
Abstract
Almost all quantitative studies in educational assessment, evaluation and educational research are based on incomplete data sets, which have been a problem for years without a single solution. The use of big identifiable data poses new challenges in dealing with missing values. In the first part of this paper, we present the state-of-art of the topic in the Brazilian education scientific literature, and how researchers have dealt with missing data since the turn of the century. Next, we use open access software to analyze real-world data, the 2017 Prova Brasil , for several federation units to document how the naïve assumption of missing completely at random may substantially affect statistical conclusions, researcher interpretations, and subsequent implications for policy and practice. We conclude with straightforward suggestions for any education researcher on applying R routines to conduct the hypotheses test of missing completely at random and, if the null hypothesis is rejected, then how to implement the multiple imputation, which appears to be one of the most appropriate methods for handling missing data.
Prova Brasil; Missing data; R; Multiple imputation
Resumo
Quase todos os estudos quantitativos em aferição, avaliação e pesquisa educacional são baseados em conjuntos de dados incompletos, que têm sido um problema há anos sem solução única. O uso de grandes dados identificáveis apresenta novos desafios para lidar com valores ausentes. Na primeira parte deste artigo, apresentamos o estado-da-arte do tópico na literatura científica educacional brasileira e como os pesquisadores têm tratado os dados omissos. Em seguida, usamos o software de acesso livre para analisar dados do mundo real, a Prova Brasil 2017, para várias unidades da federação, e documentamos como pressuposto de dados omissos completamente aleatórios pode afetar os resultados estatísticos, as interpretações e implicações subsequentes para políticas e práticas. Concluímos com sugestões diretas para qualquer pesquisador de educação sobre a aplicação de rotinas R para realizar o teste de hipóteses de dados omissos completamente aleatórios e, se a hipótese nula for rejeitada, como implementar a imputação múltipla, que parece ser um dos métodos mais apropriados para manipular dados ausentes.
Prova Brasil; Dados omissos; R; Imputação múltipla
Resumen
Casi todos los estudios cuantitativos en evaluación, evaluación e investigación educativa se basan en conjuntos de datos incompletos, que han sido un problema desde hace años sin solución única. El uso de grandes datos identificables presenta nuevos desafíos para manejar los valores ausentes. En la primera parte de este artículo, presentamos el estado del arte del tópico en la literatura científica educativa brasileña y cómo los investigadores han tratado los datos omisos. A continuación, utilizamos el software de acceso libre para analizar datos del mundo real, la Prueba Brasil 2017, para varias unidades de la federación, y documentamos cómo la asunción de datos omisos completamente aleatorios puede afectar los resultados estadísticos, las interpretaciones e implicaciones subsecuentes para políticas y prácticas. Concluimos con sugerencias directas para cualquier investigador de educación sobre la aplicación de rutinas R para realizar la prueba de hipótesis de datos omisos completamente aleatorios y, si la hipótesis nula es rechazada, cómo implementar la imputación múltiple, que parece ser uno de los métodos más apropiados para manipular datos ausentes.
Prueba Brasil; Datos omisos; R; Imputación múltiple
1 Introduction
Quantitative based research in Education involving complete data analysis is highly improbable, particularly if the statistical unit of measurement is the human subject. Unanticipated events in data collection often cause missing data, attrition, and nonresponse. However, research papers in education often do not mention the occurrence of missing data ( COX et al., 2014COX, B. E. et al. Working with missing data in Higher Education research: a primer and real-world example. The Review of Higher Education, Baltimore, v. 37, n. 3, p. 377-402, Spring 2014. https://doi.org/10.1353/rhe.2014.0026
https://doi.org/10.1353/rhe.2014.0026...
; WELLS et al., 2015WELLS, R. S. et al. “How we know what we know”: a systematic comparison of research methods employed in higher education. Journal of Higher Education, London, v. 86, n. 2, p. 171-195, 2015. https://doi.org/10.1080/00221546.2015.11777361
https://doi.org/10.1080/00221546.2015.11...
) despite best practice recommendations in reporting and handling missing data (PAMPAKA; HUTCHESON; WILLIAMS, 2016; SCHLOMER; BAUMAN; CARD, 2010) in quantitative based research. The American Psychological Association’s report ( WILKINSON; APA BOARD OF SCIENTIFIC AFFAIRS, 1999WILKINSON, L.; APA BOARD OF SCIENTIFIC AFFAIRS. Statistical methods in Psychology journals. American Psychologist, Washington, v. 54, n. 8, p. 594-604, Aug. 1999. Available from: <https://www.apa.org/
https://www.apa.org/...
) on statistical methods in Psychology journals mentions that “The two popular methods for dealing with missing data that are found in basic statistics packages – listwise and pairwise deletion of missing values are among the worst methods available for practical applications” (p. 598). Since then the increasing use of alternative methods such as Maximum Likelihood (ML) estimation or Multiple Imputation (MI) ( RUBIN, 1987RUBIN, D. B. Multiple imputation for nonresponse in surveys. New York: Wiley, 1987. ) has been reported by several authors ( COX et al., 2014COX, B. E. et al. Working with missing data in Higher Education research: a primer and real-world example. The Review of Higher Education, Baltimore, v. 37, n. 3, p. 377-402, Spring 2014. https://doi.org/10.1353/rhe.2014.0026
https://doi.org/10.1353/rhe.2014.0026...
; LAVANYA; REDDY; REDDY, 2019; PAMPAKA; HUTCHESON; WILLIAMS, 2016; PEUGH; ENDERS, 2004PEUGH, J. L.; ENDERS, C. K. Missing data in educational research: a review of reporting practices and suggestions for improvement. Review of Educational Research, [s. l.], v. 74, n. 4, p. 525-–556, Dec. 2004. https://doi.org/10.3102/00346543074004525
https://doi.org/10.3102/0034654307400452...
; SCHLOMER; BAUMAN; CARD, 2010). An extensive review of practices dealing with missing data in the educational and psychological research was conducted by Peugh and Enders (2004)PEUGH, J. L.; ENDERS, C. K. Missing data in educational research: a review of reporting practices and suggestions for improvement. Review of Educational Research, [s. l.], v. 74, n. 4, p. 525-–556, Dec. 2004. https://doi.org/10.3102/00346543074004525
https://doi.org/10.3102/0034654307400452...
, who divided the missing data methods into two categories: the “traditional” and the “modern” methods, which include ML and MI. The articles reviewed were published in 16 educational and applied psychological journals in 1999 and 2003. According to authors, in 1999, 33.75% of the papers explicitly reported the problem of missing data and in 2003 such percentage more than doubled (74.24%). In addition, in 1999 none of the papers in the review adopted ML or MI for missing data handling, and they reported six papers in 2003. In fact, the field of education and other related disciplines have been strongly conditioned either by the availability of data or by their quality ( FOLEY; GOLDSTEIN, 2012FOLEY, B.; GOLDSTEIN, H. Measuring success: league tables in the public sector. London: British Academy, 2012. ). On the American Statistical Association’s statement to inform the use of Value Added Models (VAMs) “for educational assessment […] where states and local governments use them to make high-stakes decisions regarding teacher performance appraisals and compensation” ( MORGANSTEIN; WASSERSTEIN, 2014MORGANSTEIN, D.; WASSERSTEIN, R. ASA statement on value-added models. Statistics and Public Policy, Philadelphia, v. 1, n. 1, p. 108-110, Nov. 2014. https://doi.org/10.1080/2330443X.2014.956906
https://doi.org/10.1080/2330443X.2014.95...
, p. 108) the authors state that the models “can help evaluate teaching programs […]”, and conclude that their use must regard for data and statistical model assumptions and limitations. We face “The challenge with VAMs is to include all the important factors that might contribute to the observed differences in test scores. Many potential explanatory variables are not available for inclusion or have many missing values […]” ( MORGANSTEIN; WASSERSTEIN, 2014MORGANSTEIN, D.; WASSERSTEIN, R. ASA statement on value-added models. Statistics and Public Policy, Philadelphia, v. 1, n. 1, p. 108-110, Nov. 2014. https://doi.org/10.1080/2330443X.2014.956906
https://doi.org/10.1080/2330443X.2014.95...
, p. 109). Therefore, no matter how large the volume of data is, how high the velocity is, or how many formats are available, the problem of missingness also strongly affects big identifiable data, implying that their use for policy and practice in Education imposes the adoption of proper strategies of missing data handling. Most of the quantitative based literature in educational research include the following variables as attributes of interest: student’s achievement, national exams scores, grade repetition, and individual sociodemographic characteristics such as gender and socioeconomic status (SES). In order to monitor and promote the equity of an education system, one of the key variables is the student’s SES (e.g. Author, 2015). The variable commonly used as proxy is mother’s education, which very often reaches more than 20% of missing values. The Missing Completely At Random (MCAR) assumption ( LITTLE, 1988LITTLE, R. J. A. A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, [s. l.], v. 83, n. 404, p. 1198-1202, Dec. 1988. https://doi.org/10.4018/IJACI.2019040105
https://doi.org/10.4018/IJACI.2019040105...
) when data modelling implies that the respective students are excluded from the analyses. Since the most needy students in public education are the most likely not to answer such key variables, any educational performance indicators based on naïve assumptions may fail to properly quantify the school effects and, thus, fail to promote the reduction of educational and social inequalities.
COX et al. (2014)COX, B. E. et al. Working with missing data in Higher Education research: a primer and real-world example. The Review of Higher Education, Baltimore, v. 37, n. 3, p. 377-402, Spring 2014. https://doi.org/10.1353/rhe.2014.0026
https://doi.org/10.1353/rhe.2014.0026...
reviewed the topic in the field of higher education scientific literature and conclude that “multiple imputation has emerged as the preferred option among statisticians and sociologists, who have been employing advanced methods for more than a decade” (p. 387), and they also refer multiple imputation procedures available in several commercial software packages. Thus, authors argue that “multiple imputation should be the new default option for quantitative research in higher education” (p. 387).
Two main contributions arise from this paper. Firstly, we explain in detail and illustrate with real-world data how the researcher should test if the missing data are MCAR. Second, we show the impact of assuming MCAR or running MI on the linear relationship between student’s performance and student’s socioeconomic status by comparing descriptive statistics and linear regression coefficient estimates. We will apply a routine for LITTLE (1988)LITTLE, R. J. A. A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, [s. l.], v. 83, n. 404, p. 1198-1202, Dec. 1988. https://doi.org/10.4018/IJACI.2019040105
https://doi.org/10.4018/IJACI.2019040105...
’s hypothesis test and the R package for multiple imputation procedures to Prova Brasil data collected in 2017 in the Northeast and South regions.
The remainder of this paper consists of three parts. Section two proceeds to the review of the scientific literature published in Brazilian and Portuguese journals registered in the SciELO platform. Section three presents data and methods, comprising the explanation of statistical packages in R to check the pattern of missingness and to conduct multiple imputation. Finally, the discussion and conclusion as section four. To our knowledge this is the first paper to present MI applied to big identifiable data of Prova Brasil and to evaluate the impact of naïve assumption as MCAR.
2 Missing data in the Brazilian educational research
The heart of this section is a review of the relevant quantitative research in education and educational research registered in the SciELO platform. The primary interest of this study is to identify the methods in use for missing data treatment in quantitative research that used Prova Brasil data. This paper focuses on studies published from 2016 to 2018. The main objective of the review process was to identify as many relevant and high-quality articles as possible. Thus, our strategy was to search a wide variety of papers and then systematically eliminate those that did not meet the criteria for content or relevance. The first step of the review was to conduct a search for peer-reviewed papers published from 2016 to 2018 using the SciELO search engine covering the education and educational research literatures. The search was conducted during May 2019. We searched for papers that listed “Prova Brazil” or “Prova Brasil” as a keyword or included the term in the abstract. The filter was (prova brasil) OR (prova brazil) AND year_cluster:(“2016” OR “2018” OR “2017”) AND work_subject_categories:(“education & educational research”) AND type:(“research-article”). We found 15 papers. Then, the content search was limited to papers that included “missing” data, dado “ faltante ” ou dado “ omisso ” (SOCIEDADE PORTUGUESA DE ESTATÍSTICA; ASSOCIAÇÃO BRASILEIRA DE ESTATÍSTICA, 2011) in the methodology section. We also looked up the tables and descriptive statistics in order to find out how missing data were treated. Four papers are narratives on evaluation or assessment and one presents a historical perspective. Amongst the remaining papers, four mentioned the existence of missing data ( BARTHOLO; COSTA, 2016BARTHOLO, T. L.; COSTA, M. Evidence of a school composition effect in Rio de Janeiro public schools. Ensaio: Avaliação e Políticas Públicas em Educação, Rio de Janeiro, v. 24, n. 92, p. 498-521, set. 2016. https://doi.org/10.1590/S0104-40362016000300001
https://doi.org/10.1590/S0104-4036201600...
; FONSECA; NAMEN, 2016FONSECA, S. O.; NAMEN, A. A. Mineração em bases de dados do Inep: uma análise exploratória para nortear melhorias no sistema educacional brasileiro. Educação em Revista, Belo Horizonte, v. 32, n. 1, p. 133-157, jan./mar. 2016. https://doi.org/10.1590/0102-4698140742
https://doi.org/10.1590/0102-4698140742...
; OLIVEIRA; CARVALHO, 2018OLIVEIRA, A. C. P.; CARVALHO, C. P. Public school management, leadership, and educational results in Brazil. Revista Brasileira de Educação, Rio de Janeiro, v. 23, n. e230015, 2018. https://doi.org/10.1590/s1413-24782018230015
https://doi.org/10.1590/s1413-2478201823...
; PONTES; SOARES, 2017)PONTES, L. A. F.; SOARES, T. M. Volatilidade dos resultados de proficiências e seu impacto sobre as metas do IDEB nas escolas públicas de Minas Gerais. Educação em Revista, Belo Horizonte, v. 33, n. e153262, 2017. https://doi.org/10.1590/0102-4698153262
https://doi.org/10.1590/0102-4698153262...
, but none of them explicitly mentioned any assumption or method to deal with missing data. Facing the short number of papers that recently have used the large and complex data Prova Brasil , we decided to extend the search for articles going back to the beginning of the century, thus the time period was 2000–2018 and enlarging the search for the periodic Estudos de Avaliação Educacional , which is not registered in Scielo platform. It is well-reputed by educational researchers. Thus, we looked for the keywords or expressions (and variations) in Portuguese or in the language of the article: “missing”/“ omisso ”/“ faltante ”, “missing data”/“ dados omissos ”/“ dados faltantes ”, “incomplete data”/“ dados incompletos ” and “no response”/“ sem resposta ”. The content analysis was focused on the methodology and results sections. We found 60 papers, which 38% (23) explicitly mention missing data, and 30% (18) apply a method to deal with the problem. The vast majority, that is 16 out of 18 papers, used a traditional method of imputation, meaning that, in general, ML and MI have been seldom used by educational researchers.
Vinha and Laros (2018) conducted a simulation study with the Brazilian education assessment data including 7,000 cases and eight variables which comprise four as auxiliary variables, in order to compare the performance of methods for missing treatment (mean imputation, listwise deletion, ML and MI). They confirmed that the mean imputation showed the worst performance. Their analyses were conducted using a commercial software.
Ferrão and Prata (2019)FERRÃO, M. E.; PRATA, P. Computing topics on multiple imputation in Big Identifiable Data using R: an application to educational research. In: MISRA, S. et al. (eds.). Computer science and its applications. [S. l.] Springer Cham, 2019. p. 12-24. (Lectures notes in computer science, v. 11621). used R open source software to test the pattern of missingness in simulated datasets generated from Prova Brasil 2017. They were generated to include MCAR or non-ignorable missing data ( LITTLE, 1988LITTLE, R. J. A. A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, [s. l.], v. 83, n. 404, p. 1198-1202, Dec. 1988. https://doi.org/10.4018/IJACI.2019040105
https://doi.org/10.4018/IJACI.2019040105...
). In the first situation, ML or MI procedures can be avoided without detriment of results. The Prova Brasil 2017 was used as big identifiable data ( SHLOMO; GOLDSTEIN, 2015SHLOMO, N.; GOLDSTEIN, H. Editorial: Big data in social research. Journal of the Royal Statistical Society Series A, London, v. 178, n. 4, p. 787-790, Sep. 2015. https://doi.org/10.1111/rssa.12144
https://doi.org/10.1111/rssa.12144...
) in educational research. They run MI with R and concluded that for datasets of about 20,000 cases and three variables, one auxiliary variable, the execution time does not depend on the missing percentage, varying between 5% and 20%. Increasing the number of cases (more than half a million) and the number of variables (10) with missing (8), the MI execution time was 116.4 minutes using a computer 8 GB RAM and 30.8 minutes with a computer 16 GB RAM. In addition, they mentioned that the routine run with four chains in parallel, with a limit of 35 iterations, but some variables had not converged. In fact, the use of big data for research purposes, may be an opportunity or a threat ( DIGGLE, 2015DIGGLE, P. J. Statistics: a data science for the 21st century. Journal of the Royal Statistical Society Series A, London, v. 178, n. 4, p. 793-813, Sep. 2015. https://doi.org/10.1111/rssa.12132
https://doi.org/10.1111/rssa.12132...
), if the big data do not cover the entire target population or there is a selective mechanism that produces missing data that are not MCAR, the research itself may be compromised.
3 Methodology
As an example of educational research where identifiable big data ( SHLOMO; GOLDSTEIN, 2015SHLOMO, N.; GOLDSTEIN, H. Editorial: Big data in social research. Journal of the Royal Statistical Society Series A, London, v. 178, n. 4, p. 787-790, Sep. 2015. https://doi.org/10.1111/rssa.12144
https://doi.org/10.1111/rssa.12144...
) do not cover the entire target population and, thus, the missing subjects may not be completely at random, we used the Prova Brasil 2017 data.
3.1 Prova Brasil 2017 data
The education data used in this study is the Avaliação Nacional do Rendimento Escolar (INEP - INSTITUTO NACIONAL DE ESTUDOS E PESQUISAS EDUCACIONAIS ANÍSIO TEIXEIRA, 2018), well known as Prova Brasil . The Prova Brasil was created in 2005 under the scope of the Basic Education Assessment System (Saeb) with the aim of assessing students learning at Brazilian public schools. It is a quasi-census type applied to students at the 5th and 9th grades of primary education in schools with 20 or more students enrolled in these grades. It covers all Brazilian territory and is carried out every two years by the Instituto Nacional de Estudos e Pesquisas Educacionais Anísio Teixeira (Inep), which is responsible for developing and applying educational assessments, and also the census of education. The Prova Brasil comprises standardized tests on Portuguese Language (reading) and Mathematics, as well as questionnaires targeting students, teachers, principals and schools. Saeb’s proficiency scales range from 0 to 500 with mean 250 and standard deviation 50 to 9th grade students ( KLEIN, 2003KLEIN, R. Utilização da teoria de resposta ao item no Sistema Nacional de Avaliação da Educação Básica (Saeb). Ensaio: Avaliação e Políticas Públicas em Educação, Rio de Janeiro, v. 11, n. 40, p. 283-296, jan./mar. 2003. ). Inep defined the eligible population for Prova Brasil based on the consolidated data of the Basic Education School Census of 2017.
We excluded from our analyses the federal schools, which represent 0.04% of public schools and are very different from common public schools in terms of student profile, infrastructure and organization. After this exclusion, the finite population is, then, a large identifiable sample of size N = 2,594 million students of its superpopulation of the 5th grade. The performance scores in Math and Reading are available for 2,170 (84%) million students and the socioeconomic status for 2,132 (82%) million students.
Table 1 summarizes the data patterns with respect to the missing data problem. Note that the main occurrence of missing data is due to the eligible students who did not attend school on the day of Prova Brasil (16.23%) administration. Other students attended the school that day, but did not take the test, neither answered the questionnaire (0.09%); others just did the test (0.65%), and a few of them were not present on the test day but filled in the questionnaire (0.04%). In several educational research studies, missing data are due to item nonresponse, i.e., participants in a survey or test who do not give responses for every item administered [item missing]. In addition, the expected participants in the survey or test do not appear [subject missing]. In the Brazilian data, comparing to the target population, there are at least 17% of subject missing and 83% with valid data but item missing. This study is focused on MI applied to item missing.
Distribution of missing and valid data of 5th grade students eligible for the Prova Brasil in state and municipal schools – 2017
For the purpose of this paper, we chose to analyze data related to every Federation Unit (FU) in the Northeast and South regions of Brazil, because these regions are very different in many socio-educational dimensions. In addition, we decided to conduct the missing data analysis extending the simulation work described by Ferrão and Prata (2019)FERRÃO, M. E.; PRATA, P. Computing topics on multiple imputation in Big Identifiable Data using R: an application to educational research. In: MISRA, S. et al. (eds.). Computer science and its applications. [S. l.] Springer Cham, 2019. p. 12-24. (Lectures notes in computer science, v. 11621). . Thus, the data analysis comprises three variables: student’s performance in reading (PR), student’s socioeconomic status (SES) and student’s trajectory without grade repetition (AP - which stands for “always promoted”). The student’s situation on promotion (always promoted vs. grade repetition) is considered a complete data variable and it is used as auxiliary variable for the MI purposes. In fact, it is possible to get such a complete data variable from the Brazilian school census and administrative data merging.
The student’ SES was calculated by applying the graded response model ( SAMEJIMA, 1997SAMEJIMA, F. Graded response model. In: LINDEN W. J. HAMBLETON, R. K. (eds.). Handbook of modern item response theory. New York: Springer, 1997. p. 85-100. ) to items of the student’s questionnaire, such as items regarding comfort goods (TV, automobile, computer, refrigerator, etc.), hiring of housekeeper and parents’ education (ALVES; SOARES; XAVIER, 2014).
Table 2 shows for each FU of the studied regions the number of observations and the percentage of missing values in SES and PR variables. As can be observed, the percentage of missing values in the northeast region is much higher than in the south. In the northeast the percentage of missing values for both variables are between 15 and 24.0% with the exception of the PR variable in the FU 23 (Ceará) that has just 8.6% of missing values. In the south, the missing percentage of both variables is between 3 and 7.0%. While in the northeast the percentage of missing values for SES variable is higher than for PR variable, with just one exception (FU = 24), in the south the opposite occurs. Here, the missing percentage for PR is always higher than the missing percentage in SES. It should be noted that if a student answered just to 3 or less items of a test, his performance was not calculated.
Descriptive statistics for SES variable of the studied data are presented in Table 3 . Considering that valid values of the SES variable are between 0 and 10, it can be observed that the mean and the median of SES variable have values below 50% of the full scale in the entire northeast region. On the contrary, in the entire south region the mean and median values for SES variable are greater than 5.5, i.e., in the second half of the scale.
Finally, descriptive statistics of PR variable are presented in Table 4 . The PR variable is standardised, and as can be observed, its mean and median values are negative in the northeast region, with the exception of Ceará. In the south region, the opposite occurs, mean and median are always positive.
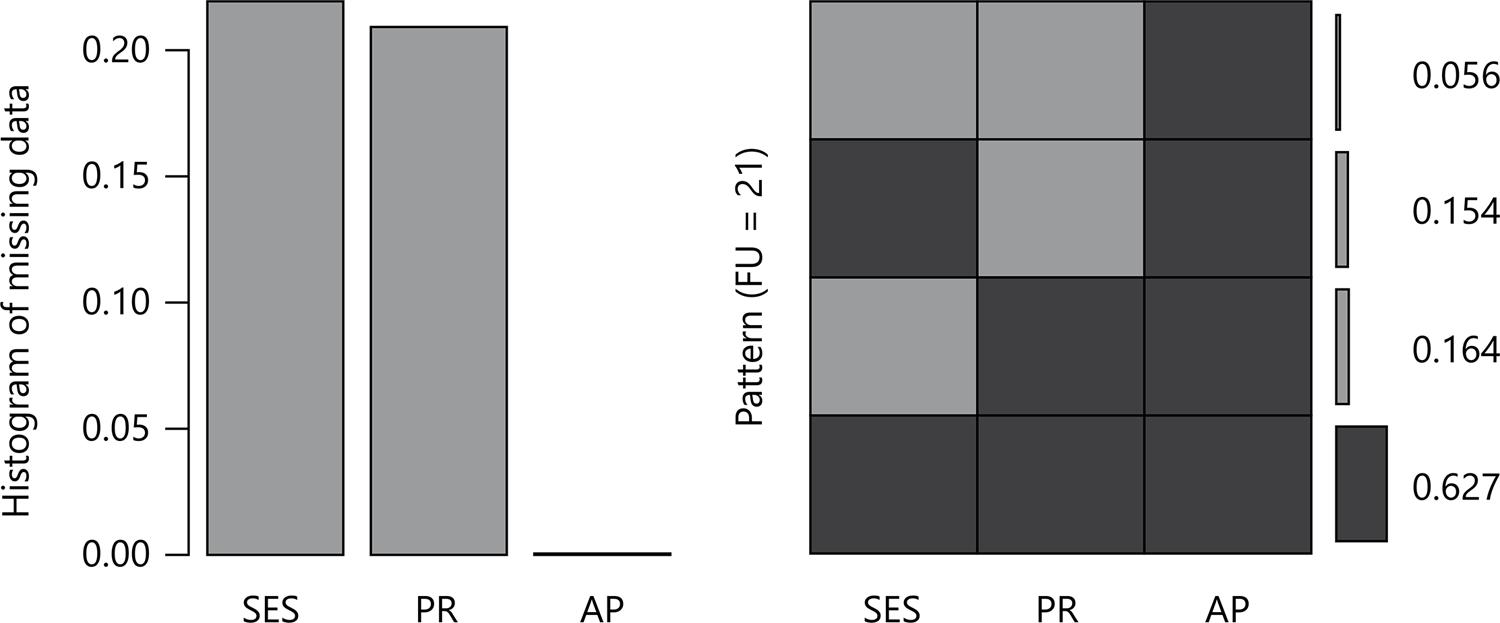
The datasets have four missing patterns, which are illustrated in Figure 1 for FU 21 (in the left hand side) and FU 43 (in the right hand side). For each FU the empirical distribution and the pattern of missing values are presented. As can be observed in both cases, the missing pattern with a small number of observations is the one with two missing variables.
3.2 MCAR test
As described in the literature ( FERRÃO; PRATA, 2019FERRÃO, M. E.; PRATA, P. Computing topics on multiple imputation in Big Identifiable Data using R: an application to educational research. In: MISRA, S. et al. (eds.). Computer science and its applications. [S. l.] Springer Cham, 2019. p. 12-24. (Lectures notes in computer science, v. 11621). ; IBRAHIM et al., 2005IBRAHIM, J. G. et al. Missing-data methods for generalized linear models: a comparative review. Journal of the American Statistical Association, [s. l.], v. 100, n. 469, p. 332-346, Dec.2005. https://doi.org/10.1198/016214504000001844
https://doi.org/10.1198/0162145040000018...
; VINHA; LAROS, 2018a), a common concern of every social and educational data scientist when he starts the analysis of multivariate data with missing values is checking if missing data are MCAR. We applied the test of hypothesis proposed by ( LITTLE, 1988LITTLE, R. J. A. A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, [s. l.], v. 83, n. 404, p. 1198-1202, Dec. 1988. https://doi.org/10.4018/IJACI.2019040105
https://doi.org/10.4018/IJACI.2019040105...
) and implemented in R.
For that purpose the function LittleMCAR from the BaylorEdPsych package was used. BaylorEdPsych is an R package for Baylor University Educational Psychology Quantitative Courses ( BEAUJEAN, 2015BEAUJEAN, A. A. R Package for Baylor University Educational Psychology quantitative courses. 2015 Fev. 19. Available from: <https://cran.r-project.org/web/packages/BaylorEdPsych/BaylorEdPsych.pdf. Access on: 2019 May 10.
https://cran.r-project.org/web/packages/...
) that uses Little’s test to assess for MCAR for multivariate data with missing values. It receives as argument a data frame or a data matrix with no more than 50 variables. Running the LittleMCAR function on every studied dataset we got a p-value of 0.0, conducting to the rejection of the null hypothesis, and concluding that the missingness pattern is not MCAR. The respective chi-square values, computed with 5 degrees of freedom, are presented in Table A1 in the annex.
3.3 Multiple Imputation
Multiple Imputation is a technique that involves creating m>1 multiple simulated values to replace each missing value. Then, each plausible version of the m complete datasets is analyzed as if it were a real complete dataset, by applying any standard statistical method. For a matter of inference, some authors (e.g. Ibrahim et al.) suggest obtaining one result by averaging over the m filled-in datasets; others (e.g. Peugh; Enders, 2004)PEUGH, J. L.; ENDERS, C. K. Missing data in educational research: a review of reporting practices and suggestions for improvement. Review of Educational Research, [s. l.], v. 74, n. 4, p. 525-–556, Dec. 2004. https://doi.org/10.3102/00346543074004525
https://doi.org/10.3102/0034654307400452...
suggest obtaining “A single estimand […] for any parameter by taking the arithmetic average of that parameter across the m analyses” (p. 550).
Concerning the UFs chosen, we used the package mi (Missing Data Imputation and Model Checking) to perform multiple imputation. That package imputes missing values in an approximate Bayesian framework ( GELMAN et al., 2015GELMAN, A. et al. Missing data imputation and model checking. 2015 Apr. 16. Available from: <https://cran.r-project.org/web/packages/mi/mi.pdf. Acess on: 2019 Feb. 11.
https://cran.r-project.org/web/packages/...
) generating multiple chains of values with a pre-defined number of iterations.
Before the imputation procedure, the dataset must be converted into a missing_data.frame object. That object will include metadata describing the variables with missing values and how they relate to each other. Variables are characterized with a type and a family. Figure 2 shows, as an example, the classification assigned to the dataset from the FU 21. As can be seen, the imputation method that will be used is the posterior predictive distribution (ppd). The classification and imputation method can be modified with a change function, according to the knowledge the user has about the data.
After analyzing the missing_data.frame, the imputation process can be done, calling the mi function. We choose to run 5 chains (m = 5) performing 35 iterations each. At the end, convergence between chains must be checked using the Rhats function. If the chains have not converged, the iterative process should continue using a second mi function that receives the result of the first call and the number of additional iterations. Finally, the imputation data can be collected using the mi2stata function. It allows exporting the data of all the chains to Stata (.dta) or comma separated (.csv) format.
Next section presents descriptive results (Tables 5 and 6), the m = 5 estimates for each set of regression model parameters in Table A2 in the annex, and in Table 7 the average of such estimates and standard errors, following Peugh and Enders (2004PEUGH, J. L.; ENDERS, C. K. Missing data in educational research: a review of reporting practices and suggestions for improvement. Review of Educational Research, [s. l.], v. 74, n. 4, p. 525-–556, Dec. 2004. https://doi.org/10.3102/00346543074004525
https://doi.org/10.3102/0034654307400452...
, p. 550–551). The MI standard error (SE) estimated for each regression coefficient is given by equation (1), denoted by √T, and combines the within-imputation variance and the between-imputation variance,
where U̅ is the within-imputation variance and B is the between-imputation variance. Table A3 in the annex contains the standard error estimates for each chain.
4 Results
Descriptive statistics of the imputed values, for each data set, are shown in tables 5 and 6. As example, we chose the results of chain 1. Table 5 presents the statistics by FU for the SES variable and table 6 for the PR variable.
Comparing results of descriptive statistics when considering listwise deletion (Tables 3 and 4) with multiple imputation (Tables 5 and 6) can be observed that for both variables, SES and PR, the maximum difference between the median values is always smaller than or equal to 0.06. Comparing the mean values, the maximum difference is 0.05 with just one exception. In FU = 22 the mean difference is 0.245.
Table 7 presents the linear regression coefficient estimates and respective standard errors for MCAR assumption and MI, allowing the comparison between the results obtained. Considering the FU 21, the results suggest that a unit increase in SES, the PR expected value should result in 0.115 increase in PR scores, holding auxiliary variable constant. The relationship between SES and PR has in general the same estimate in both approaches. When this does not happen, the absolute difference is 0.002 maximum.
The intercept estimates are in general different, but such difference is not statistically significant at the level of significance of 5%. The capacity of explanation of MI is in general greater than MCAR since the R estimate is larger in MI based model.
5 Discussion
Despite the existence of various studies regarding the treatment of missing data and the relevant progress that has been made in the topic during the last 30 years ( LITTLE, 1988LITTLE, R. J. A. A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, [s. l.], v. 83, n. 404, p. 1198-1202, Dec. 1988. https://doi.org/10.4018/IJACI.2019040105
https://doi.org/10.4018/IJACI.2019040105...
), social researchers still tend to use traditional methods such as listwise or pairwise deletion and mean imputation instead of ML or MI methods ( WILKINSON; APA BOARD OF SCIENTIFIC AFFAIRS, 1999WILKINSON, L.; APA BOARD OF SCIENTIFIC AFFAIRS. Statistical methods in Psychology journals. American Psychologist, Washington, v. 54, n. 8, p. 594-604, Aug. 1999. Available from: <https://www.apa.org/
https://www.apa.org/...
; VINHA; LAROS, 2018b). Thus, one of the goals of this paper is to provide information about checking the missingness pattern and the MI missing-data procedures to social scientists prone to use open access software. Second, we show the impact of assuming MCAR or running MI on the linear relationship between student’s performance and student’s socioeconomic status by applying both approaches to the big identifiable data Prova Brasil 2017 (regions Northeast and South), and by considering, as auxiliary variable, the student grade repetition information collected by the educational census. We applied to real-world data the same R software procedures described by Ferrão and Prata (2019)FERRÃO, M. E.; PRATA, P. Computing topics on multiple imputation in Big Identifiable Data using R: an application to educational research. In: MISRA, S. et al. (eds.). Computer science and its applications. [S. l.] Springer Cham, 2019. p. 12-24. (Lectures notes in computer science, v. 11621). with simulated data. The results obtained suggest the rejection of MCAR. The relationship between SES and PR has in general the same estimate either assuming MCAR or with complete data resulting from MI. When this does not happen, the absolute difference is 0.002 maximum. Concerning the PR expected value, the results show that the assumption MCAR conducts to a bias towards zero. These results are in line with those reported by Vinha and Laros (2018), who mention that “the listwise deletion results are similar to the results obtained by applying more sophisticated methods, when the auxiliary variables are not included in the model” (p. 184).
In educational and evaluation research, the relationship between SES and PR is central. Our results demonstrate that the majority of the cumulative knowledge on the topic of social equity and related themes, should not be severely compromised if it had been based on naïve assumptions of missing data. However, this cannot be generally adopted as a “rule of dumb” by the researcher. Our results reinforce the recommendation given by the APA Board of Scientific Affairs, according to which the researcher should “Describe methods used to attenuate sources of bias, including plans for minimizing dropouts, noncompliance, and missing data” ( WILKINSON; APA BOARD OF SCIENTIFIC AFFAIRS, 1999WILKINSON, L.; APA BOARD OF SCIENTIFIC AFFAIRS. Statistical methods in Psychology journals. American Psychologist, Washington, v. 54, n. 8, p. 594-604, Aug. 1999. Available from: <https://www.apa.org/
https://www.apa.org/...
, p. 595).
Annex
References
- ALVES, M. T. G.; SOARES, J. F.; XAVIER, F. P. Índice socioeconômico das escolas de educação básica brasileiras. Ensaio: Avaliação e Políticas Públicas em Educação, Rio de Janeiro, v. 22, n. 84, p. 671-703, set. 2014. https://doi.org/10.1590/S0104-40362014000300005
» https://doi.org/10.1590/S0104-40362014000300005 - BARTHOLO, T. L.; COSTA, M. Evidence of a school composition effect in Rio de Janeiro public schools. Ensaio: Avaliação e Políticas Públicas em Educação, Rio de Janeiro, v. 24, n. 92, p. 498-521, set. 2016. https://doi.org/10.1590/S0104-40362016000300001
» https://doi.org/10.1590/S0104-40362016000300001 - BEAUJEAN, A. A. R Package for Baylor University Educational Psychology quantitative courses. 2015 Fev. 19. Available from: <https://cran.r-project.org/web/packages/BaylorEdPsych/BaylorEdPsych.pdf Access on: 2019 May 10.
» https://cran.r-project.org/web/packages/BaylorEdPsych/BaylorEdPsych.pdf - COX, B. E. et al. Working with missing data in Higher Education research: a primer and real-world example. The Review of Higher Education, Baltimore, v. 37, n. 3, p. 377-402, Spring 2014. https://doi.org/10.1353/rhe.2014.0026
» https://doi.org/10.1353/rhe.2014.0026 - DIGGLE, P. J. Statistics: a data science for the 21st century. Journal of the Royal Statistical Society Series A, London, v. 178, n. 4, p. 793-813, Sep. 2015. https://doi.org/10.1111/rssa.12132
» https://doi.org/10.1111/rssa.12132 - FERRÃO, M. E.; PRATA, P. Computing topics on multiple imputation in Big Identifiable Data using R: an application to educational research. In: MISRA, S. et al. (eds.). Computer science and its applications. [S. l.] Springer Cham, 2019. p. 12-24. (Lectures notes in computer science, v. 11621).
- FOLEY, B.; GOLDSTEIN, H. Measuring success: league tables in the public sector. London: British Academy, 2012.
- FONSECA, S. O.; NAMEN, A. A. Mineração em bases de dados do Inep: uma análise exploratória para nortear melhorias no sistema educacional brasileiro. Educação em Revista, Belo Horizonte, v. 32, n. 1, p. 133-157, jan./mar. 2016. https://doi.org/10.1590/0102-4698140742
» https://doi.org/10.1590/0102-4698140742 - GELMAN, A. et al. Missing data imputation and model checking. 2015 Apr. 16. Available from: <https://cran.r-project.org/web/packages/mi/mi.pdf Acess on: 2019 Feb. 11.
» https://cran.r-project.org/web/packages/mi/mi.pdf - IBRAHIM, J. G. et al. Missing-data methods for generalized linear models: a comparative review. Journal of the American Statistical Association, [s. l.], v. 100, n. 469, p. 332-346, Dec.2005. https://doi.org/10.1198/016214504000001844
» https://doi.org/10.1198/016214504000001844 - INSTITUTO NACIONAL DE ESTUDOS E PESQUISAS EDUCACIONAIS ANÍSIO TEIXEIRA - Inep. Rio de Janeiro, 2020. Available from: <http://portal.inep.gov.br/web/guest/educacao-basica Access in: 2020 Jan.15.
» http://portal.inep.gov.br/web/guest/educacao-basica - KLEIN, R. Utilização da teoria de resposta ao item no Sistema Nacional de Avaliação da Educação Básica (Saeb). Ensaio: Avaliação e Políticas Públicas em Educação, Rio de Janeiro, v. 11, n. 40, p. 283-296, jan./mar. 2003.
- LAVANYA, K.; REDDY, L. S. S.; REDDY, B. E. Distributed based serial regression multiple imputation for high dimensional multivariate data in multicore environment of cloud. International Journal of Ambient Computing and Intelligence, [s. l.], v. 10, n. 2, p. 63-79, Apr. 2019. https://doi.org/10.4018/IJACI.2019040105
» https://doi.org/10.4018/IJACI.2019040105 - LITTLE, R. J. A. A test of missing completely at random for multivariate data with missing values. Journal of the American Statistical Association, [s. l.], v. 83, n. 404, p. 1198-1202, Dec. 1988. https://doi.org/10.4018/IJACI.2019040105
» https://doi.org/10.4018/IJACI.2019040105 - MORGANSTEIN, D.; WASSERSTEIN, R. ASA statement on value-added models. Statistics and Public Policy, Philadelphia, v. 1, n. 1, p. 108-110, Nov. 2014. https://doi.org/10.1080/2330443X.2014.956906
» https://doi.org/10.1080/2330443X.2014.956906 - OLIVEIRA, A. C. P.; CARVALHO, C. P. Public school management, leadership, and educational results in Brazil. Revista Brasileira de Educação, Rio de Janeiro, v. 23, n. e230015, 2018. https://doi.org/10.1590/s1413-24782018230015
» https://doi.org/10.1590/s1413-24782018230015 - PAMPAKA, M.; HUTCHESON, G.; WILLIAMS, J. Handling missing data: Analysis of a challenging data set using multiple imputation. International Journal of Research & Method in Education, [s. l.], v. 39, n. 1, p. 19-37, 2016. https://doi.org/10.1080/1743727X.2014.979146
» https://doi.org/10.1080/1743727X.2014.979146 - PEUGH, J. L.; ENDERS, C. K. Missing data in educational research: a review of reporting practices and suggestions for improvement. Review of Educational Research, [s. l.], v. 74, n. 4, p. 525-–556, Dec. 2004. https://doi.org/10.3102/00346543074004525
» https://doi.org/10.3102/00346543074004525 - PONTES, L. A. F.; SOARES, T. M. Volatilidade dos resultados de proficiências e seu impacto sobre as metas do IDEB nas escolas públicas de Minas Gerais. Educação em Revista, Belo Horizonte, v. 33, n. e153262, 2017. https://doi.org/10.1590/0102-4698153262
» https://doi.org/10.1590/0102-4698153262 - RUBIN, D. B. Multiple imputation for nonresponse in surveys. New York: Wiley, 1987.
- SAMEJIMA, F. Graded response model. In: LINDEN W. J. HAMBLETON, R. K. (eds.). Handbook of modern item response theory. New York: Springer, 1997. p. 85-100.
- SCHLOMER, G. L.; BAUMAN, S.; CARD, N. A. Best practices for missing data management in counseling psychology. Journal of Counseling Psychology, v. 57, n. 1, p. 1-10, Jan. 2010. https://doi.org/10.1037/a0018082
» https://doi.org/10.1037/a0018082 - SHLOMO, N.; GOLDSTEIN, H. Editorial: Big data in social research. Journal of the Royal Statistical Society Series A, London, v. 178, n. 4, p. 787-790, Sep. 2015. https://doi.org/10.1111/rssa.12144
» https://doi.org/10.1111/rssa.12144 - SOCIEDADE PORTUGUESA DE ESTATÍSTICA; ASSOCIAÇÃO BRASILEIRA DE ESTATÍSTICA. Glossário inglês-português de estatística. 2011. Available from: <http://glossario.spestatistica.pt/ Access on: 2020 Jan. 15.
» http://glossario.spestatistica.pt/ - VINHA, L. G. A.; LAROS, J. A. Dados ausentes em avaliações educacionais: comparação de métodos de tratamento. Estudos em Avaliação Educacional, São Paulo, v. 29, n. 70, p. 156-187, jan./abr. 2018a. http://dx.doi.org/10.18222/eae.v0ix.3916
» http://dx.doi.org/10.18222/eae.v0ix.3916 - WELLS, R. S. et al. “How we know what we know”: a systematic comparison of research methods employed in higher education. Journal of Higher Education, London, v. 86, n. 2, p. 171-195, 2015. https://doi.org/10.1080/00221546.2015.11777361
» https://doi.org/10.1080/00221546.2015.11777361 - WILKINSON, L.; APA BOARD OF SCIENTIFIC AFFAIRS. Statistical methods in Psychology journals. American Psychologist, Washington, v. 54, n. 8, p. 594-604, Aug. 1999. Available from: <https://www.apa.org/
» https://www.apa.org/
-
*
This project was partially funded by Fundação para a Ciência e a Tecnologia (FCT) through project number Cemapre – UID/MULTI/00491/2019 and project number UIDB/EEA/50008/2020. Also funded by operation Centro-01-0145-FEDER-000019-C4- Centro de Competências em Cloud Computing and by the Brazilian Coordination for the Improvement of Higher Education Personnel Foundation, through a post-doc fellowship for a research project, which took place at the Faculty of Sciences of the University of Beira Interior, Portugal (Capes-PVE88881.169888/2018-01), and partially supported by the Brazilian National Council for Scientific and Technological Development (CNPq-process 440172 / 2017-9).
Publication Dates
-
Publication in this collection
08 May 2020 -
Date of issue
Jul-Sep 2020
History
-
Received
26 May 2019 -
Accepted
24 Feb 2020

 Source: own calculation (2019)
Source: own calculation (2019)
 Source: own calculation (2019)
Source: own calculation (2019)