeto Mbya: versão para fins acadêmicos. Porto Velho: Sociedade Internacional de Linguística. 1998.; Guasch; Ortiz, 1996GUASCH, Antonio; ORTIZ, Diego. Diccionario Castellano-Guaraní, Guaraní-Castellano, 13th ed. Asunción: Centro de Estudios Paraguayos "Antonio Guasch" (CEPAG), 1996.; Kakumasu, J.; Kakumasu, K., 2007KAKUMASU, James Y.; KAKUMASU, Kiyoko. Dicionário por tópicos Kaapor-Português. Cuiabá: Associação Internacional de Lingüística - SIL Brasil. 2007.; Lopes, 2009LOPES, Mario Alexandre Garcia. Aspectos gramaticais da língua Ka'apor. Ph.D. dissertation, Universidade federal de Minas Gerais, Belo Horizonte, 2009.; Praça, 2007PRAÇA, Walkíria N. Morfossintaxe da língua Tapirapé (Família Tupi-Guaraní). Ph.D. dissertation, Universidade de Brasília, Brasília, 2007.) and field data collected by the authors (all the other languages). A similar list of 90 plant and animal names was also collected for comparative analysis with the results from the Swadesh list (see further details below). Inevitably, there were gaps due to missing words in the available data. The number of attested words per language in the sample is indicated in Table 1; the word lists and our cognacy judgments are given in the Appendix (Swadesh list in Appendix 1 APPENDIX 1: SWADESH'S 100-WORD LIST The meaning, with its number in the list, is given in boldface capitals. The specific words, retranscribed from their original sources with IPA symbols (note that acute and grave accents mark tone, not stress, and that long vowels are represented by sequences of identical vowels: aa, oo, etc.; a dot, used only when necessary, marks a syllable boundary), are presented under the meaning, in italics, preceded by a two-letter abbreviation indicating the source language. Initial hyphens (indicating that the word takes a prefix) are copied from the original sources. Words assumed to be cognate (fully or partially) are listed sequentially, separated by commas, forming a cognate set; the end of a cognate set is indicated by two vertical strokes (||). If for a given meaning a language has variants or synonyms, they are indicated after the language abbreviation, separated by commas; if a word has conditioned alternants, these are separated by a tilde (~). A segment enclosed in parenthesis is not always pronounced. For each meaning, cognate sets are presented in order of decreasing size. Missing words are marked by question marks after the language abbreviation, at the end, after all cognate sets. Given the incipent stage of knowledge about Proto-Tupí and its historical development, our cognacy judgments in this paper are preliminary, based on our experience with the languages and with our current hypotheses about their sound changes; some of them will probably change in the future. Methodologically, we decided to err on the side of inclusiveness: if only part of a word is cognate (p.ex., Portuguese nós and the first syllable of Spanish nosotros, both meaning 'we'), we still counted it as a full cognate. Language abbreviations: Ak = Akuntsú, Ar = Aruá, Aw = Awetí, Gv = Gavião, Ju = Jurúna, Ka = Káro, Kt = Karitiána, Ku = Kuruáya, Ma = Makuráp, Me = Mekéns, Mu = Mundurukú, Mw = Mawé, Pg = Paraguayan Guaraní, Pt = Parintintín, Pu = Puruborá, Sa = Salamãy, Su = Suruí, Ta = Tapirapé, Tu = Tuparí, Uk = Urubú-Ka'apór, Wa = Wayoró, Xi = Xipáya, Zo = Zoró , plant and animal names in Appendix 2 APPENDIX 2: LIST OF PLANT AND ANIMAL NAMES The list below contains all animal and plant names used in this paper. It follows the same conventions as the Swadesh list in Appendix 1, with only two differences: due to lack of relevant data in our sources, Tapirapé was eliminated and Paraguayan Guaraní was here replaced by another dialect, Mbyá Guaraní (abbreviated below as Mg). ).

The cognacy judgments reflect our consensus opinion for each set of words having the same translation, which we divided into subsets consisting only of (to the best of our judgment) cognate words. For instance, the words for 'I' (listed in Appendix 1 APPENDIX 1: SWADESH'S 100-WORD LIST The meaning, with its number in the list, is given in boldface capitals. The specific words, retranscribed from their original sources with IPA symbols (note that acute and grave accents mark tone, not stress, and that long vowels are represented by sequences of identical vowels: aa, oo, etc.; a dot, used only when necessary, marks a syllable boundary), are presented under the meaning, in italics, preceded by a two-letter abbreviation indicating the source language. Initial hyphens (indicating that the word takes a prefix) are copied from the original sources. Words assumed to be cognate (fully or partially) are listed sequentially, separated by commas, forming a cognate set; the end of a cognate set is indicated by two vertical strokes (||). If for a given meaning a language has variants or synonyms, they are indicated after the language abbreviation, separated by commas; if a word has conditioned alternants, these are separated by a tilde (~). A segment enclosed in parenthesis is not always pronounced. For each meaning, cognate sets are presented in order of decreasing size. Missing words are marked by question marks after the language abbreviation, at the end, after all cognate sets. Given the incipent stage of knowledge about Proto-Tupí and its historical development, our cognacy judgments in this paper are preliminary, based on our experience with the languages and with our current hypotheses about their sound changes; some of them will probably change in the future. Methodologically, we decided to err on the side of inclusiveness: if only part of a word is cognate (p.ex., Portuguese nós and the first syllable of Spanish nosotros, both meaning 'we'), we still counted it as a full cognate. Language abbreviations: Ak = Akuntsú, Ar = Aruá, Aw = Awetí, Gv = Gavião, Ju = Jurúna, Ka = Káro, Kt = Karitiána, Ku = Kuruáya, Ma = Makuráp, Me = Mekéns, Mu = Mundurukú, Mw = Mawé, Pg = Paraguayan Guaraní, Pt = Parintintín, Pu = Puruborá, Sa = Salamãy, Su = Suruí, Ta = Tapirapé, Tu = Tuparí, Uk = Urubú-Ka'apór, Wa = Wayoró, Xi = Xipáya, Zo = Zoró ) were sorted out into three sets, one containing cognate words probably reconstructable as *on (perhaps *o-en) for Proto-Tupian, a second one with cognate words that suggest a form *uito, reconstructable at most for Proto-Mawetí-Guaraní, and a third one with reflexes of a form *iʃe at the Proto-Tupí-Guaraní level. For each pair of languages, the number of shared cognates was determined. Because of the gaps, the results were normalized to a 0-100 percentage scale7 7 For instance, suppose that, for two languages L1 and L2, respectively 90 and 80 meanings of the Swadesh list were found in the available data, and that only 75 of these were the same meanings in both languages; furthermore, suppose that, of these 75 pairs of synonymous words, only 60 pairs consisted of cognate words, in the authors’ judgment. In this case, the percentage of shared cognates between languages L1 and L2 would be 60/75 = .8 or 80%, which would be shown in Table 5 as 080. . This normalization has some consequences8 8 The normalization assumes that the missing items would have the same average cognacy rate as the known items, which is not necessarily the case. In fact, the languages with gaps of 8% or more and a small number of speakers have greater-than-average cognacy rates with languages outside of their branches (Akuntsú 37.8%, Kuruáya 35.2%, Salamãy 32.8%; Puruborá, with 30.4%, is the only one not above the average). For a possible explanation, see the final paragraph in the Section Similarity (shared cognates) matrix. . The results are given in Table 5 (Sec. 3 below).
For each meaning in the Swadesh list, a letter (A, B, C...) was assigned to each cognate set found in this meaning for each sampled language, as illustrated in Table 2. Languages that share a cognate for the same meaning are assigned the same letter for that meaning. For example, the letter C in the first meaning ('I') in Mundurukú, Akuntsú and Gavião, for instance, implies that these three languages have cognate words for 'I' (Mundurukú ṍn, Akuntsú õn, Gavião õõt). The cognate coding of Parintintín, for instance, is AAADCBAACCC..., while Akuntsú, in turn, has CBEFK??C??G... (where question marks represent missing words).
The complete version of Table 2 - a matrix of 23 cognate codings (one per language) x 100 meanings-was the basic input data for an analysis using SplitsTree (version 4.13.1, see Huson; Bryant, 2006HUSON, Daniel H.; BRYANT, David. Application of phylogenetic networks in evolutionary studies., Molecular Biology and Evolution v. 23, n. 2, p. 254-267. 2006. Available at: <Available at: www.splitstree.org
>. Acessed on: 30 jan. 2014.
www.splitstree.org...
), from which the program calculated distance (similarity) matrices on the basis of percentage of shared cognates, like Table 5 below, and then computed the equivalent diagrams. Network diagrams were produced with the NeighborNet algorithm (Bryant; Moulton, 2004), with the Variance parameter set to Ordinary Least Squares.
Since not all lexical evidence will point towards a single classification, the NeighborNet visualizations display the conflicting evidence ('conflicting phylogenetic signal') in the diagram through reticulations in the network. These reticulations help to visualize the 'tree-likeness' of the dataset and can result from gaps in the data and undetected borrowings, either between related or unrelated languages. This degree of conflicting signal can be quantified using a number of statistics, such as the δ-score (Holland et al., 2002HOLLAND, Barbara R.; HUBER, Katharina T.; DRESS, Andreas; MOULTON, Vincent. δ Plots: A tool for analyzing phylogenetic distance data., Molecular Biology and Evolution v. 19, n. 12, p. 2051-2059. 2002.).
Unrooted tree diagrams were computed using the neighbor-joining algorithm (Saitou; Nei, 1987SAITOU, Naruya; NEI, Masatoshi. The neighbor-joining method: a new method for reconstructing phylogenetic trees., Molecular Biology and Evolution v. 4, n. 4, p. 406-425. 1987.). Confidence estimates for every node were calculated on the unrooted tree via bootstrapping with 10,000 runs (i.e., 10,000 resamplings with replacement, yielding 10,000 trees; the confidence of every node in the optimal tree is the percentage of resampled trees where the node in question is present), as described in Kessler (2001KESSLER, Brett. The significance of word lists: statistical tests for investigating historical connections between languages. Stanford, CA: CSLI Publications, 2001.). The unrooted trees were rooted via midpoint rooting since no clear outgroup could be identified.
Since the rate of change is not constant across meanings even in basic vocabulary - certain items are more prone to change than others - we followed McMahon, A.; McMahon, R.'s (2005, p. 105) suggestion of compiling, within the larger Swadesh list, separate sublists of items that were more, or less, stable in time. On the basis of earlier work by Lohr (1999LOHR, Marisa. Methods for the genetic classification of languages. Ph.D. dissertation, University of Cambridge, Cambridge, 1999.); Starostin (2000STAROSTIN, Sergei. Comparative-historical linguistics and lexicostatistics. In: RENFREW, Colin; MCMAHON, April; TRASK, Larry (Ed.). Time depth in historical linguistics. Cambridge: McDonald Institute for Archaeological Research, 2000. p. 223-266.; see also Baxter; Ramer, 1996BAXTER, William H.; RAMER, Alexis Manaster. Review of Ringe (1992). Diachronica, v. 13, n. 2, p. 371-384. 1996. ), McMahon; McMahon (2005) set up two sublists, termed 'HiHi' and 'LoLo', with meanings that had been shown to have high reconstructibility (they had been reconstructed for at least three of the four proto-languages considered by Lohr) as well as high retentiveness (they had been replaced by other terms at most three times in Lohr's data). When compared to the Tupian data, however, these lists were clearly not suitable: many stable meanings in the 'HiHi' list, which had at most three replacements in Lohr's data, had eight or more cognate sets in Tupian, thus indicating at least seven replacements (e.g., 'two', 'long', 'night', 'star', 'stand'). It remains to be seen whether other language families would also disagree with Lohr's list of meanings for high retentiveness and reconstructibility. If Tupian turns out not to be anomalous in this respect, then Lohr's (and McMahon's) hopes of possible cross-linguistic validity for their lists should be reexamined9 9 We note, in passing, that McMahon; McMahon’s (2005) success in applying Lohr’s (1999) and Starostin’s (2000) meaning lists probably stems from the fact that they were applied to Indo-European, which was one of the language families in both Lohr’s and Starostin’s databases, so that the meanings in question were indeed guaranteed to have high retentiveness and reconstructibility. .
To further examine stability in the Tupian data set, we compiled two lexical sublists, one with the most retentive meanings (those with four or fewer cognate sets, reflecting at most three replacements)10 10 The meaning ‘sun’ has five cognate sets, but because of what appears to be a mistake in the original Tapirapé source: the word is elsewhere attested as meaning ‘day’. Because of this, ‘sun’ is here included in the Tupí-HiHi list. and one with the least retentive meanings (those with at least nine cognate sets, reflecting at least eight replacements). To assess reconstructibility, the more retentive words were further inspected: those which, on the basis of our current knowledge of the family, seemed not to be reconstructable to Proto-Tupí were eliminated. The resulting lists, termed 'Tupí-HiHi' and 'Tupí-LoLo', are given in Tables 3 and 4.
A comparison with McMahon; McMahon's (2005) HiHi and LoLo lists reveals very little agreement: only ten out of their 30 HiHi meanings occurred also in our Tupí-HiHi list, and only two out of their 23 LoLo meanings occurred in our Tupí-LoLo list. One of the reasons for this surprising discrepancy is rather prosaic: McMahon and McMahon used Swadesh's 200-word list, while we used his 100-word list (more than half of their LoLo meanings are not in the 100-word list). More interestingly, though, some of Lohr's more retentive/reconstructable words could clearly not have the same status in Tupian: e.g., 'dog' was a new concept imported from Europe; 'four' and 'five' (often even 'three') are not lexicalized in all Tupian languages, where numeral systems are rather small11 11 Some Tupian languages have not a simple word but a complex expression for these numbers, sometimes even more than one expression in synchronic competition. ; 'other' is usually a word with more meanings besides 'other'; and, some terms ('night', 'star', 'day') tend to be related to or derived from others ('dark', 'moon', 'sun', respectively), often in various ways, depending on the language, which lowers their degree of retentiveness. To avoid these difficulties, we decided to adopt the Tupí-HiHi and Tupí-LoLo meanings (Tables 3 and 4) instead of those listed by McMahon; McMahon (2005)12 12 McMahon, A.; McMahon, R.’s HiHi list (2005, p. 109, Table 4.2) with 30 meanings: four, name, three, two, foot, give, long, salt, sun, other, sleep, to come, day, to eat, not, thin, five, mother, ear, I, new, night, one, to spit, star, to stand, though, tongue, tooth, wind. McMahon, A.; McMahon, R.’s LoLo list (2005, p.109, Table 4.2) with 23 meanings: grass, mouth, stone, heavy, year, bird, near, smooth, wing, man, neck, tail, to walk, back, to flow, left (hand), to pull, to push, river, rope, straight, to think, to throw. . New matrices were then prepared for the Tupí-HiHi and and Tupí-LoLo sublists, from which networks and cladograms with confidence estimates were produced for comparison with those resulting from the whole Swadesh list (1955)13 13 Holman et al,. (2008) have also published a list of meanings ranked by stability, based on a large (800+) sample of languages. There is a high degree of corelation between Holman’s list and ours (preliminary results based on a suggestion by one of the referees to this paper show a Spearmann rank corelation of -0.50 with p < 0.0000001, without any radical outliers visible on a plot of Holman ranks vs. meanings), which means that our choice to use a Tupí-internal stability ranking is not expected to produce significantly different results from an analysis based on Holman’s rankings. We hope to investigate, in future studies, the idea of a universal stability ranking and to examine possible family-specific ranking deviations for particular meanings. .
Finally, a final list of words was compiled that consists of 90 names of animals and plants (listed in Appendix 2 APPENDIX 2: LIST OF PLANT AND ANIMAL NAMES The list below contains all animal and plant names used in this paper. It follows the same conventions as the Swadesh list in Appendix 1, with only two differences: due to lack of relevant data in our sources, Tapirapé was eliminated and Paraguayan Guaraní was here replaced by another dialect, Mbyá Guaraní (abbreviated below as Mg). ), where we expected to see the effects of borrowing more clearly. Due to insufficient data, the Paraguayan dialect of Guaraní was replaced by the Mbyá dialect, and Tapirapé was excluded from the set, reducing the total of language varieties taken into account to 22. The same procedure used for the Swadesh list, and the Tupí-HiHi and Tupí-LoLo sublists was again applied to the list of plants and animals, yielding more networks and trees (cladograms) for comparison.
RESULTS AND DISCUSSION
SIMILARITY (SHARED COGNATES) MATRIX
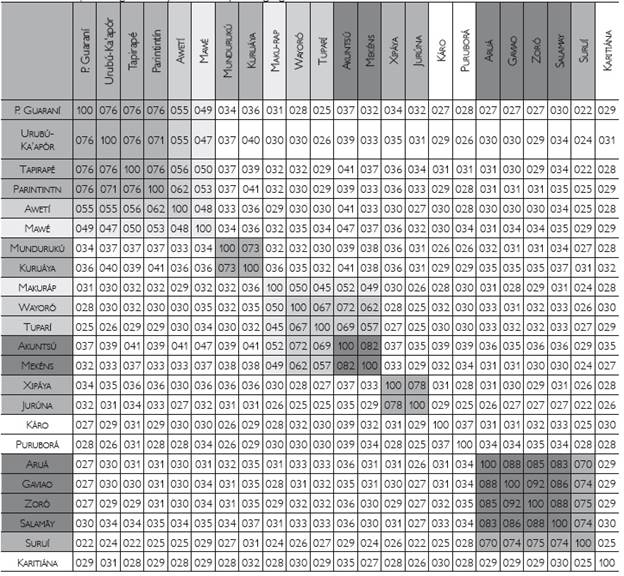
The lexical distance among each pair of languages in the sample is shown in the matrix consisting of percentages of pairwise shared cognates (Table 5), on the basis of which the first classification of the Tupian family, with data from all non-Tupí-Guaranian languages of the other nine branches of the family (including previously unavailable data on Akuntsú, Kuruáya, Puruborá and Salamãy), can be proposed.
A clear pattern emerges for the two larger branches found in the State of Rondônia, Mondé and Tuparí. The percentage of shared cognates in the Mondé branch confirms Moore's (2005MOORE, Denny. Classificação interna da família lingüistica Mondé. Estudos Linguísticos, v. 34, p. 515-520. 2005.) analysis of Gavião, Zoró and Aruá14 14 Cinta-Larga, another dialect, was not included in the sample. as dialects of one language. The proximity of Salamãy to these three languages may be an effect of the large gap - 16 missing items-in Salamãy data, as well as the ongoing obsolescence of this language. In this data set, Suruí (70%-75%) stands out as the most divergent language in the Mondé branch15 15 Another classification proposal by Anonby (2012) is not supported by the results from analysis put forth here. . In the Tuparí case, Mekéns and Akuntsú show similarly high percentages (82% shared cognates), which is not surprising if one takes into account that they are mutually intelligible and show very close phonological and morphological resemblances. In a brief paper on the classification of Akuntsú, Gabas Júnior (2005) left its status as a distinct language unresolved; the data set analyzed here suggests that Akuntsú and Mekéns are co-dialects of a single language. The other three languages are more lexically distant (45% to 72% shared cognates), Makuráp being the most divergent of the five.
Outside of Rondônia, the languages of the Tupí-Guaraní, Mundurukú and Jurúna branches all show percentages of more than 70% of shared cognates with the other languages of their respective branches. The highest rate, 78%, is found between the two Jurúna languages, Jurúna and Xipáya. Mundurukú and Kuruáya share 73% of their cognates, and the four Tupí-Guaraní languages in the sample show a rate of 71-76%16 16 The Tupí-Guaranian languages in the sample were taken from different subgroups, both in Mello´s (2000) and inRodrigues; Cabral´s (2002) classifications, and are almost as far away from each other as is possible to be within this branch. It would be interesting to see how many languages within each Tupí-Guaraní sub-branch would turn out to be better described as (co-)dialects if their percentage of shared cognates, their overall phonological and grammatical similarity, and their level of mutual intelligibility were compared. .
The closer relation between Tupí-Guaraní, Awetí, and Mawé is also very clear in Table 5, giving further support to the hypothesis of a Mawetí-Guaraní branch (Corrêa da Silva, 2007, 2010; Drude, 2006DRUDE, Sebastian. On the position of the Awetí language in the Tupí family. In: DIETRICH, Wolf; SYMEONIDIS, Haralambos (Ed.). Guaraní y "Mawetí-Tupí-Guaraní": Estudios históricos y descriptivos sobre una familialingüística de América del Sur. Berlim: LIT Verlag, 2006. p. 47-68.; Rodrigues, 1984/85; Rodrigues; Dietrich, 1997; Walker et al., 2012WALKER, Robert S.; WICHMANN, Soeren; MAILUND, Thomas; ATKISSON, Curtis J. Cultural phylogenetics of the Tupi language family in lowland South America. PLoS ONE, v. 7, n. 4, p. 1-9. 2012. ). A stepwise discontinuity can be observed in Table 5: starting with shared cognate percentages of 71%-76% among Tupí-Guaraní languages, there is a drop to 55%-62% with Awetí, a further drop to 47%-53% with Mawé, and a further drop to 22%-41% when one moves to the other Tupian branches17 17 One outstanding case is the 47% value found for Mawé and Akuntsú (Tuparí branch); but it is probably due, at least in part, to the gaps in the Akuntsú data (see Table 1). . Such clear-cut borders support the idea of a Mawetí-Guaraní branch, with the structure seen in Figure 1 above.
As a general effect, the results in Table 5 show the languages with few speakers (Akuntsú, Kuruáya, Puruborá, Salamãy, Xipáya) with systematically higher cognacy percentage than their closest related languages. Due to the situation of obsolescence of these languages, their respective word lists are less complete. The tendency in such cases is for semi-speakers and 'rememberers' to recall names of animals and other concrete items. It is highly probable that the forgotten meanings, for instance, 'today', 'there', 'four', involve items that are less likely to be cognates, leaving the more probable cognates in the recorded word list. Note that the semi-speakers usually know at least one other local Tupian language, which would make it more likely for cognate words not to be forgotten.
The network shows a low degree of reticulation, with a mean δ-score of 0.233 (s.d. ± 0.04). This suggests that there is a low degree of undetected borrowings in the dataset and that there are clearly identifiable branches within the network. In comparison, Gray et al. (2010GRAY, Russell D.; BRYANT, David; GREENHILL, Simon J. On the shape and fabric of human history. Philosophical Transactions of the Royal Society of London. Series B, Biological sciences, v. 365, n.1559, p. 3923-3933. 2010.) calculate the same statistic for other major language families of the world and find that Indo-European, which they consider to be highly tree-like and are using confident data based on centuries of etymological work, shows a δ-score of 0.22, while the Polynesian languages, which they consider highly reticulate, shows a δ-score of 0.41. In the Tupian dataset, the languages with δ-scores higher than the first standard derivation, which are the languages that contributed the most conflicting evidence to the tree-likeness of the dataset, are Kuruáya, Puruborá, Káro and Karitiána, with δ-scores of 0.288, 0.280, 0.311, and 0.313, respectively.
RELATEDNESS NETWORKS AND TREES
100-word Swadesh list
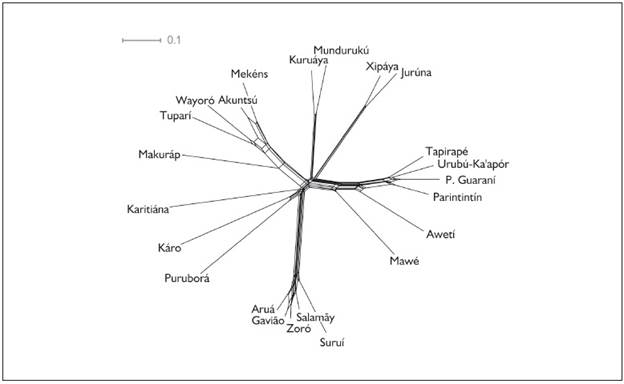
The shared cognate (similarity) matrix in Table 5 corresponds to the network in Figure 2, where the lexical distance between languages and the internal structure of each branch can be visualized.
The distance and ramifications of the branches, as shown in Figure 2, confirm the classifications based on the traditional comparative method (Corrêa da Silva, 2010; Fargetti; Rodrigues, 2008FARGETTI, Cristina M.; RODRIGUES, Carmen L. Consoantes do xipaya e do juruna: uma comparação em busca do proto-sistema. Alfa, v. 52, n. 2, p. 535-563, 2008.; Galucio; Nogueira, 2012GALUCIO, Ana Vilacy; NOGUEIRA, Fernanda. Comparative study of the Tupari branch of the Tupi family: contributions to understanding its historical development and internal classification. In: CONFERENCE ON INDIGENOUS LANGUAGES OF LATIN AMERICA, 5., 2012, Austin. Annals... Austin: Center for Indigenous Languages of Latin America (CILLA), 2012. p. 1-28. Available at: <Available at: http://www.ailla.utexas.org/site/events.html
>. Acessed on: Aug. 22, 2015.
http://www.ailla.utexas.org/site/events....
; Meira; Drude, this volume; Moore; Galucio, 1994MOORE, Denny; GALUCIO, Ana Vilacy. Reconstruction of Proto-Tupari Consonants and Vowels. In: MEETING OF THE SOCIETY FOR THE STUDY OF THE INDIGENOUS LANGUAGES OF THE AMERICAS AND THE HOKAN-PENUTIAN WORKSHOP, 1994, Berkeley. Annals... Berkeley: University of California, 1994. p. 119-137. ; Moore, 2005; Picanço, 2005PICANÇO, Gessiane. Mundurukú: phonetics, phonology, synchorny, diachrony. Ph.D. dissertation, University of British Columbia, Canada, 2005.; Rodrigues, 1984/85).

Network representation of lexical distance (NeighborNet algorithm) based on the 100-word Swadesh list.
The above results clearly support the higher-order branches in Figure 1. In one case, the support is barely significant: the Ramaráma-Puruborá branch (Káro and Puruborá languages), barely visible in Figure 2. The cladogram in Figure 3 evaluates its confidence as 71.9 (i.e., a Káro-Puruborá node occurred in 71.9% of the 10,000 resampling trees generated via bootstrapping)18 18 Figure 3 can be usefully compared to the tree in Figure 1 in Walker et al. (2012). That tree is based on fewer (40) items, less reliable data and a different distance-based method based on edit distance between corresponding lexical items. It differs in higher groupings and also in the internal classification of the branches. ; in comparison, the confidence of all other higher-order branches (Mondé, Tuparí, Mundurukú, Jurúna, Mawetí-Guaraní) is above 99%. Káro-Puruborá, or Ramaráma-Puruborá, proposed by Galucio; Gabas Júnior (2002GALUCIO, Ana Vilacy; GABAS JÚNIOR, Nilson. Evidências de agrupamento genético Karo-Puruborá, tronco Tupi. In: XVII Encontro Nacional da ANPOLL: boletim informativo, 2002, Gramado: ANPOLL. v. 31. p. 163.), does find some support here, albeit with a relatively low confidence level. Also note that Káro-Puruborá is placed as the closest relative to Mondé, albeit with very low confidence level (40.6%), which coincides with a proposal put forth in Rodrigues (2005RODRIGUES, Aryon. As vogais orais do Proto-Tupi. In: RODRIGUES, Aryon Dall'Igna; CABRAL, Ana Suelly Arruda Câmara (Ed.). Novos estudos sobre línguas indígenas. Brasília: Universidade de Brasília, 2005. p. 35-46.) for a subgrouping containing these three branches on the basis of the merger of *a and *o in these languages.
The Mawetí-Guaraní branch (Corrêa da Silva, 2010; Drude, 2006DRUDE, Sebastian. On the position of the Awetí language in the Tupí family. In: DIETRICH, Wolf; SYMEONIDIS, Haralambos (Ed.). Guaraní y "Mawetí-Tupí-Guaraní": Estudios históricos y descriptivos sobre una familialingüística de América del Sur. Berlim: LIT Verlag, 2006. p. 47-68.; Meira; Drude, this volume; Rodrigues, 1984/85; Rodrigues; Dietrich, 1997) is clearly identified in Figure 3, with an internal structure as was shown in Figure 1: Proto-Tupí-Guaraní (99.7% confidence) forms a higher-order branch with Awetí ("Awetí-Guaraní"; 99.0%), which then forms another higher-order branch with Mawé ("Mawetí-Guaraní"; 99.6%).

Midpoint-rooted neighbor-joining cladogram with confidence rates (calculated via bootstrapping) for the same data represented in the network in Figure 219 19 This cladogram refers not to the network in Figure 2, but to the best equivalent tree to that network, calculated with the neighbor-joining algorithm (Saitou and Nei, 1987) applied to the same data set. .
Figures 2 and 3 also confirm the proposed internal classification of the Mondé (Moore, 2005MOORE, Denny. Classificação interna da família lingüistica Mondé. Estudos Linguísticos, v. 34, p. 515-520. 2005.) and Tuparí (Galucio; Nogueira, 2012GALUCIO, Ana Vilacy; NOGUEIRA, Fernanda. Comparative study of the Tupari branch of the Tupi family: contributions to understanding its historical development and internal classification. In: CONFERENCE ON INDIGENOUS LANGUAGES OF LATIN AMERICA, 5., 2012, Austin. Annals... Austin: Center for Indigenous Languages of Latin America (CILLA), 2012. p. 1-28. Available at: <Available at: http://www.ailla.utexas.org/site/events.html
>. Acessed on: Aug. 22, 2015.
http://www.ailla.utexas.org/site/events....
) branches, originally based on phonological and morphological innovations and on mutual intelligibility. Within Mondé, Gavião and Zoró, closely related dialects, clearly form a subgroup (confidence 84.2%), to which Aruá and Salamãy are further added (confidence 83.8%). A subgroup including Aruá and Gavião-Zoró appears with confidence 60.9%, which, though suggestive, is still low and ultimately inconclusive20
20
Since bootstrapping involves random resampling, the confidence values usually change when evaluated again. Low confidence levels change more, since the status of the corresponding branch or subnetwork as contributing to the best solution is not robust and can be algorithm, or a few changes in the data.
; Salamãy, Aruá and Gavião-Zoró are probably best seen as co-dialects at the same level. Suruí is the last to join the Mondé branch, and probably the only variety different enough to be a separate language rather than a co-dialect of Gavião-Zoró-Aruá. The results are also different in some respects from the classification in Walker et al. (2012WALKER, Robert S.; WICHMANN, Soeren; MAILUND, Thomas; ATKISSON, Curtis J. Cultural phylogenetics of the Tupi language family in lowland South America. PLoS ONE, v. 7, n. 4, p. 1-9. 2012. ), generated by applying the ASJP method based on normalized edit distances to a 40-word vocabulary lists. They place Salamãy, called Mondé in their paper, as the most divergent language inside the Mondé branch, probably due to lack of more accurate data in this specific case. In the same vein, our results do not support their classification of Ramaráma as closer to Tuparí than to the Mondé branch.
In the Tuparí branch, the closer relation between Akuntsú and Mekéns is evident in Figures 2 and 3 (94.2% confidence), as is also the slightly less close relation between Tuparí and Wayoró (83.7% confidence). Mekéns-Akuntsú and Tuparí-Wayoró then join (99.1% confidence); Makuráp is the last to join, forming the Tuparí branch (99.9% confidence).
Attempts at producing higher-order branches by joining some of the aforementioned branches must be regarded as not supported by Figures 2 and 3. Even though the reticulation would tend to suggest connections, and the tree algorithm did select a higher-order branching hierarchy, the confidence values are so low (in the 28.1%-43.3% range) that these solutions must be unstable, dependent on small changes in cognacy judgment or even on the selection of different algorithms or parameter settings.
Tupí-HiHi and Tupí-LoLo sublists
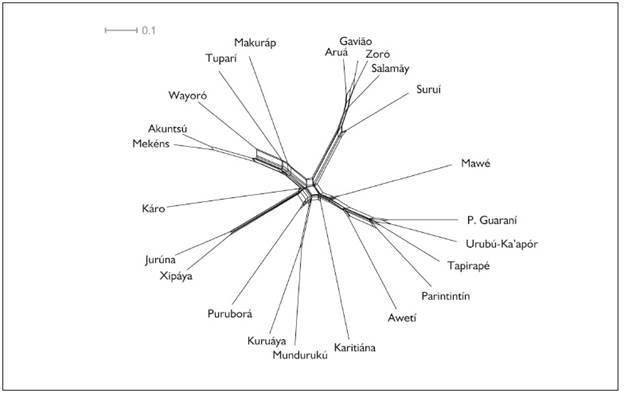
Turning now to the Tupí-HiHi and and Tupí-LoLo lists (see Tables 3 and 4 above), we obtain different networks, as shown below in Figures 4 and 5. Note that the main traditional branches (Mundurukú, Jurúna, Mondé, Tuparí, Mawetí-Guaraní) remain quite obvious in both figures; but the new Káro-Puruborá (Ramaráma-Puruborá) branch, which already had low confidence in Figure 3, is barely visible in Figure 4 and disappears in Figure 5 21 21 The network representation of lexical distance in the Tupí-HiHi list is only marginally more reticulate than that of the Tupí-LoLo list, i.e. is less tree-like, with δ-scores of 0.289 (s.d. ± 0.042) and 0.268 (s.d. ± 0.040), respectively. The statistical outliers in the Tupí-HiHi list are Akuntsú, Mekéns and Karitiána (δ = 0.352, 0.346, 0.373, respectively), while the outliers for the Tupí-LoLo list are Karitiána, Káro and Puruborá (δ = 0.324, 0.345, 0.361, respectively). . An interesting difference between these figures concerns the positions of Karitiána and of Jurúna-Xipáya. In Figure 4 (Tupí-HiHi), Karitiána appears between Mawetí-Guaraní and Mondé, while in Figure 5 (Tupí-LoLo) it is placed between Mawetí-Guaraní and Mundurukú. In Figure 2 (the whole Swadesh list), Karitiána appears between Tuparí and Káro. McMahon, A.; McMahon, R. (2005) suggest that such shifts in relative position are good indicators of contact-induced borrowings. The differences are small and need to be examined in more detail, but the results would tentatively suggest that Karitiána may have borrowed from other branches so as to become more similar to the other Rondônian languages (i.e., moving away from Mawetí-Guaraní). The Karitiána have borrowed multiple cultural traits, probably from long term contact with a group that did not belong to the Tupian family, such as a skull deformation apparatus, a horizontal mortar made of a carved tree trunk used with a rectangular stone for grinding corn and the tradition of eating corn porridge.

For Jurúna-Xipáya, the situation is the opposite of that of Karitiána: in Figure 4 (Tupí-HiHi), Jurúna-Xipáya appears closer to Mawetí-Guaraní (more so than in Figure 2), while in Figure 5 (Tupí-LoLo) it flips to the other side, ending up between Káro and Puruborá. This suggests (again tentatively) that Jurúna-Xipáya was originally closer to Mawetí-Guaraní and may have borrowed from other branches in past contacts. A possible connection between Jurúna-Xipáya and Mawetí-Guaraní (both members of a putative Eastern Tupian branch) has already been suggested (Rodrigues; Cabral, 2012RODRIGUES, Aryon; CABRAL, Ana Suelly. Tupían. In: CAMPBELL, Lyle; GRONDONA, Verónica (Eds.). The indigenous languages of South America: a comprehensive guide. Berlin; Boston: Walter de Gruyter, 2012. p. 495-574. ).

The basic structure of the subclassification of Mondé (Gavião-Zoró-Aruá-Salamãy vs. Suruí) is maintained, with Salamãy looking a little more distant from Gavião-Zoró-Aruá in Figure 5 (Tupí-LoLo list) and a little closer in Figure 4 (Tupí-HiHi). In Tuparí, on the other hand, there are more important differences: though the more distant relation of Makuráp to the rest of the branch remains visible, the close relationship between Akuntsú and Mekéns is clearer in Figure 5 (Tupí-LoLo) than in Figure 4 (Tupí-HiHi), where it would seem Akuntsú is at least as close (maybe even closer) to Wayoró-Tuparí as it is to Mekéns. This would tentatively suggest borrowing contacts between Akuntsú and Mekéns.
90-word plant and animal list
Turning now to the list of plant and animal names (see Appendix 2), which in principle should contain words that are less time-stable and more prone to borrowing and other areal influences, we find the results shown in the diagrams in Figures 6 and 7 below22 22 Note that, as said before, Tapirapé was eliminated and Paraguayan Guaraní was replaced with Mbyá Guaraní, due to insufficient information in the available sources. .
The first observation concerns the large Mawetí-Guaraní branch. While the branch as a whole and the Tupí-Guaraní subbranch remain just as robust as before (for Mawetí-Guaraní, 99.6% confidence in Figure 3, now 99.8% in Figure 7; for Tupí-Guaraní, 99.7% and 99.4% respectively), the Awetí-Guaraní subbranch is much less clearly visible in Figure 6 than it is in Figures 2, 4, and 5; the corresponding confidence drops from 99.0% in Figure 3 (Swadesh list) to 65.7% in Figure 7 (plants and animals). In other words, Mawé appears to be much closer to Awetí-Guaraní, to the point that the latter group does not appear clearly attested on the basis of the list of animals and plants, as it does on the basis of the Swadesh list. This suggests that Mawé may have borrowed words from other Awetí-Guaraní languages, which is indeed confirmed by historical records: Mawé was for a long time in contact with Nheengatu, a lingua franca descended from the Tupí-Guaraní language Tupinamba, and has many borrowings from it (see Corrêa da Silva, 2007, 2010).

Network representation (NeighborNet algorithm) based on the 90-item list of plants and animals
Turning to the Ramaráma-Puruborá (Káro-Puruborá) subbranch, we see an increase from the barely significant confidence based on Swadesh list data (71.9% in Figure 3) to a more comfortable level (84.6%) with plant and animal names. Furthermore, in the Tuparí branch, we see that Wayoró, which formed a subbranch with the Tuparí language in Figure 3 (83.7% confidence), now forms a subbranch with Makuráp (58.7%). Such 'jumping around' again exemplifies what McMahon; McMahon (2005) consider an indicator of possible undetected borrowings in the dataset It is also possible that the results reflect the current situation of advanced linguistic obsolescence for Puruborá and Wayoró. Puruborá is only spoken by a couple of 'rememberers', while Wayoró is spoken by a few individuals who do not normally use it and have not done so for a long time. At least in the Wayoró case, speakers are in close contact with Makuráp, from which they may have made impromptu borrowings.
Another interesting fact is the presence of a higher subgrouping comprising all Rondônian branches when considering the list of plant and animal names. This subgrouping is clearly visible in Figure 6 and shows 90.3% confidence in Figure 7. This suggests a higher level of borrowing, perhaps even areal effects, between Rondônian languages, at least in the domain of plants and animals. In his study of isolates in Rondônia, Voort (2005VOORT, Hein van der. Kwaza in a comparative perspective., International Journal of American Linguistics v. 71, n. 4, p. 365-412. 2005.) noted considerable diffusion of animal names.

Midpoint-rooted neighbor-joining cladogram with confidence rates (calculated via bootstrapping) for the 90-item list of plants and animals.
SUMMARY
The lexicostatistical classification derived through the analysis of a complete 100-item Swadesh list for all Tupian languages of the nine branches outside Tupí-Guaraní provides a considerable body of evidence that confirms the classification proposals based on the traditional Comparative Method and other methods of historical linguistics. The results discussed here support the proposed higher Mawetí-Guaraní branch, and while not conclusive, the results also provide marginal support for the putative Ramaráma-Puruborá (Káro-Puruborá) branch.
The internal classification of the two most largely diversified branches after Tupí-Guaraní, Mondé and Tuparí, is a great contribution to the discussion of the internal structure of the Tupian family. For instance, one interesting observation regarding the internal classification of the Tuparí branch is that while Makuráp appears as the more lexically divergent language, it is also the language more deeply involved with situations of borrowing, both with Tupian and non-Tupian languages of the Rondônia region.
The hypothesis of a large grouping uniting all of the non-Tupí-Guaraní Tupian languages spoken in Rondônia ('Western Tupian') as a viable branch in the classification of the family is not supported here. Our analysis of plant and animal terms, which are most likely to be borrowed, suggests that apparent similarities between the 'Western' languages may be a result of undetected borrowings either among the Rondônian Tupian languages or between them and their non-related neighbors (cf. Crevels; Voort, 2008CREVELS, Mily; VOORT, Hein van der. The Guaporé-Mamoré region as a linguistic area. In: MUYSKEN, Pieter (Ed.). From linguistic areas to areal linguistics. Amsterdam, Philadelphia: John Benjamins, 2008. p. 151-179. (Studies in Language Companion Series, v. 90). ). In addition, our analysis of lexical distance of basic vocabulary has revealed that there is a low degree of reticulation in the current dataset. This suggests that the Tupian expansion was essentially tree-like, and thus probably marked by multiple periods of distinct migrations (or by political separation of peoples when these were in the same region), producing the different branches. These migrations were then followed by periods of relative demographic separation, resulting in the diversification of the respective branches and possible instances of social interaction with neighboring ethnolinguistic groups. Such a hypothesis can be further developed through collaboration with researchers in related disciplines concerned with human prehistory.
ACKNOWLEDGMENTS
We would like to thank all the colleagues and institutions who have helped us in one moment or the other during the course of our Tupí Comparative Project, and the discussions that are presented in this paper, especially Antonia Fernanda Nogueira, Didier Demolin, Ellison Santos, Geiva Picanço, Hein van der Voort, Heliton Castro, Love Eriksen, Mariana Lacerda, Pieter Muysken (the Spinoza and the ERC Traces of Contact projects), Rose Costa, Conselho Nacional de Pesquisa e Desenvolvimento-CNPq, Fundação Nacional do Indío, Radboud University, The Wenner-Gren Foundation, and also two anonymous referees
REFERENCES
- ALMEIDA, Antônio; JESUS, Irmãzinhas de; PAULA, Luíz Gouvêa de. A língua Tapirapé. Rio de Janeiro: Xerox do Brasil. 1983.
- ANONBY, Stan. A Historical comparative look at four Mondé languages. SIL International, 2012. Available at: <Available at: http://www.sil.org/silewp/2012/silewp2012-006.pdf >. Acessed on: Aug. 22, 2015. (Electronic Working Paper, 6).
» http://www.sil.org/silewp/2012/silewp2012-006.pdf - BAXTER, William H.; RAMER, Alexis Manaster. Review of Ringe (1992). Diachronica, v. 13, n. 2, p. 371-384. 1996.
- BETTS, La Vera D. Dicionário Parintintin-Português, Português-Parintintin. Cuiabá: Sociedade Internacional de Linguística. 1981.
- BIRCHALL, Joshua; DUNN, Michael; GREENHILL, Simon. A combined comparative and phylogenetic analysis of the Chapacuran language family. International Journal of American Linguistics. To appear.
- BRYANT, David; MOULTON, Vincent. NeighborNet: an agglomerative algorithm for the construction of phylogenetic networks. Molecular Biology and Evolution, v. 21, n. 2, p. 255-265. 2004.
- CADOGAN, León. Diccionario Mbya-Guarani - Castellano. Asunción: Fundación "León Cadogan", 1992. (Biblioteca Paraguaya de Antropología, 17).
- CORRÊA DA SILVA, Beatriz C. Mawé/Awetí/Tupí-Guaraní: relações linguísticas e implicações históricas. 2010. Ph.D. dissertation, Universidade de Brasília, Brasília, 2010.
- CORRÊA DA SILVA, Beatriz C. Mais fundamentos para a hipótese de Rodrigues (1984/1985) de um Proto-Awetí-Tupí-Guaraní. In: RODRIGUES, A. D.; CABRAL, A.S. A. C. (Ed.). Línguas e culturas Tupí. Campinas: Curt Nimuendajú, 2007. p. 219-240. (v. 1).
- CREVELS, Mily; VOORT, Hein van der. The Guaporé-Mamoré region as a linguistic area. In: MUYSKEN, Pieter (Ed.). From linguistic areas to areal linguistics. Amsterdam, Philadelphia: John Benjamins, 2008. p. 151-179. (Studies in Language Companion Series, v. 90).
- DIETRICH, Wolf. More evidence for an internal classification of Tupi-Guarani languages. Berlin: Gebr. Mann, 1990. (Indiana Beiheft, v. 12).
- DOOLEY, Robert A. Léxico Guaraní, dialeto Mbya: versão para fins acadêmicos. Porto Velho: Sociedade Internacional de Linguística. 1998.
- DUNN, Michael. Language phylogenies. In: BOWERN, Claire; EVANS, Bethwyn (Ed.) Routledge handbook of historical linguistics. London, New York: Routledge, 2015. p.190-211.
- DRUDE, Sebastian. On the position of the Awetí language in the Tupí family. In: DIETRICH, Wolf; SYMEONIDIS, Haralambos (Ed.). Guaraní y "Mawetí-Tupí-Guaraní": Estudios históricos y descriptivos sobre una familialingüística de América del Sur. Berlim: LIT Verlag, 2006. p. 47-68.
- FARGETTI, Cristina M.; RODRIGUES, Carmen L. Consoantes do xipaya e do juruna: uma comparação em busca do proto-sistema. Alfa, v. 52, n. 2, p. 535-563, 2008.
- GABAS JÚNIOR, Nilson. Genetic relationship within the Ramaráma family of the Tupí stock (Brazil). In: VOORT, Hein van der; KERKE, Simon van de (Ed.). Indigenous languages of lowland South America. Leiden: CNWS, Universiteit Leiden, 2000. p. 71-82. (Indigenous Languages of Latin America, v. 1).
- GABAS JÚNIOR, Nilson. A classificação da língua Akuntsu. Estudos linguísticos, v. 34, p.105-109. 2005.
- GALUCIO, Ana Vilacy; NOGUEIRA, Fernanda. Comparative study of the Tupari branch of the Tupi family: contributions to understanding its historical development and internal classification. In: CONFERENCE ON INDIGENOUS LANGUAGES OF LATIN AMERICA, 5., 2012, Austin. Annals... Austin: Center for Indigenous Languages of Latin America (CILLA), 2012. p. 1-28. Available at: <Available at: http://www.ailla.utexas.org/site/events.html >. Acessed on: Aug. 22, 2015.
» http://www.ailla.utexas.org/site/events.html - GALUCIO, Ana Vilacy; GABAS JÚNIOR, Nilson. Evidências de agrupamento genético Karo-Puruborá, tronco Tupi. In: XVII Encontro Nacional da ANPOLL: boletim informativo, 2002, Gramado: ANPOLL. v. 31. p. 163.
- GRAY, Russell D.; BRYANT, David; GREENHILL, Simon J. On the shape and fabric of human history. Philosophical Transactions of the Royal Society of London. Series B, Biological sciences, v. 365, n.1559, p. 3923-3933. 2010.
- GRAY, Russell D.; DRUMMOND, Alexei J.; GREENHILL, Simon J. Language phylogenies reveal expansion pulses and pauses in Pacific settlement. Science, v. 323, p. 479-483. 2009. Available at: <doi.org/10.1126/science.1166858>. Acessed on: Aug. 22, 2015.
» https://doi.org/doi.org/10.1126/science.1166858 - GRAY, Russell D.; ATKINSON, Quentin. Language-tree divergence times support the Anatolian theory of Indo-European origins. Nature, v. 426, p. 435-439. 2003. Available at: <doi.org/10.1038/nature02029>. Acessed on: Aug. 22, 2015.
» https://doi.org/doi.org/10.1038/nature02029 - GUASCH, Antonio; ORTIZ, Diego. Diccionario Castellano-Guaraní, Guaraní-Castellano, 13th ed. Asunción: Centro de Estudios Paraguayos "Antonio Guasch" (CEPAG), 1996.
- HOLLAND, Barbara R.; HUBER, Katharina T.; DRESS, Andreas; MOULTON, Vincent. δ Plots: A tool for analyzing phylogenetic distance data., Molecular Biology and Evolution v. 19, n. 12, p. 2051-2059. 2002.
- HOLMAN, Eric W.; WICHMANN, Søren; BROWN, Cecil H.; VELUPILLAI, Viveka; MÜLLER, André; BAKKER, Dik. Explorations in automated language classification. Folia Linguistica, v. 42, n. 2, p. 331- 354. 2008.
- HUSON, Daniel H.; BRYANT, David. Application of phylogenetic networks in evolutionary studies., Molecular Biology and Evolution v. 23, n. 2, p. 254-267. 2006. Available at: <Available at: www.splitstree.org >. Acessed on: 30 jan. 2014.
» www.splitstree.org - KAKUMASU, James Y.; KAKUMASU, Kiyoko. Dicionário por tópicos Kaapor-Português. Cuiabá: Associação Internacional de Lingüística - SIL Brasil. 2007.
- KESSLER, Brett. The significance of word lists: statistical tests for investigating historical connections between languages. Stanford, CA: CSLI Publications, 2001.
- LOHR, Marisa. Methods for the genetic classification of languages. Ph.D. dissertation, University of Cambridge, Cambridge, 1999.
- LOPES, Mario Alexandre Garcia. Aspectos gramaticais da língua Ka'apor. Ph.D. dissertation, Universidade federal de Minas Gerais, Belo Horizonte, 2009.
- MCMAHON, April; MCMAHON, Robert. Language classification by numbers. Oxford: Oxford University Press, 2005.
- MEIRA, Sérgio. Stative verbs vs. nouns in Sateré-Mawé and the Tupian family. In: ROWICKA, Grazyna; CARLIN, Eithne (Ed.). What's in a verb? Studies in the verbal morphology of the languages of the Americas. Utrecht: LOT, 2006. p.184-214. (LOT Occasional Series)
- MEIRA, Sérgio.; DRUDE, Sebastian. A summary reconstruction of Proto-Maweti-Guarani segmental phonology. (this volume)
- MELLO, Augusto A. S. Evidências fonológicas e lexicais para o subagrupamento interno Tupi-Guarani. In: CABRAL, A. S. A. C.; RODRIGUES, A. D. (Ed.). Línguas indígenas brasileiras: fonologia, gramática e história. Belém: EDUFPA, 2002. p. 338-342. (Encontro Internacional do Grupo de Trabalho sobre Línguas Indígenas da ANPOLL, 1.).
- MELLO, Augusto A. S. Estudo histórico da família lingüística Tupí-Guaraní: aspectos fonológicos e lexicais. Ph.D. dissertation, Universidade Federal de Santa Catarina, Florianópolis, 2000.
- MÉTRAUX, Alfred. La civilisation matérielle des tribus Tupi-Guarani. Paris: Paul Geuthner, 1928.
- MICHAEL, Lev; CHOUSOU-POLYDOURI, Natalia; BARTOLOMEI, Keith; DONNELLY, Erin; WAUTERS, Vivian; MEIRA, Sérgio; O'HAGAN, Zachary. A Bayesian phylogenetic classification of Tupí-Guaraní. Liames. To appear.
- MOORE, Denny. Classificação interna da família lingüistica Mondé. Estudos Linguísticos, v. 34, p. 515-520. 2005.
- MOORE, Denny; GALUCIO, Ana Vilacy. Reconstruction of Proto-Tupari Consonants and Vowels. In: MEETING OF THE SOCIETY FOR THE STUDY OF THE INDIGENOUS LANGUAGES OF THE AMERICAS AND THE HOKAN-PENUTIAN WORKSHOP, 1994, Berkeley. Annals... Berkeley: University of California, 1994. p. 119-137.
- MOORE, Denny; GALUCIO, Ana Vilacy; GABAS JÚNIOR, Nilson. O desafio de documentar e preservar as línguas amazônicas. Scientific American Brasil, p. 36-43. 2008. (Amazônia - A Floresta e o Futuro). Edição especial 3.
- PICANÇO, Gessiane. A reconstruction of nasal harmony in Proto-Mundurukú (Tupi). International Journal of American Linguistics, v. 76, n. 4, p. 411-438. 2010.
- PICANÇO, Gessiane. Mundurukú: phonetics, phonology, synchorny, diachrony. Ph.D. dissertation, University of British Columbia, Canada, 2005.
- PRAÇA, Walkíria N. Morfossintaxe da língua Tapirapé (Família Tupi-Guaraní). Ph.D. dissertation, Universidade de Brasília, Brasília, 2007.
- RINGE JUNIOR, Donald A. On calculating the factor of chance in language comparison. Transactions of the American Philosophical Society, Philadelphia, v. 82, n. 1, p. 1-110. 1992.
- RODRIGUES, Aryon D. As consoantes do Proto-Tupi. In: CABRAL, Ana Suelly Arruda Câmara; RODRIGUES, Aryon Dall'Igna. (Ed.). Línguas e culturas Tupí. Campinas: Curt Nimuendaju; Brasília: LALI, 2007. p. 167-203.
- RODRIGUES, Aryon. As vogais orais do Proto-Tupi. In: RODRIGUES, Aryon Dall'Igna; CABRAL, Ana Suelly Arruda Câmara (Ed.). Novos estudos sobre línguas indígenas. Brasília: Universidade de Brasília, 2005. p. 35-46.
- RODRIGUES, Aryon D. Relações internas na família lingüística Tupí-Guaraní. Revista de Antropologia, São Paulo, v. 27-28, p. 33-53. 1984/85.
- RODRIGUES, Aryon D. A classificação do tronco lingüístico Tupí., Revista de Antropologia v. 12, p. 99-104. 1964.
- RODRIGUES, Aryon; CABRAL, Ana Suelly. Tupían. In: CAMPBELL, Lyle; GRONDONA, Verónica (Eds.). The indigenous languages of South America: a comprehensive guide. Berlin; Boston: Walter de Gruyter, 2012. p. 495-574.
- RODRIGUES, A. D.; CABRAL, A. S. A. C. Revendo a classificação interna da família Tupí-Guaraní. In: CABRAL, A. S. A. C.; RODRIGUES, A. D. (Eds.). Línguas indígenas brasileiras: Fonologia, gramática e história. Atas do I Encontro Internacional do Grupo de Trabalho sobre Línguas Indígenas da ANPOLL., Belém: EDUFPA 2002. p. 327-338.
- RODRIGUES, Aryon Dall'Igna; DIETRICH, Wolf. On the linguistic relationship between Mawé and Tupí-Guaraní., Diachronica v. 14, p. 265-304. 1997.
- SAITOU, Naruya; NEI, Masatoshi. The neighbor-joining method: a new method for reconstructing phylogenetic trees., Molecular Biology and Evolution v. 4, n. 4, p. 406-425. 1987.
- SCHLEICHER, Charles Owen. Comparative and internal reconstruction of the Tupi-Guarani language family. Ph.D. dissertation, University of Wisconsin, Madison, 1998.
- STAROSTIN, Sergei. Comparative-historical linguistics and lexicostatistics. In: RENFREW, Colin; MCMAHON, April; TRASK, Larry (Ed.). Time depth in historical linguistics. Cambridge: McDonald Institute for Archaeological Research, 2000. p. 223-266.
- STORTO, Luciana; BALDI, Philip. The Proto-Arikém vowel shift. In: INTERNATIONAL CONGRESS OF THE LINGUISTIC SOCIETY OF AMERICA. 1994. Annals... 1994. p. 1-13.
- SWADESH, Morris. Towards greater accuracy in lexicostatistic dating. International Journal of American Linguistics, v. 21, n.2, p. 121-137, 1955.
- VOORT, Hein van der. Kwaza in a comparative perspective., International Journal of American Linguistics v. 71, n. 4, p. 365-412. 2005.
- WALKER, Robert S.; WICHMANN, Soeren; MAILUND, Thomas; ATKISSON, Curtis J. Cultural phylogenetics of the Tupi language family in lowland South America. PLoS ONE, v. 7, n. 4, p. 1-9. 2012.
- WALKER, Robert S.; RIBEIRO, Lincoln A. Bayesian phylogeography of the Arawak expansion in lowland South America. Proceedings of the Royal Society, v. 278, n. 1718, p. 2562-2567. 2011.
- WICHMANN, Søren; MÜLLER, André; VELUPILLAI, Viveka. Homelands of the world's language families: A quantitative approach., Diachronica v. 27, n. 2, p. 247-276. 2010.
APPENDIX 1: SWADESH'S 100-WORD LIST
The meaning, with its number in the list, is given in boldface capitals. The specific words, retranscribed from their original sources with IPA symbols (note that acute and grave accents mark tone, not stress, and that long vowels are represented by sequences of identical vowels: aa, oo, etc.; a dot, used only when necessary, marks a syllable boundary), are presented under the meaning, in italics, preceded by a two-letter abbreviation indicating the source language. Initial hyphens (indicating that the word takes a prefix) are copied from the original sources. Words assumed to be cognate (fully or partially) are listed sequentially, separated by commas, forming a cognate set; the end of a cognate set is indicated by two vertical strokes (||). If for a given meaning a language has variants or synonyms, they are indicated after the language abbreviation, separated by commas; if a word has conditioned alternants, these are separated by a tilde (~). A segment enclosed in parenthesis is not always pronounced. For each meaning, cognate sets are presented in order of decreasing size. Missing words are marked by question marks after the language abbreviation, at the end, after all cognate sets. Given the incipent stage of knowledge about Proto-Tupí and its historical development, our cognacy judgments in this paper are preliminary, based on our experience with the languages and with our current hypotheses about their sound changes; some of them will probably change in the future. Methodologically, we decided to err on the side of inclusiveness: if only part of a word is cognate (p.ex., Portuguese nós and the first syllable of Spanish nosotros, both meaning 'we'), we still counted it as a full cognate. Language abbreviations: Ak = Akuntsú, Ar = Aruá, Aw = Awetí, Gv = Gavião, Ju = Jurúna, Ka = Káro, Kt = Karitiána, Ku = Kuruáya, Ma = Makuráp, Me = Mekéns, Mu = Mundurukú, Mw = Mawé, Pg = Paraguayan Guaraní, Pt = Parintintín, Pu = Puruborá, Sa = Salamãy, Su = Suruí, Ta = Tapirapé, Tu = Tuparí, Uk = Urubú-Ka'apór, Wa = Wayoró, Xi = Xipáya, Zo = Zoró

APPENDIX 2: LIST OF PLANT AND ANIMAL NAMES
The list below contains all animal and plant names used in this paper. It follows the same conventions as the Swadesh list in Appendix 1, with only two differences: due to lack of relevant data in our sources, Tapirapé was eliminated and Paraguayan Guaraní was here replaced by another dialect, Mbyá Guaraní (abbreviated below as Mg).

-
1
The permanent members of the initial Tupí Comparative Project are Ana Vilacy Galucio for the Puruborá and Tuparí branches; Carmen Rodrigues for the Jurúna branch; Denny Moore for the Mondé branch; Gessiane Picanço for the Mundurukú branch; Luciana Storto for the Arikém branch; Nilson Gabas Jr. for the Ramaráma branch; Sebastian Drude for the Awetí branch; and Sérgio Meira for the Mawé and Tupí-Guaraní branches. Other members that have collaborated with specific languages include Didier Demolin and Fernanda Nogueira for Wayoró, and Mariana Lacerda for Suruí of Rondônia.
-
2
The dotted lines under the Tupí-Guaraní node indicate that the complete list of languages does not fit into the reserved space in the diagram, and that we regard the validity of the differing classifications of its branches as still unresolved.
-
3
Wichmann et al. (2010) place the Tupian hypothetical homeland at 8°S, 62°W, which also corresponds to the same general area that has been previously proposed by other scholars (Métraux, 1928; Rodrigues, 1964).
-
4
The unit formed by Mawé, Awetí, and the Tupí-Guaraní branchs has been proposed as a single higher sub-branch, as shown in Figure 1 (Corrêa da Silva, 2007, 2010; Dietrich, 1990, Drude, 2006; Rodrigues, 1984/85; Rodrigues; Cabral, 2002; Rodrigues; Dietrich, 1997; Walker et al., 2012): the Mawé-Awetí-Tupí-Guaraní or “Mawetí-Guaraní” branch, a shortened form already used in Drude (2006), Meira (2006), and further in the present work.
-
5
In addition, there already is a more in-depth study of Tupí-Guaraní interrelations with phylogenetic (Bayesian) methods (Michael et al., to appear).
-
6
We thank Love Eriksen for the map.
-
7
For instance, suppose that, for two languages L1 and L2, respectively 90 and 80 meanings of the Swadesh list were found in the available data, and that only 75 of these were the same meanings in both languages; furthermore, suppose that, of these 75 pairs of synonymous words, only 60 pairs consisted of cognate words, in the authors’ judgment. In this case, the percentage of shared cognates between languages L1 and L2 would be 60/75 = .8 or 80%, which would be shown in Table 5 as 080.
-
8
The normalization assumes that the missing items would have the same average cognacy rate as the known items, which is not necessarily the case. In fact, the languages with gaps of 8% or more and a small number of speakers have greater-than-average cognacy rates with languages outside of their branches (Akuntsú 37.8%, Kuruáya 35.2%, Salamãy 32.8%; Puruborá, with 30.4%, is the only one not above the average). For a possible explanation, see the final paragraph in the Section Similarity (shared cognates) matrix.
-
9
We note, in passing, that McMahon; McMahon’s (2005) success in applying Lohr’s (1999) and Starostin’s (2000) meaning lists probably stems from the fact that they were applied to Indo-European, which was one of the language families in both Lohr’s and Starostin’s databases, so that the meanings in question were indeed guaranteed to have high retentiveness and reconstructibility.
-
10
The meaning ‘sun’ has five cognate sets, but because of what appears to be a mistake in the original Tapirapé source: the word is elsewhere attested as meaning ‘day’. Because of this, ‘sun’ is here included in the Tupí-HiHi list.
-
11
Some Tupian languages have not a simple word but a complex expression for these numbers, sometimes even more than one expression in synchronic competition.
-
12
McMahon, A.; McMahon, R.’s HiHi list (2005, p. 109, Table 4.2) with 30 meanings: four, name, three, two, foot, give, long, salt, sun, other, sleep, to come, day, to eat, not, thin, five, mother, ear, I, new, night, one, to spit, star, to stand, though, tongue, tooth, wind. McMahon, A.; McMahon, R.’s LoLo list (2005, p.109, Table 4.2) with 23 meanings: grass, mouth, stone, heavy, year, bird, near, smooth, wing, man, neck, tail, to walk, back, to flow, left (hand), to pull, to push, river, rope, straight, to think, to throw.
-
13
Holman et al,. (2008) have also published a list of meanings ranked by stability, based on a large (800+) sample of languages. There is a high degree of corelation between Holman’s list and ours (preliminary results based on a suggestion by one of the referees to this paper show a Spearmann rank corelation of -0.50 with p < 0.0000001, without any radical outliers visible on a plot of Holman ranks vs. meanings), which means that our choice to use a Tupí-internal stability ranking is not expected to produce significantly different results from an analysis based on Holman’s rankings. We hope to investigate, in future studies, the idea of a universal stability ranking and to examine possible family-specific ranking deviations for particular meanings.
-
14
Cinta-Larga, another dialect, was not included in the sample.
-
15
Another classification proposal by Anonby (2012) is not supported by the results from analysis put forth here.
-
16
The Tupí-Guaranian languages in the sample were taken from different subgroups, both in Mello´s (2000) and inRodrigues; Cabral´s (2002) classifications, and are almost as far away from each other as is possible to be within this branch. It would be interesting to see how many languages within each Tupí-Guaraní sub-branch would turn out to be better described as (co-)dialects if their percentage of shared cognates, their overall phonological and grammatical similarity, and their level of mutual intelligibility were compared.
-
17
One outstanding case is the 47% value found for Mawé and Akuntsú (Tuparí branch); but it is probably due, at least in part, to the gaps in the Akuntsú data (see Table 1).
-
18
Figure 3 can be usefully compared to the tree in Figure 1 in Walker et al. (2012). That tree is based on fewer (40) items, less reliable data and a different distance-based method based on edit distance between corresponding lexical items. It differs in higher groupings and also in the internal classification of the branches.
-
19
This cladogram refers not to the network in Figure 2, but to the best equivalent tree to that network, calculated with the neighbor-joining algorithm (Saitou and Nei, 1987) applied to the same data set.
-
20
Since bootstrapping involves random resampling, the confidence values usually change when evaluated again. Low confidence levels change more, since the status of the corresponding branch or subnetwork as contributing to the best solution is not robust and can be algorithm, or a few changes in the data.
-
21
The network representation of lexical distance in the Tupí-HiHi list is only marginally more reticulate than that of the Tupí-LoLo list, i.e. is less tree-like, with δ-scores of 0.289 (s.d. ± 0.042) and 0.268 (s.d. ± 0.040), respectively. The statistical outliers in the Tupí-HiHi list are Akuntsú, Mekéns and Karitiána (δ = 0.352, 0.346, 0.373, respectively), while the outliers for the Tupí-LoLo list are Karitiána, Káro and Puruborá (δ = 0.324, 0.345, 0.361, respectively).
-
22
Note that, as said before, Tapirapé was eliminated and Paraguayan Guaraní was replaced with Mbyá Guaraní, due to insufficient information in the available sources.
Publication Dates
-
Publication in this collection
Aug 2015